 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReconstruction Using the Invisible: Intuition from NIR and Metadata for Enhanced 3D Gaussian Splatting
Aug 20, 2025
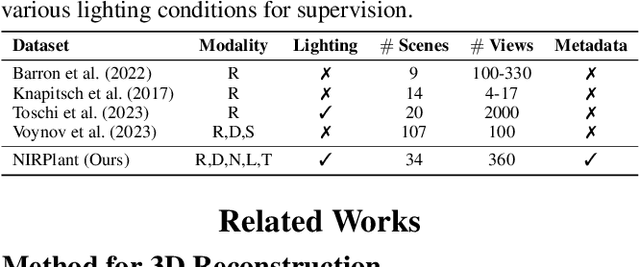


While 3D Gaussian Splatting (3DGS) has rapidly advanced, its application in agriculture remains underexplored. Agricultural scenes present unique challenges for 3D reconstruction methods, particularly due to uneven illumination, occlusions, and a limited field of view. To address these limitations, we introduce \textbf{NIRPlant}, a novel multimodal dataset encompassing Near-Infrared (NIR) imagery, RGB imagery, textual metadata, Depth, and LiDAR data collected under varied indoor and outdoor lighting conditions. By integrating NIR data, our approach enhances robustness and provides crucial botanical insights that extend beyond the visible spectrum. Additionally, we leverage text-based metadata derived from vegetation indices, such as NDVI, NDWI, and the chlorophyll index, which significantly enriches the contextual understanding of complex agricultural environments. To fully exploit these modalities, we propose \textbf{NIRSplat}, an effective multimodal Gaussian splatting architecture employing a cross-attention mechanism combined with 3D point-based positional encoding, providing robust geometric priors. Comprehensive experiments demonstrate that \textbf{NIRSplat} outperforms existing landmark methods, including 3DGS, CoR-GS, and InstantSplat, highlighting its effectiveness in challenging agricultural scenarios. The code and dataset are publicly available at: https://github.com/StructuresComp/3D-Reconstruction-NIR
Unified Domain Generalization and Adaptation for Multi-View 3D Object Detection
Oct 29, 2024



Recent advances in 3D object detection leveraging multi-view cameras have demonstrated their practical and economical value in various challenging vision tasks. However, typical supervised learning approaches face challenges in achieving satisfactory adaptation toward unseen and unlabeled target datasets (\ie, direct transfer) due to the inevitable geometric misalignment between the source and target domains. In practice, we also encounter constraints on resources for training models and collecting annotations for the successful deployment of 3D object detectors. In this paper, we propose Unified Domain Generalization and Adaptation (UDGA), a practical solution to mitigate those drawbacks. We first propose Multi-view Overlap Depth Constraint that leverages the strong association between multi-view, significantly alleviating geometric gaps due to perspective view changes. Then, we present a Label-Efficient Domain Adaptation approach to handle unfamiliar targets with significantly fewer amounts of labels (\ie, 1$\%$ and 5$\%)$, while preserving well-defined source knowledge for training efficiency. Overall, UDGA framework enables stable detection performance in both source and target domains, effectively bridging inevitable domain gaps, while demanding fewer annotations. We demonstrate the robustness of UDGA with large-scale benchmarks: nuScenes, Lyft, and Waymo, where our framework outperforms the current state-of-the-art methods.
CMDA: Cross-Modal and Domain Adversarial Adaptation for LiDAR-Based 3D Object Detection
Mar 07, 2024Recent LiDAR-based 3D Object Detection (3DOD) methods show promising results, but they often do not generalize well to target domains outside the source (or training) data distribution. To reduce such domain gaps and thus to make 3DOD models more generalizable, we introduce a novel unsupervised domain adaptation (UDA) method, called CMDA, which (i) leverages visual semantic cues from an image modality (i.e., camera images) as an effective semantic bridge to close the domain gap in the cross-modal Bird's Eye View (BEV) representations. Further, (ii) we also introduce a self-training-based learning strategy, wherein a model is adversarially trained to generate domain-invariant features, which disrupt the discrimination of whether a feature instance comes from a source or an unseen target domain. Overall, our CMDA framework guides the 3DOD model to generate highly informative and domain-adaptive features for novel data distributions. In our extensive experiments with large-scale benchmarks, such as nuScenes, Waymo, and KITTI, those mentioned above provide significant performance gains for UDA tasks, achieving state-of-the-art performance.
ORA3D: Overlap Region Aware Multi-view 3D Object Detection
Jul 02, 2022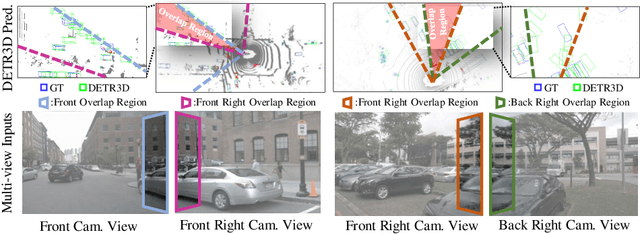
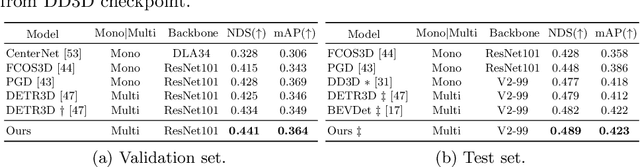
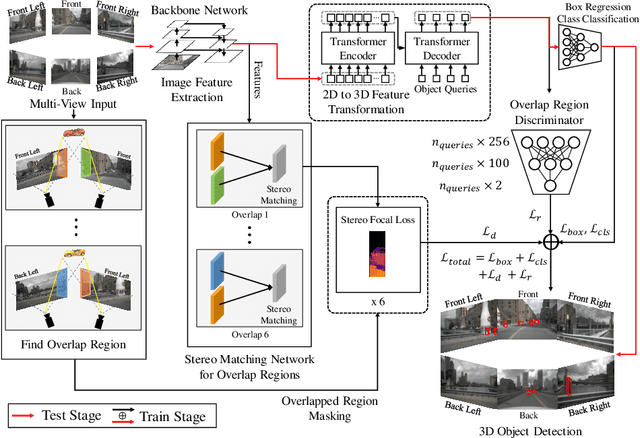

In multi-view 3D object detection tasks, disparity supervision over overlapping image regions substantially improves the overall detection performance. However, current multi-view 3D object detection methods often fail to detect objects in the overlap region properly, and the network's understanding of the scene is often limited to that of a monocular detection network. To mitigate this issue, we advocate for applying the traditional stereo disparity estimation method to obtain reliable disparity information for the overlap region. Given the disparity estimates as a supervision, we propose to regularize the network to fully utilize the geometric potential of binocular images, and improve the overall detection accuracy. Moreover, we propose to use an adversarial overlap region discriminator, which is trained to minimize the representational gap between non-overlap regions and overlapping regions where objects are often largely occluded or suffer from deformation due to camera distortion, causing a domain shift. We demonstrate the effectiveness of the proposed method with the large-scale multi-view 3D object detection benchmark, called nuScenes. Our experiment shows that our proposed method outperforms the current state-of-the-art methods.