 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSAMIRO: Spatial Attention Mutual Information Regularization with a Pre-trained Model as Oracle for Lane Detection
Nov 13, 2025



Lane detection is an important topic in the future mobility solutions. Real-world environmental challenges such as background clutter, varying illumination, and occlusions pose significant obstacles to effective lane detection, particularly when relying on data-driven approaches that require substantial effort and cost for data collection and annotation. To address these issues, lane detection methods must leverage contextual and global information from surrounding lanes and objects. In this paper, we propose a Spatial Attention Mutual Information Regularization with a pre-trained model as an Oracle, called SAMIRO. SAMIRO enhances lane detection performance by transferring knowledge from a pretrained model while preserving domain-agnostic spatial information. Leveraging SAMIRO's plug-and-play characteristic, we integrate it into various state-of-the-art lane detection approaches and conduct extensive experiments on major benchmarks such as CULane, Tusimple, and LLAMAS. The results demonstrate that SAMIRO consistently improves performance across different models and datasets. The code will be made available upon publication.
Leveraging Text-Driven Semantic Variation for Robust OOD Segmentation
Nov 10, 2025In autonomous driving and robotics, ensuring road safety and reliable decision-making critically depends on out-of-distribution (OOD) segmentation. While numerous methods have been proposed to detect anomalous objects on the road, leveraging the vision-language space-which provides rich linguistic knowledge-remains an underexplored field. We hypothesize that incorporating these linguistic cues can be especially beneficial in the complex contexts found in real-world autonomous driving scenarios. To this end, we present a novel approach that trains a Text-Driven OOD Segmentation model to learn a semantically diverse set of objects in the vision-language space. Concretely, our approach combines a vision-language model's encoder with a transformer decoder, employs Distance-Based OOD prompts located at varying semantic distances from in-distribution (ID) classes, and utilizes OOD Semantic Augmentation for OOD representations. By aligning visual and textual information, our approach effectively generalizes to unseen objects and provides robust OOD segmentation in diverse driving environments. We conduct extensive experiments on publicly available OOD segmentation datasets such as Fishyscapes, Segment-Me-If-You-Can, and Road Anomaly datasets, demonstrating that our approach achieves state-of-the-art performance across both pixel-level and object-level evaluations. This result underscores the potential of vision-language-based OOD segmentation to bolster the safety and reliability of future autonomous driving systems.
