 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInstruction-Guided Autoregressive Neural Network Parameter Generation
Apr 02, 2025Learning to generate neural network parameters conditioned on task descriptions and architecture specifications is pivotal for advancing model adaptability and transfer learning. Existing methods especially those based on diffusion models suffer from limited scalability to large architectures, rigidity in handling varying network depths, and disjointed parameter generation that undermines inter-layer coherence. In this work, we propose IGPG (Instruction Guided Parameter Generation), an autoregressive framework that unifies parameter synthesis across diverse tasks and architectures. IGPG leverages a VQ-VAE and an autoregressive model to generate neural network parameters, conditioned on task instructions, dataset, and architecture details. By autoregressively generating neural network weights' tokens, IGPG ensures inter-layer coherence and enables efficient adaptation across models and datasets. Operating at the token level, IGPG effectively captures complex parameter distributions aggregated from a broad spectrum of pretrained models. Extensive experiments on multiple vision datasets demonstrate that IGPG consolidates diverse pretrained models into a single, flexible generative framework. The synthesized parameters achieve competitive or superior performance relative to state-of-the-art methods, especially in terms of scalability and efficiency when applied to large architectures. These results underscore ICPG potential as a powerful tool for pretrained weight retrieval, model selection, and rapid task-specific fine-tuning.
Preference Alignment with Flow Matching
May 30, 2024



We present Preference Flow Matching (PFM), a new framework for preference-based reinforcement learning (PbRL) that streamlines the integration of preferences into an arbitrary class of pre-trained models. Existing PbRL methods require fine-tuning pre-trained models, which presents challenges such as scalability, inefficiency, and the need for model modifications, especially with black-box APIs like GPT-4. In contrast, PFM utilizes flow matching techniques to directly learn from preference data, thereby reducing the dependency on extensive fine-tuning of pre-trained models. By leveraging flow-based models, PFM transforms less preferred data into preferred outcomes, and effectively aligns model outputs with human preferences without relying on explicit or implicit reward function estimation, thus avoiding common issues like overfitting in reward models. We provide theoretical insights that support our method's alignment with standard PbRL objectives. Experimental results indicate the practical effectiveness of our method, offering a new direction in aligning a pre-trained model to preference.
Diffusion-based Neural Network Weights Generation
Feb 28, 2024



Transfer learning is a topic of significant interest in recent deep learning research because it enables faster convergence and improved performance on new tasks. While the performance of transfer learning depends on the similarity of the source data to the target data, it is costly to train a model on a large number of datasets. Therefore, pretrained models are generally blindly selected with the hope that they will achieve good performance on the given task. To tackle such suboptimality of the pretrained models, we propose an efficient and adaptive transfer learning scheme through dataset-conditioned pretrained weights sampling. Specifically, we use a latent diffusion model with a variational autoencoder that can reconstruct the neural network weights, to learn the distribution of a set of pretrained weights conditioned on each dataset for transfer learning on unseen datasets. By learning the distribution of a neural network on a variety pretrained models, our approach enables adaptive sampling weights for unseen datasets achieving faster convergence and reaching competitive performance.
The StarCraft Multi-Agent Challenges+ : Learning of Multi-Stage Tasks and Environmental Factors without Precise Reward Functions
Jul 07, 2022


