 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvaluating and Designing Sparse Autoencoders by Approximating Quasi-Orthogonality
Mar 31, 2025



Sparse autoencoders (SAEs) have emerged as a workhorse of modern mechanistic interpretability, but leading SAE approaches with top-$k$ style activation functions lack theoretical grounding for selecting the hyperparameter $k$. SAEs are based on the linear representation hypothesis (LRH), which assumes that the representations of large language models (LLMs) are linearly encoded, and the superposition hypothesis (SH), which states that there can be more features in the model than its dimensionality. We show that, based on the formal definitions of the LRH and SH, the magnitude of sparse feature vectors (the latent representations learned by SAEs of the dense embeddings of LLMs) can be approximated using their corresponding dense vector with a closed-form error bound. To visualize this, we propose the ZF plot, which reveals a previously unknown relationship between LLM hidden embeddings and SAE feature vectors, allowing us to make the first empirical measurement of the extent to which feature vectors of pre-trained SAEs are over- or under-activated for a given input. Correspondingly, we introduce Approximate Feature Activation (AFA), which approximates the magnitude of the ground-truth sparse feature vector, and propose a new evaluation metric derived from AFA to assess the alignment between inputs and activations. We also leverage AFA to introduce a novel SAE architecture, the top-AFA SAE, leading to SAEs that: (a) are more in line with theoretical justifications; and (b) obviate the need to tune SAE sparsity hyperparameters. Finally, we empirically demonstrate that top-AFA SAEs achieve reconstruction loss comparable to that of state-of-the-art top-k SAEs, without requiring the hyperparameter $k$ to be tuned. Our code is available at: https://github.com/SewoongLee/top-afa-sae.
Generative Pre-Training of Time-Series Data for Unsupervised Fault Detection in Semiconductor Manufacturing
Sep 20, 2023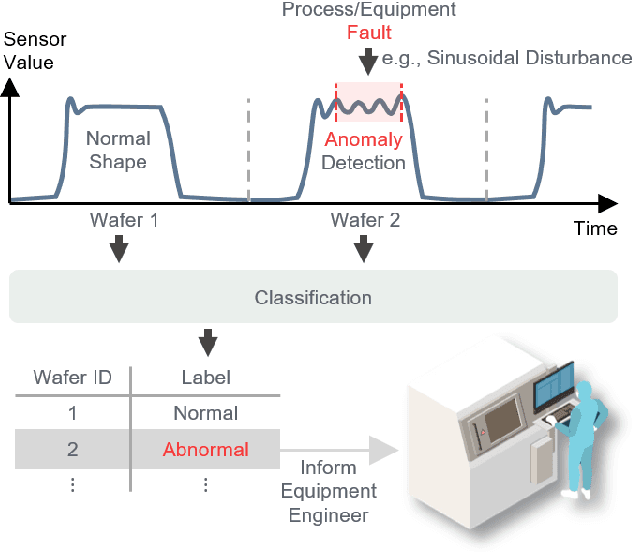
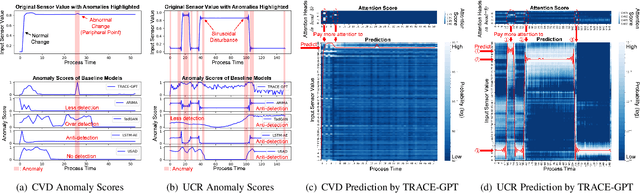
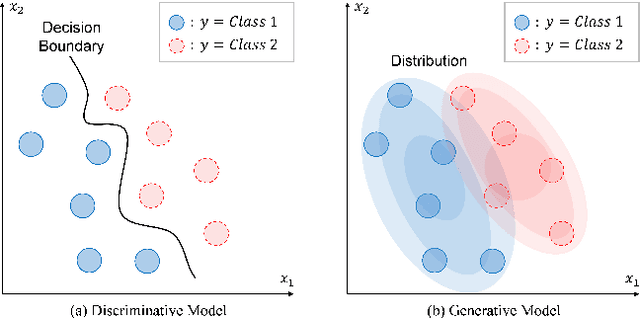
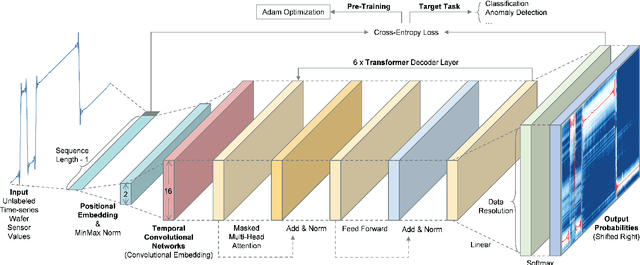
This paper introduces TRACE-GPT, which stands for Time-seRies Anomaly-detection with Convolutional Embedding and Generative Pre-trained Transformers. TRACE-GPT is designed to pre-train univariate time-series sensor data and detect faults on unlabeled datasets in semiconductor manufacturing. In semiconductor industry, classifying abnormal time-series sensor data from normal data is important because it is