GUIDE-CoT: Goal-driven and User-Informed Dynamic Estimation for Pedestrian Trajectory using Chain-of-Thought
Mar 10, 2025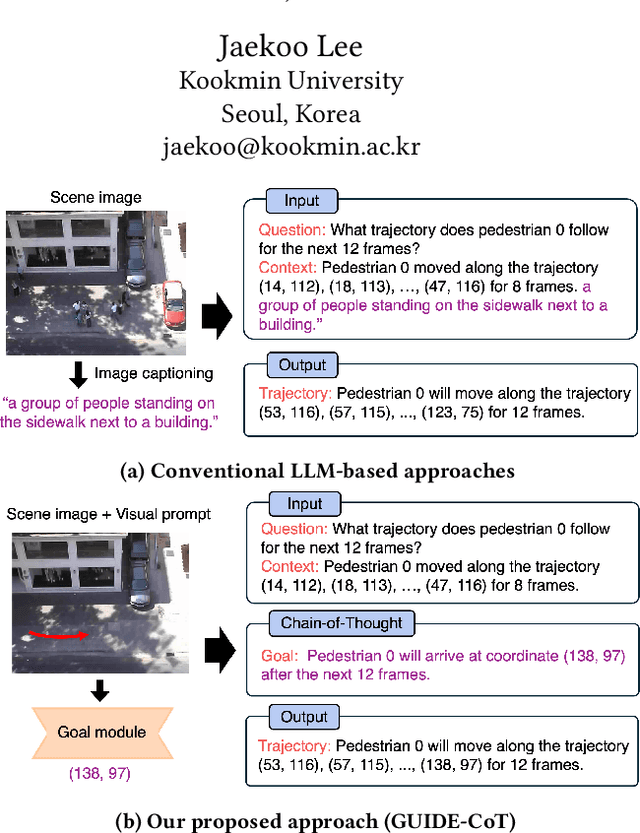

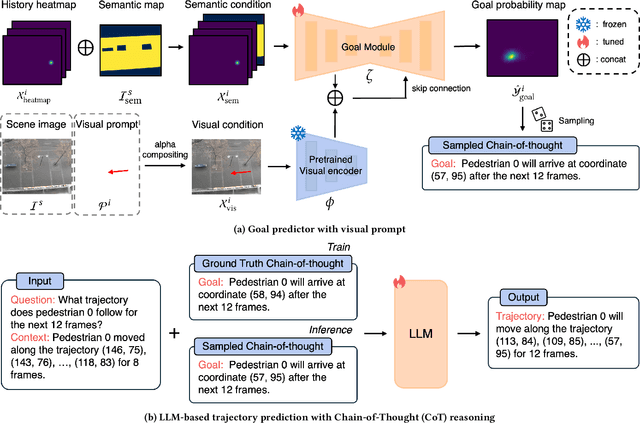

While Large Language Models (LLMs) have recently shown impressive results in reasoning tasks, their application to pedestrian trajectory prediction remains challenging due to two key limitations: insufficient use of visual information and the difficulty of predicting entire trajectories. To address these challenges, we propose Goal-driven and User-Informed Dynamic Estimation for pedestrian trajectory using Chain-of-Thought (GUIDE-CoT). Our approach integrates two innovative modules: (1) a goal-oriented visual prompt, which enhances goal prediction accuracy combining visual prompts with a pretrained visual encoder, and (2) a chain-of-thought (CoT) LLM for trajectory generation, which generates realistic trajectories toward the predicted goal. Moreover, our method introduces controllable trajectory generation, allowing for flexible and user-guided modifications to the predicted paths. Through extensive experiments on the ETH/UCY benchmark datasets, our method achieves state-of-the-art performance, delivering both high accuracy and greater adaptability in pedestrian trajectory prediction. Our code is publicly available at https://github.com/ai-kmu/GUIDE-CoT.
Learning Temporal Cues by Predicting Objects Move for Multi-camera 3D Object Detection
Apr 02, 2024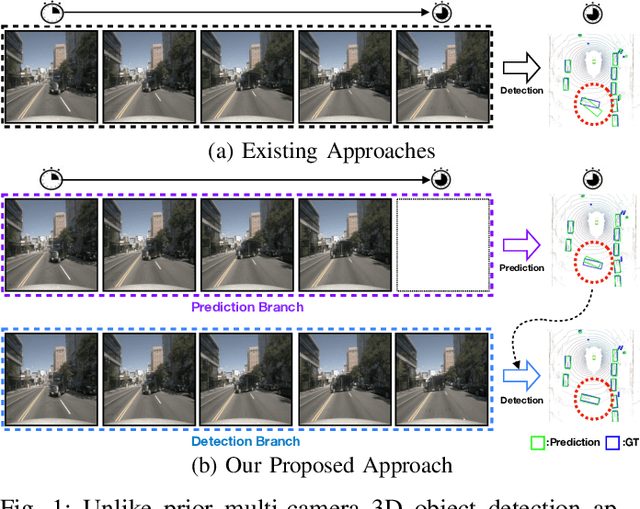


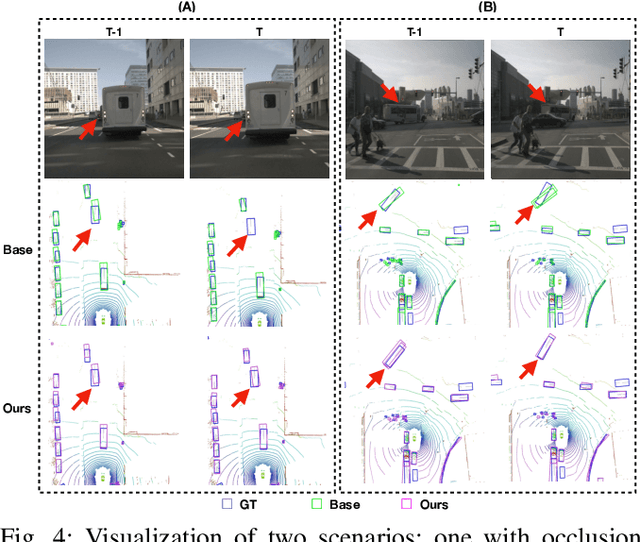
In autonomous driving and robotics, there is a growing interest in utilizing short-term historical data to enhance multi-camera 3D object detection, leveraging the continuous and correlated nature of input video streams. Recent work has focused on spatially aligning BEV-based features over timesteps. However, this is often limited as its gain does not scale well with long-term past observations. To address this, we advocate for supervising a model to predict objects' poses given past observations, thus explicitly guiding to learn objects' temporal cues. To this end, we propose a model called DAP (Detection After Prediction), consisting of a two-branch network: (i) a branch responsible for forecasting the current objects' poses given past observations and (ii) another branch that detects objects based on the current and past observations. The features predicting the current objects from branch (i) is fused into branch (ii) to transfer predictive knowledge. We conduct extensive experiments with the large-scale nuScenes datasets, and we observe that utilizing such predictive information significantly improves the overall detection performance. Our model can be used plug-and-play, showing consistent performance gain.