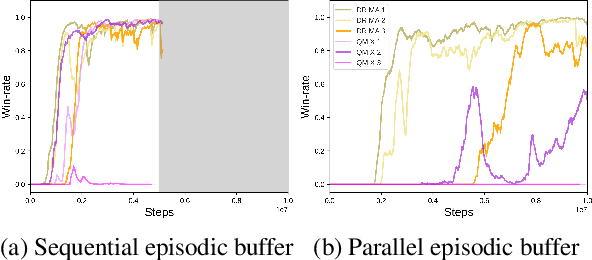
In this paper, we propose a novel benchmark called the StarCraft Multi-Agent Challenges+, where agents learn to perform multi-stage tasks and to use environmental factors without precise reward functions. The previous challenges (SMAC) recognized as a standard benchmark of Multi-Agent Reinforcement Learning are mainly concerned with ensuring that all agents cooperatively eliminate approaching adversaries only through fine manipulation with obvious reward functions. This challenge, on the other hand, is interested in the exploration capability of MARL algorithms to efficiently learn implicit multi-stage tasks and environmental factors as well as micro-control. This study covers both offensive and defensive scenarios. In the offensive scenarios, agents must learn to first find opponents and then eliminate them. The defensive scenarios require agents to use topographic features. For example, agents need to position themselves behind protective structures to make it harder for enemies to attack. We investigate MARL algorithms under SMAC+ and observe that recent approaches work well in similar settings to the previous challenges, but misbehave in offensive scenarios. Additionally, we observe that an enhanced exploration approach has a positive effect on performance but is not able to completely solve all scenarios. This study proposes new directions for future research.
HELP: Hardware-Adaptive Efficient Latency Predictor for NAS via Meta-Learning
Jun 16, 2021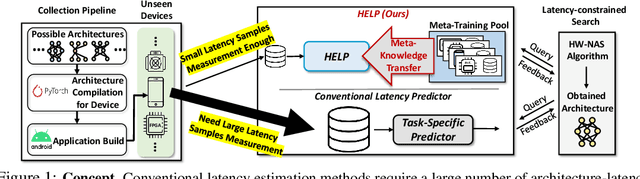
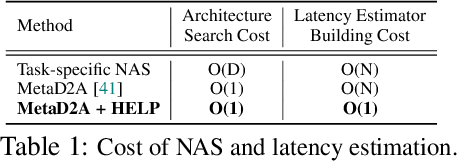
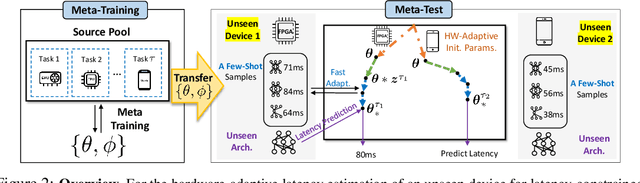
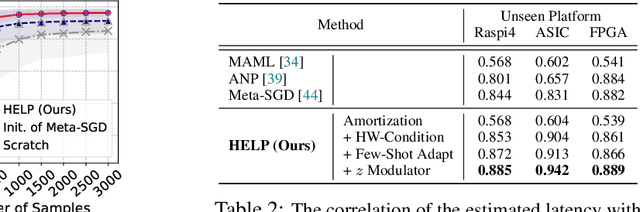
For deployment, neural architecture search should be hardware-aware, in order to satisfy the device-specific constraints (e.g., memory usage, latency and energy consumption) and enhance the model efficiency. Existing methods on hardware-aware NAS collect a large number of samples (e.g., accuracy and latency) from a target device, either builds a lookup table or a latency estimator. However, such approach is impractical in real-world scenarios as there exist numerous devices with different hardware specifications, and collecting samples from such a large number of devices will require prohibitive computational and monetary cost. To overcome such limitations, we propose Hardware-adaptive Efficient Latency Predictor (HELP), which formulates the device-specific latency estimation problem as a meta-learning problem, such that we can estimate the latency of a model's performance for a given task on an unseen device with a few samples. To this end, we introduce novel hardware embeddings to embed any devices considering them as black-box functions that output latencies, and meta-learn the hardware-adaptive latency predictor in a device-dependent manner, using the hardware embeddings. We validate the proposed HELP for its latency estimation performance on unseen platforms, on which it achieves high estimation performance with as few as 10 measurement samples, outperforming all relevant baselines. We also validate end-to-end NAS frameworks using HELP against ones without it, and show that it largely reduces the total time cost of the base NAS method, in latency-constrained settings.
Simplified Stochastic Feedforward Neural Networks
Apr 11, 2017


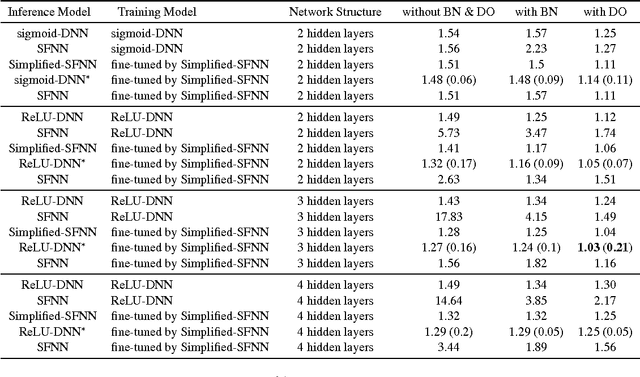
It has been believed that stochastic feedforward neural networks (SFNNs) have several advantages beyond deterministic deep neural networks (DNNs): they have more expressive power allowing multi-modal mappings and regularize better due to their stochastic nature. However, training large-scale SFNN is notoriously harder. In this paper, we aim at developing efficient training methods for SFNN, in particular using known architectures and pre-trained parameters of DNN. To this end, we propose a new intermediate stochastic model, called Simplified-SFNN, which can be built upon any baseline DNNand approximates certain SFNN by simplifying its upper latent units above stochastic ones. The main novelty of our approach is in establishing the connection between three models, i.e., DNN->Simplified-SFNN->SFNN, which naturally leads to an efficient training procedure of the stochastic models utilizing pre-trained parameters of DNN. Using several popular DNNs, we show how they can be effectively transferred to the corresponding stochastic models for both multi-modal and classification tasks on MNIST, TFD, CASIA, CIFAR-10, CIFAR-100 and SVHN datasets. In particular, we train a stochastic model of 28 layers and 36 million parameters, where training such a large-scale stochastic network is significantly challenging without using Simplified-SFNN