directly related to wafer defect. However, small, unlabeled, and even mixed training data without enough anomalies make classification tasks difficult. In this research, we capture features of time-series data with temporal convolutional embedding and Generative Pre-trained Transformer (GPT) to classify abnormal sequences from normal sequences using cross entropy loss. We prove that our model shows better performance than previous unsupervised models with both an open dataset, the University of California Riverside (UCR) time-series classification archive, and the process log of our Chemical Vapor Deposition (CVD) equipment. Our model has the highest F1 score at Equal Error Rate (EER) across all datasets and is only 0.026 below the supervised state-of-the-art baseline on the open dataset.
HELP: Hardware-Adaptive Efficient Latency Predictor for NAS via Meta-Learning
Jun 16, 2021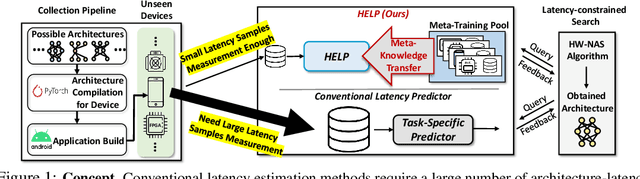
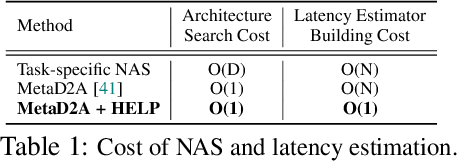
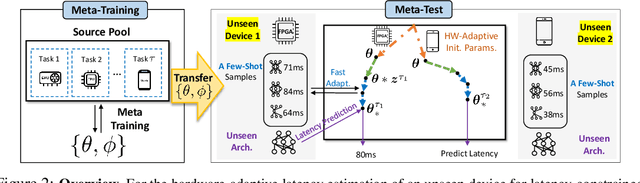
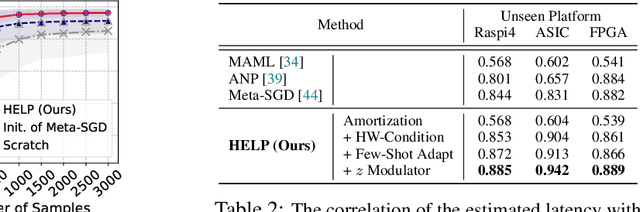
For deployment, neural architecture search should be hardware-aware, in order to satisfy the device-specific constraints (e.g., memory usage, latency and energy consumption) and enhance the model efficiency. Existing methods on hardware-aware NAS collect a large number of samples (e.g., accuracy and latency) from a target device, either builds a lookup table or a latency estimator. However, such approach is impractical in real-world scenarios as there exist numerous devices with different hardware specifications, and collecting samples from such a large number of devices will require prohibitive computational and monetary cost. To overcome such limitations, we propose Hardware-adaptive Efficient Latency Predictor (HELP), which formulates the device-specific latency estimation problem as a meta-learning problem, such that we can estimate the latency of a model's performance for a given task on an unseen device with a few samples. To this end, we introduce novel hardware embeddings to embed any devices considering them as black-box functions that output latencies, and meta-learn the hardware-adaptive latency predictor in a device-dependent manner, using the hardware embeddings. We validate the proposed HELP for its latency estimation performance on unseen platforms, on which it achieves high estimation performance with as few as 10 measurement samples, outperforming all relevant baselines. We also validate end-to-end NAS frameworks using HELP against ones without it, and show that it largely reduces the total time cost of the base NAS method, in latency-constrained settings.