 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeALIGN: Advanced Query Initialization with LiDAR-Image Guidance for Occlusion-Robust 3D Object Detection
Dec 20, 2025

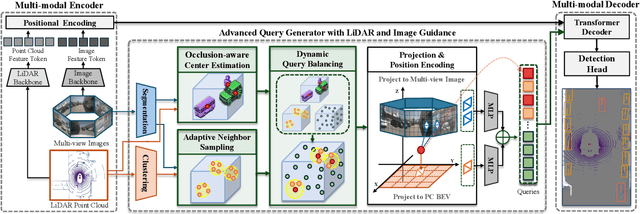

Recent query-based 3D object detection methods using camera and LiDAR inputs have shown strong performance, but existing query initialization strategies,such as random sampling or BEV heatmap-based sampling, often result in inefficient query usage and reduced accuracy, particularly for occluded or crowded objects. To address this limitation, we propose ALIGN (Advanced query initialization with LiDAR and Image GuidaNce), a novel approach for occlusion-robust, object-aware query initialization. Our model consists of three key components: (i) Occlusion-aware Center Estimation (OCE), which integrates LiDAR geometry and image semantics to estimate object centers accurately (ii) Adaptive Neighbor Sampling (ANS), which generates object candidates from LiDAR clustering and supplements each object by sampling spatially and semantically aligned points around it and (iii) Dynamic Query Balancing (DQB), which adaptively balances queries between foreground and background regions. Our extensive experiments on the nuScenes benchmark demonstrate that ALIGN consistently improves performance across multiple state-of-the-art detectors, achieving gains of up to +0.9 mAP and +1.2 NDS, particularly in challenging scenes with occlusions or dense crowds. Our code will be publicly available upon publication.
Mitigating Trade-off: Stream and Query-guided Aggregation for Efficient and Effective 3D Occupancy Prediction
Mar 28, 2025



3D occupancy prediction has emerged as a key perception task for autonomous driving, as it reconstructs 3D environments to provide a comprehensive scene understanding. Recent studies focus on integrating spatiotemporal information obtained from past observations to improve prediction accuracy, using a multi-frame fusion approach that processes multiple past frames together. However, these methods struggle with a trade-off between efficiency and accuracy, which significantly limits their practicality. To mitigate this trade-off, we propose StreamOcc, a novel framework that aggregates spatio-temporal information in a stream-based manner. StreamOcc consists of two key components: (i) Stream-based Voxel Aggregation, which effectively accumulates past observations while minimizing computational costs, and (ii) Query-guided Aggregation, which recurrently aggregates instance-level features of dynamic objects into corresponding voxel features, refining fine-grained details of dynamic objects. Experiments on the Occ3D-nuScenes dataset show that StreamOcc achieves state-of-the-art performance in real-time settings, while reducing memory usage by more than 50% compared to previous methods.
VisionTrap: Vision-Augmented Trajectory Prediction Guided by Textual Descriptions
Jul 17, 2024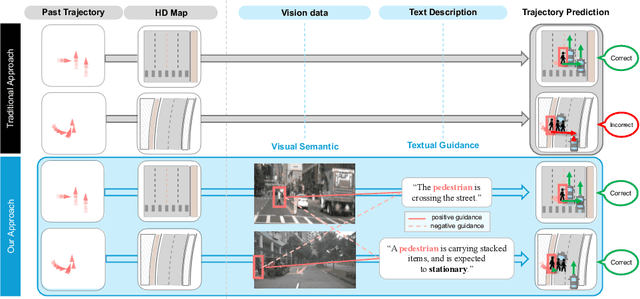
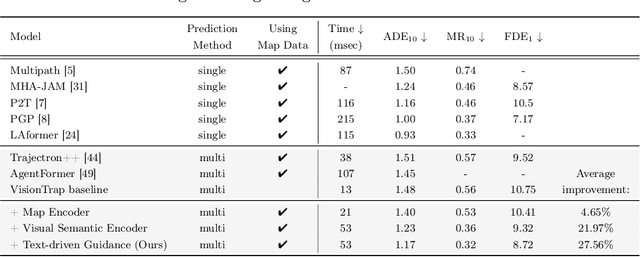

