 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvaluating and Designing Sparse Autoencoders by Approximating Quasi-Orthogonality
Mar 31, 2025



Sparse autoencoders (SAEs) have emerged as a workhorse of modern mechanistic interpretability, but leading SAE approaches with top-$k$ style activation functions lack theoretical grounding for selecting the hyperparameter $k$. SAEs are based on the linear representation hypothesis (LRH), which assumes that the representations of large language models (LLMs) are linearly encoded, and the superposition hypothesis (SH), which states that there can be more features in the model than its dimensionality. We show that, based on the formal definitions of the LRH and SH, the magnitude of sparse feature vectors (the latent representations learned by SAEs of the dense embeddings of LLMs) can be approximated using their corresponding dense vector with a closed-form error bound. To visualize this, we propose the ZF plot, which reveals a previously unknown relationship between LLM hidden embeddings and SAE feature vectors, allowing us to make the first empirical measurement of the extent to which feature vectors of pre-trained SAEs are over- or under-activated for a given input. Correspondingly, we introduce Approximate Feature Activation (AFA), which approximates the magnitude of the ground-truth sparse feature vector, and propose a new evaluation metric derived from AFA to assess the alignment between inputs and activations. We also leverage AFA to introduce a novel SAE architecture, the top-AFA SAE, leading to SAEs that: (a) are more in line with theoretical justifications; and (b) obviate the need to tune SAE sparsity hyperparameters. Finally, we empirically demonstrate that top-AFA SAEs achieve reconstruction loss comparable to that of state-of-the-art top-k SAEs, without requiring the hyperparameter $k$ to be tuned. Our code is available at: https://github.com/SewoongLee/top-afa-sae.
A Framework for Bidirectional Decoding: Case Study in Morphological Inflection
May 21, 2023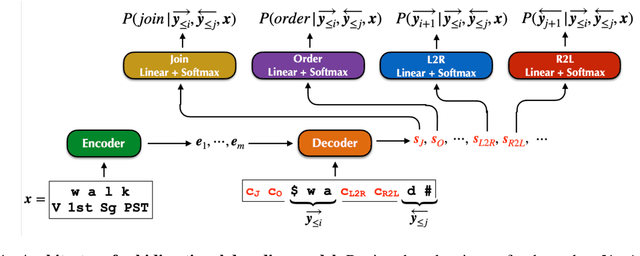
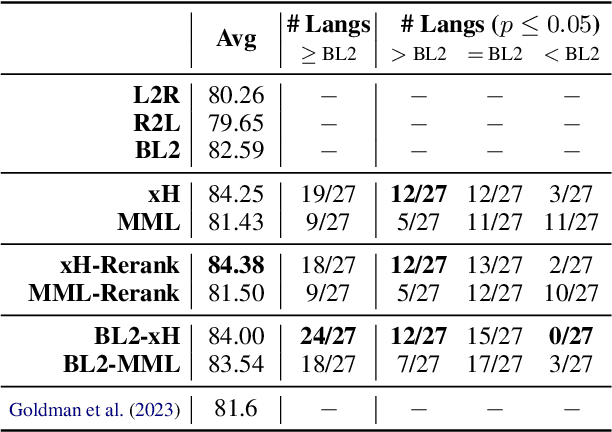
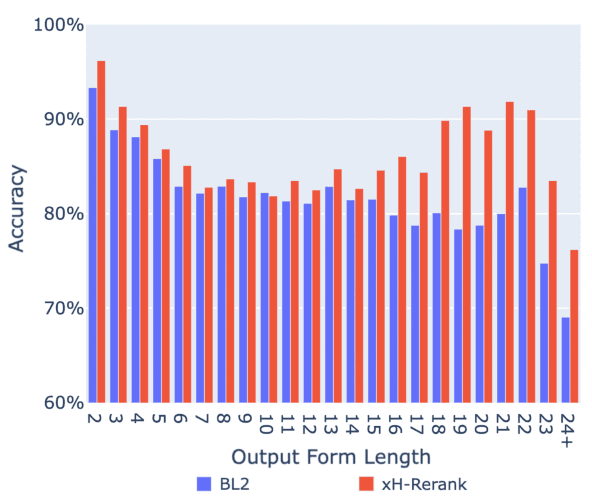
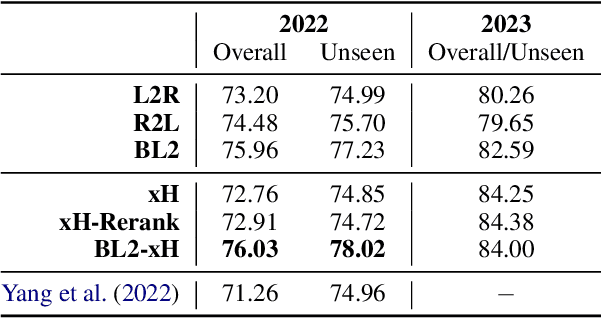
Transformer-based encoder-decoder models that generate outputs in a left-to-right fashion have become standard for sequence-to-sequence tasks. In this paper, we propose a framework for decoding that produces sequences from the "outside-in": at each step, the model chooses to generate a token on the left, on the right, or join the left and right sequences. We argue that this is more principled than prior bidirectional decoders. Our proposal supports a variety of model architectures and includes several training methods, such as a dynamic programming algorithm that marginalizes out the latent ordering variable. Our model improves considerably over a simple baseline based on unidirectional transformers on the SIGMORPHON 2023 inflection task and sets SOTA on the 2022 shared task. The model performs particularly well on long sequences, can learn the split point of words composed of stem and affix (without supervision), and performs better relative to the baseline on datasets that have fewer unique lemmas (but more examples per lemma).