 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOne-Trimap Video Matting
Paper and Code
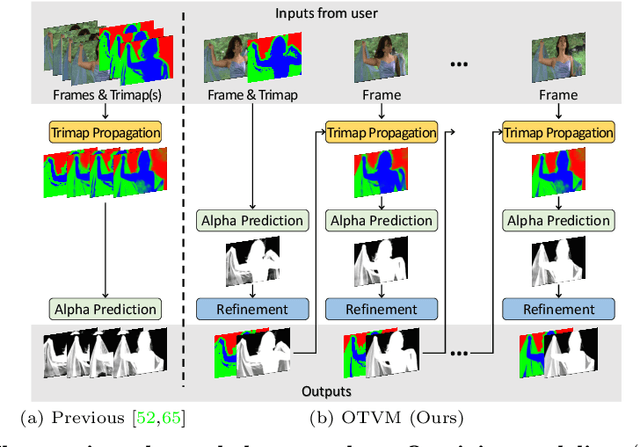
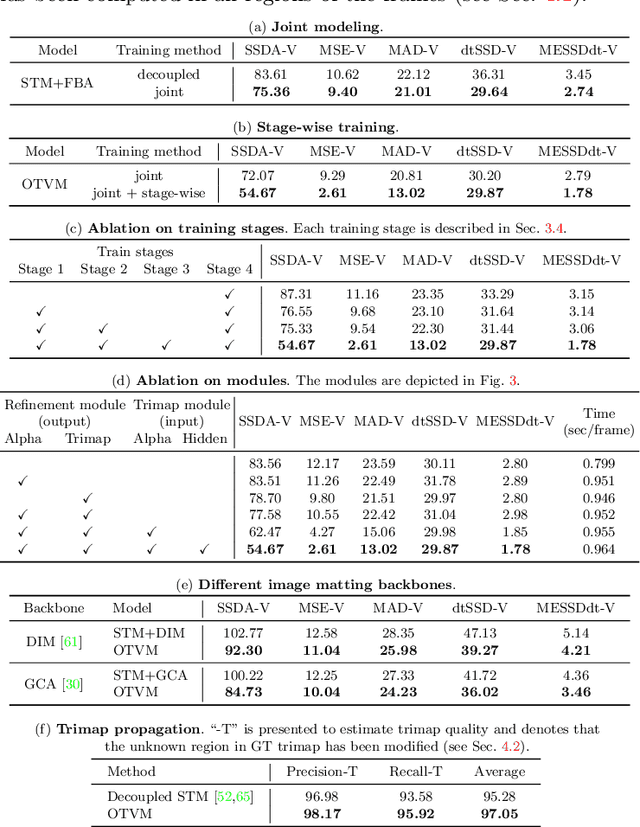
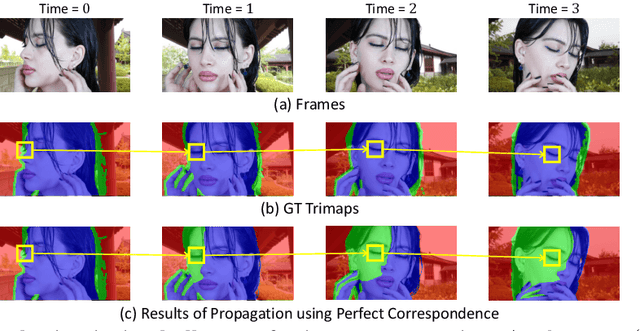
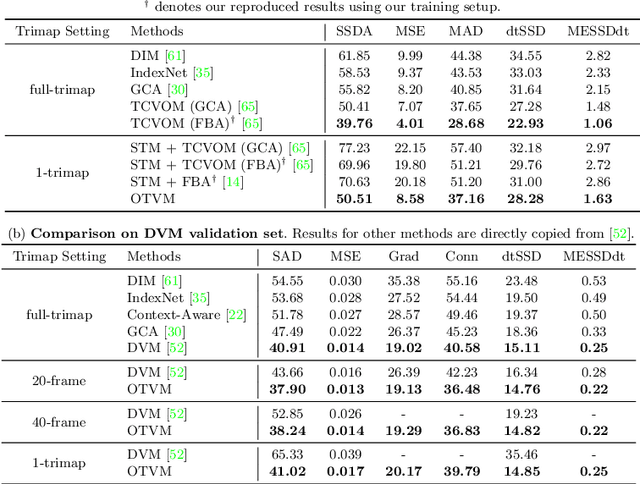
Recent studies made great progress in video matting by extending the success of trimap-based image matting to the video domain. In this paper, we push this task toward a more practical setting and propose One-Trimap Video Matting network (OTVM) that performs video matting robustly using only one user-annotated trimap. A key of OTVM is the joint modeling of trimap propagation and alpha prediction. Starting from baseline trimap propagation and alpha prediction networks, our OTVM combines the two networks with an alpha-trimap refinement module to facilitate information flow. We also present an end-to-end training strategy to take full advantage of the joint model. Our joint modeling greatly improves the temporal stability of trimap propagation compared to the previous decoupled methods. We evaluate our model on two latest video matting benchmarks, Deep Video Matting and VideoMatting108, and outperform state-of-the-art by significant margins (MSE improvements of 56.4% and 56.7%, respectively). The source code and model are available online: https://github.com/Hongje/OTVM.