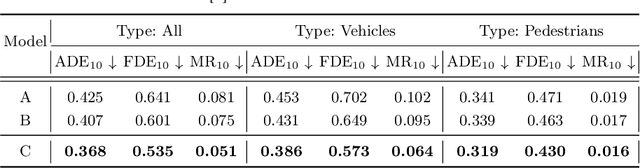
Predicting future trajectories for other road agents is an essential task for autonomous vehicles. Established trajectory prediction methods primarily use agent tracks generated by a detection and tracking system and HD map as inputs. In this work, we propose a novel method that also incorporates visual input from surround-view cameras, allowing the model to utilize visual cues such as human gazes and gestures, road conditions, vehicle turn signals, etc, which are typically hidden from the model in prior methods. Furthermore, we use textual descriptions generated by a Vision-Language Model (VLM) and refined by a Large Language Model (LLM) as supervision during training to guide the model on what to learn from the input data. Despite using these extra inputs, our method achieves a latency of 53 ms, making it feasible for real-time processing, which is significantly faster than that of previous single-agent prediction methods with similar performance. Our experiments show that both the visual inputs and the textual descriptions contribute to improvements in trajectory prediction performance, and our qualitative analysis highlights how the model is able to exploit these additional inputs. Lastly, in this work we create and release the nuScenes-Text dataset, which augments the established nuScenes dataset with rich textual annotations for every scene, demonstrating the positive impact of utilizing VLM on trajectory prediction. Our project page is at https://moonseokha.github.io/VisionTrap/
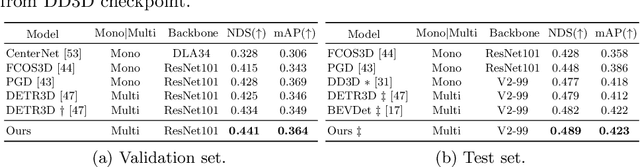
Learning Temporal Cues by Predicting Objects Move for Multi-camera 3D Object Detection
Apr 02, 2024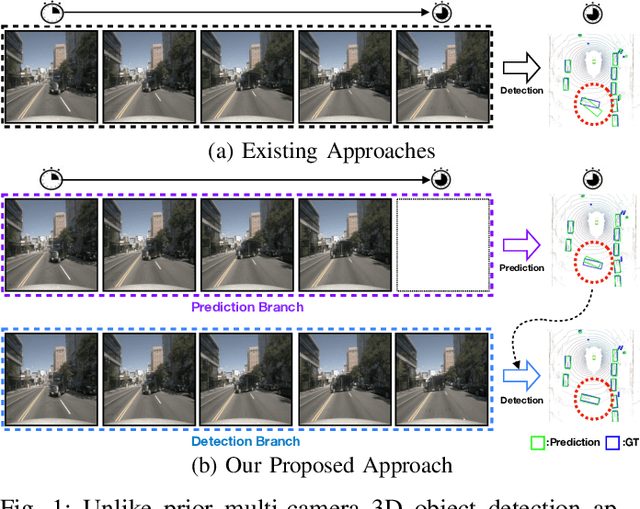


