 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Temporal Cues by Predicting Objects Move for Multi-camera 3D Object Detection
Paper and Code
Apr 02, 2024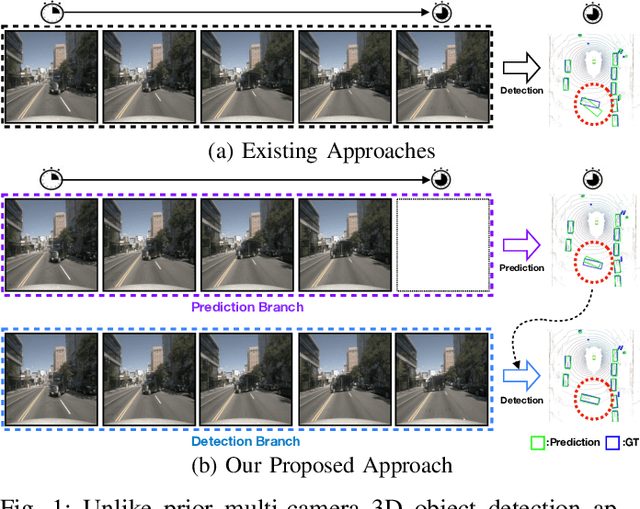


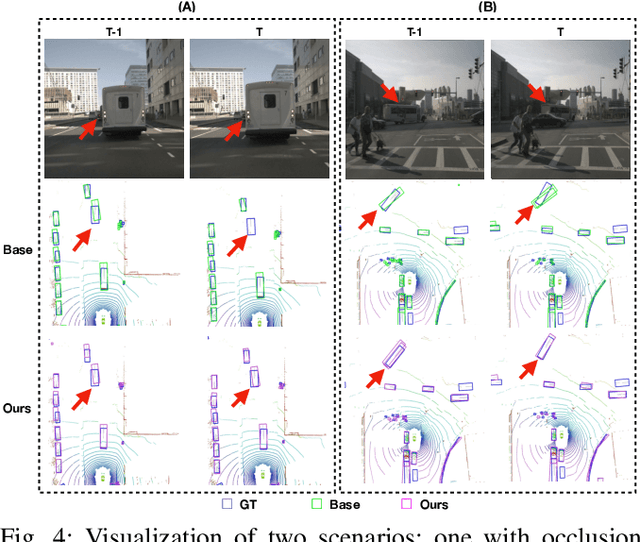
In autonomous driving and robotics, there is a growing interest in utilizing short-term historical data to enhance multi-camera 3D object detection, leveraging the continuous and correlated nature of input video streams. Recent work has focused on spatially aligning BEV-based features over timesteps. However, this is often limited as its gain does not scale well with long-term past observations. To address this, we advocate for supervising a model to predict objects' poses given past observations, thus explicitly guiding to learn objects' temporal cues. To this end, we propose a model called DAP (Detection After Prediction), consisting of a two-branch network: (i) a branch responsible for forecasting the current objects' poses given past observations and (ii) another branch that detects objects based on the current and past observations. The features predicting the current objects from branch (i) is fused into branch (ii) to transfer predictive knowledge. We conduct extensive experiments with the large-scale nuScenes datasets, and we observe that utilizing such predictive information significantly improves the overall detection performance. Our model can be used plug-and-play, showing consistent performance gain.