SelfReg: Self-supervised Contrastive Regularization for Domain Generalization
Apr 20, 2021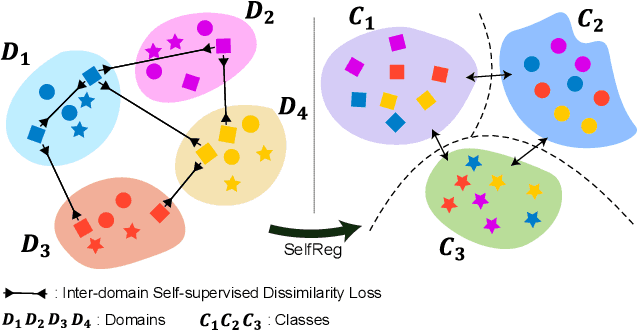
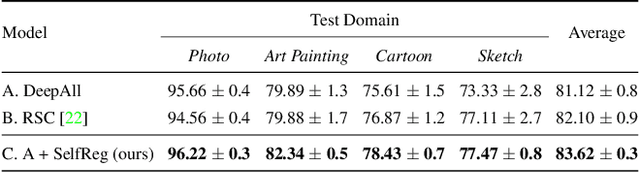
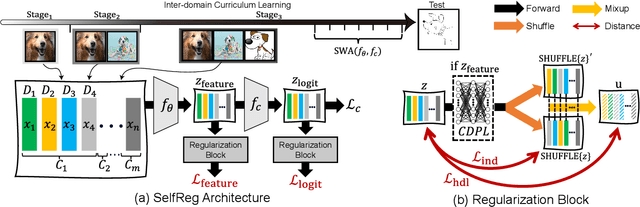

In general, an experimental environment for deep learning assumes that the training and the test dataset are sampled from the same distribution. However, in real-world situations, a difference in the distribution between two datasets, domain shift, may occur, which becomes a major factor impeding the generalization performance of the model. The research field to solve this problem is called domain generalization, and it alleviates the domain shift problem by extracting domain-invariant features explicitly or implicitly. In recent studies, contrastive learning-based domain generalization approaches have been proposed and achieved high performance. These approaches require sampling of the negative data pair. However, the performance of contrastive learning fundamentally depends on quality and quantity of negative data pairs. To address this issue, we propose a new regularization method for domain generalization based on contrastive learning, self-supervised contrastive regularization (SelfReg). The proposed approach use only positive data pairs, thus it resolves various problems caused by negative pair sampling. Moreover, we propose a class-specific domain perturbation layer (CDPL), which makes it possible to effectively apply mixup augmentation even when only positive data pairs are used. The experimental results show that the techniques incorporated by SelfReg contributed to the performance in a compatible manner. In the recent benchmark, DomainBed, the proposed method shows comparable performance to the conventional state-of-the-art alternatives. Codes are available at https://github.com/dnap512/SelfReg.
Deep Learning on Key Performance Indicators for Predictive Maintenance in SAP HANA
Apr 16, 2018
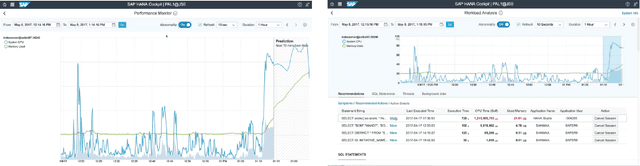
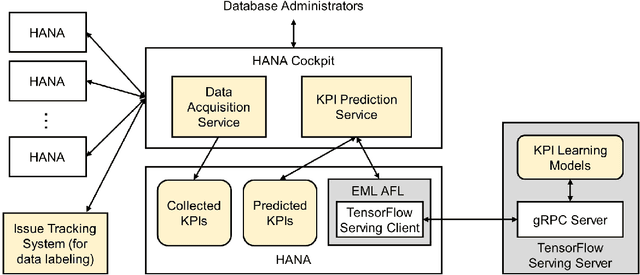

With a new era of cloud and big data, Database Management Systems (DBMSs) have become more crucial in numerous enterprise business applications in all the industries. Accordingly, the importance of their proactive and preventive maintenance has also increased. However, detecting problems by predefined rules or stochastic modeling has limitations, particularly when analyzing the data on high-dimensional Key Performance Indicators (KPIs) from a DBMS. In recent years, Deep Learning (DL) has opened new opportunities for this complex analysis. In this paper, we present two complementary DL approaches to detect anomalies in SAP HANA. A temporal learning approach is used to detect abnormal patterns based on unlabeled historical data, whereas a spatial learning approach is used to classify known anomalies based on labeled data. We implement a system in SAP HANA integrated with Google TensorFlow. The experimental results with real-world data confirm the effectiveness of the system and models.