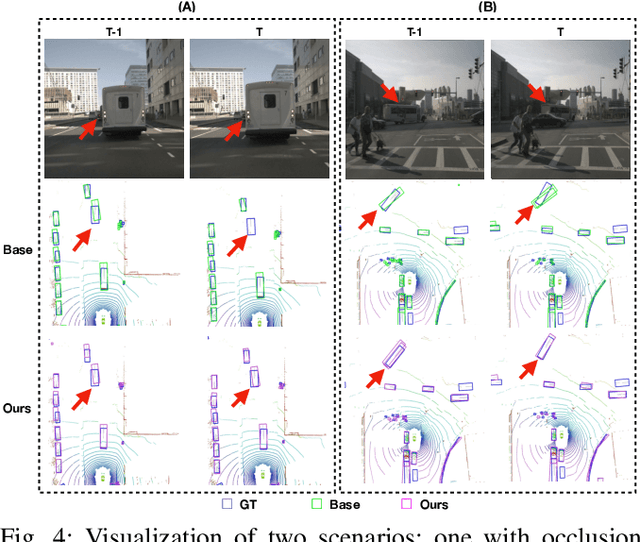
In autonomous driving and robotics, there is a growing interest in utilizing short-term historical data to enhance multi-camera 3D object detection, leveraging the continuous and correlated nature of input video streams. Recent work has focused on spatially aligning BEV-based features over timesteps. However, this is often limited as its gain does not scale well with long-term past observations. To address this, we advocate for supervising a model to predict objects' poses given past observations, thus explicitly guiding to learn objects' temporal cues. To this end, we propose a model called DAP (Detection After Prediction), consisting of a two-branch network: (i) a branch responsible for forecasting the current objects' poses given past observations and (ii) another branch that detects objects based on the current and past observations. The features predicting the current objects from branch (i) is fused into branch (ii) to transfer predictive knowledge. We conduct extensive experiments with the large-scale nuScenes datasets, and we observe that utilizing such predictive information significantly improves the overall detection performance. Our model can be used plug-and-play, showing consistent performance gain.
ORA3D: Overlap Region Aware Multi-view 3D Object Detection
Jul 02, 2022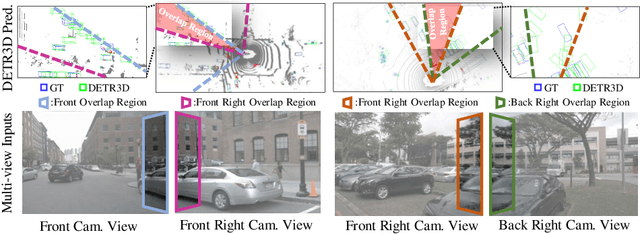
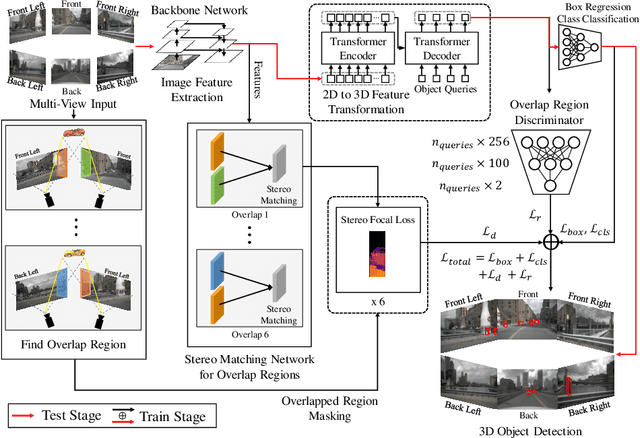

In multi-view 3D object detection tasks, disparity supervision over overlapping image regions substantially improves the overall detection performance. However, current multi-view 3D object detection methods often fail to detect objects in the overlap region properly, and the network's understanding of the scene is often limited to that of a monocular detection network. To mitigate this issue, we advocate for applying the traditional stereo disparity estimation method to obtain reliable disparity information for the overlap region. Given the disparity estimates as a supervision, we propose to regularize the network to fully utilize the geometric potential of binocular images, and improve the overall detection accuracy. Moreover, we propose to use an adversarial overlap region discriminator, which is trained to minimize the representational gap between non-overlap regions and overlapping regions where objects are often largely occluded or suffer from deformation due to camera distortion, causing a domain shift. We demonstrate the effectiveness of the proposed method with the large-scale multi-view 3D object detection benchmark, called nuScenes. Our experiment shows that our proposed method outperforms the current state-of-the-art methods.