 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePreference Alignment with Flow Matching
May 30, 2024



We present Preference Flow Matching (PFM), a new framework for preference-based reinforcement learning (PbRL) that streamlines the integration of preferences into an arbitrary class of pre-trained models. Existing PbRL methods require fine-tuning pre-trained models, which presents challenges such as scalability, inefficiency, and the need for model modifications, especially with black-box APIs like GPT-4. In contrast, PFM utilizes flow matching techniques to directly learn from preference data, thereby reducing the dependency on extensive fine-tuning of pre-trained models. By leveraging flow-based models, PFM transforms less preferred data into preferred outcomes, and effectively aligns model outputs with human preferences without relying on explicit or implicit reward function estimation, thus avoiding common issues like overfitting in reward models. We provide theoretical insights that support our method's alignment with standard PbRL objectives. Experimental results indicate the practical effectiveness of our method, offering a new direction in aligning a pre-trained model to preference.
The StarCraft Multi-Agent Challenges+ : Learning of Multi-Stage Tasks and Environmental Factors without Precise Reward Functions
Jul 07, 2022


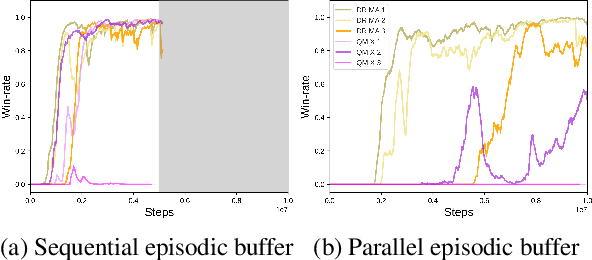
In this paper, we propose a novel benchmark called the StarCraft Multi-Agent Challenges+, where agents learn to perform multi-stage tasks and to use environmental factors without precise reward functions. The previous challenges (SMAC) recognized as a standard benchmark of Multi-Agent Reinforcement Learning are mainly concerned with ensuring that all agents cooperatively eliminate approaching adversaries only through fine manipulation with obvious reward functions. This challenge, on the other hand, is interested in the exploration capability of MARL algorithms to efficiently learn implicit multi-stage tasks and environmental factors as well as micro-control. This study covers both offensive and defensive scenarios. In the offensive scenarios, agents must learn to first find opponents and then eliminate them. The defensive scenarios require agents to use topographic features. For example, agents need to position themselves behind protective structures to make it harder for enemies to attack. We investigate MARL algorithms under SMAC+ and observe that recent approaches work well in similar settings to the previous challenges, but misbehave in offensive scenarios. Additionally, we observe that an enhanced exploration approach has a positive effect on performance but is not able to completely solve all scenarios. This study proposes new directions for future research.
Deep Learning on Key Performance Indicators for Predictive Maintenance in SAP HANA
Apr 16, 2018
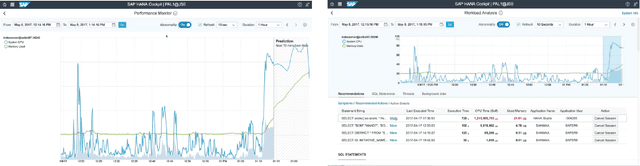
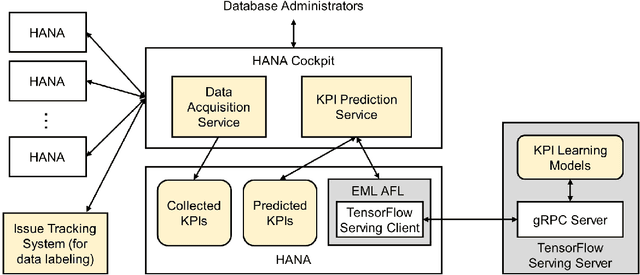

With a new era of cloud and big data, Database Management Systems (DBMSs) have become more crucial in numerous enterprise business applications in all the industries. Accordingly, the importance of their proactive and preventive maintenance has also increased. However, detecting problems by predefined rules or stochastic modeling has limitations, particularly when analyzing the data on high-dimensional Key Performance Indicators (KPIs) from a DBMS. In recent years, Deep Learning (DL) has opened new opportunities for this complex analysis. In this paper, we present two complementary DL approaches to detect anomalies in SAP HANA. A temporal learning approach is used to detect abnormal patterns based on unlabeled historical data, whereas a spatial learning approach is used to classify known anomalies based on labeled data. We implement a system in SAP HANA integrated with Google TensorFlow. The experimental results with real-world data confirm the effectiveness of the system and models.