Intrinsic Geometric Information Transfer Learning on Multiple Graph-Structured Datasets
Dec 05, 2016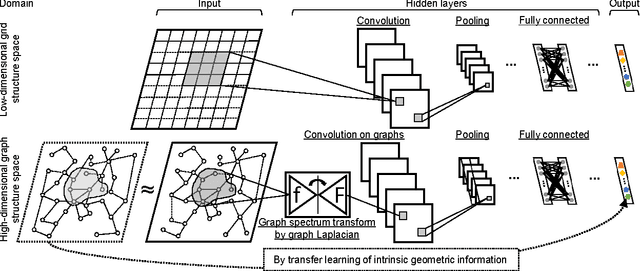
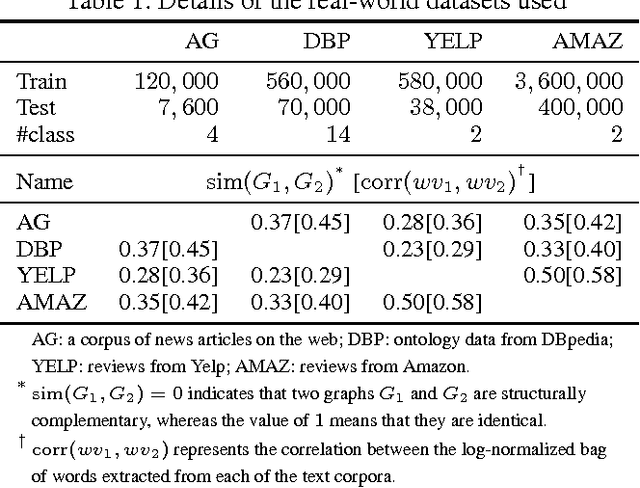
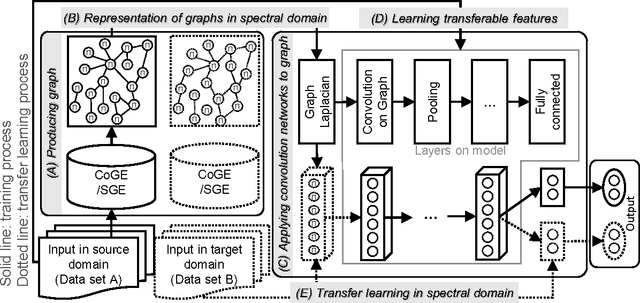
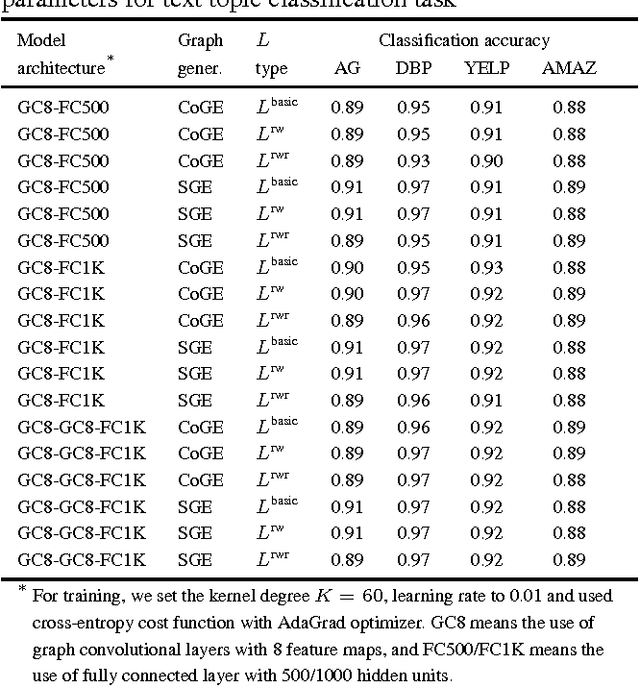
Graphs provide a powerful means for representing complex interactions between entities. Recently, deep learning approaches are emerging for representing and modeling graph-structured data, although the conventional deep learning methods (such as convolutional neural networks and recurrent neural networks) have mainly focused on grid-structured inputs (image and audio). Leveraged by the capability of representation learning, deep learning based techniques are reporting promising results for graph applications by detecting structural characteristics of graphs in an automated fashion. In this paper, we attempt to advance deep learning for graph-structured data by incorporating another component, transfer learning. By transferring the intrinsic geometric information learned in the source domain, our approach can help us to construct a model for a new but related task in the target domain without collecting new data and without training a new model from scratch. We thoroughly test our approach with large-scale real corpora and confirm the effectiveness of the proposed transfer learning framework for deep learning on graphs. According to our experiments, transfer learning is most effective when the source and target domains bear a high level of structural similarity in their graph representations.