 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRobust Molecular Property Prediction via Densifying Scarce Labeled Data
Jun 13, 2025A widely recognized limitation of molecular prediction models is their reliance on structures observed in the training data, resulting in poor generalization to out-of-distribution compounds. Yet in drug discovery, the compounds most critical for advancing research often lie beyond the training set, making the bias toward the training data particularly problematic. This mismatch introduces substantial covariate shift, under which standard deep learning models produce unstable and inaccurate predictions. Furthermore, the scarcity of labeled data, stemming from the onerous and costly nature of experimental validation, further exacerbates the difficulty of achieving reliable generalization. To address these limitations, we propose a novel meta-learning-based approach that leverages unlabeled data to interpolate between in-distribution (ID) and out-of-distribution (OOD) data, enabling the model to meta-learn how to generalize beyond the training distribution. We demonstrate significant performance gains over state-of-the-art methods on challenging real-world datasets that exhibit substantial covariate shift.
Instruction-Guided Autoregressive Neural Network Parameter Generation
Apr 02, 2025Learning to generate neural network parameters conditioned on task descriptions and architecture specifications is pivotal for advancing model adaptability and transfer learning. Existing methods especially those based on diffusion models suffer from limited scalability to large architectures, rigidity in handling varying network depths, and disjointed parameter generation that undermines inter-layer coherence. In this work, we propose IGPG (Instruction Guided Parameter Generation), an autoregressive framework that unifies parameter synthesis across diverse tasks and architectures. IGPG leverages a VQ-VAE and an autoregressive model to generate neural network parameters, conditioned on task instructions, dataset, and architecture details. By autoregressively generating neural network weights' tokens, IGPG ensures inter-layer coherence and enables efficient adaptation across models and datasets. Operating at the token level, IGPG effectively captures complex parameter distributions aggregated from a broad spectrum of pretrained models. Extensive experiments on multiple vision datasets demonstrate that IGPG consolidates diverse pretrained models into a single, flexible generative framework. The synthesized parameters achieve competitive or superior performance relative to state-of-the-art methods, especially in terms of scalability and efficiency when applied to large architectures. These results underscore ICPG potential as a powerful tool for pretrained weight retrieval, model selection, and rapid task-specific fine-tuning.
Diffusion-based Neural Network Weights Generation
Feb 28, 2024



Transfer learning is a topic of significant interest in recent deep learning research because it enables faster convergence and improved performance on new tasks. While the performance of transfer learning depends on the similarity of the source data to the target data, it is costly to train a model on a large number of datasets. Therefore, pretrained models are generally blindly selected with the hope that they will achieve good performance on the given task. To tackle such suboptimality of the pretrained models, we propose an efficient and adaptive transfer learning scheme through dataset-conditioned pretrained weights sampling. Specifically, we use a latent diffusion model with a variational autoencoder that can reconstruct the neural network weights, to learn the distribution of a set of pretrained weights conditioned on each dataset for transfer learning on unseen datasets. By learning the distribution of a neural network on a variety pretrained models, our approach enables adaptive sampling weights for unseen datasets achieving faster convergence and reaching competitive performance.
Set-based Neural Network Encoding
May 26, 2023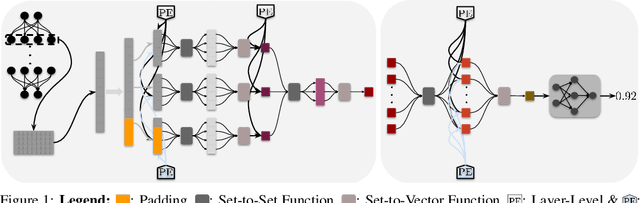
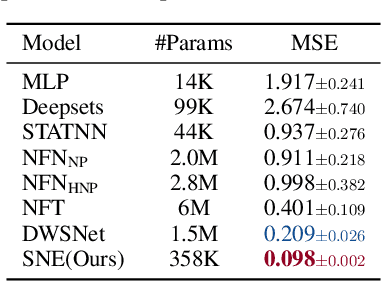
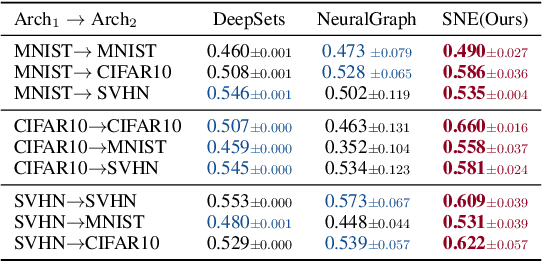
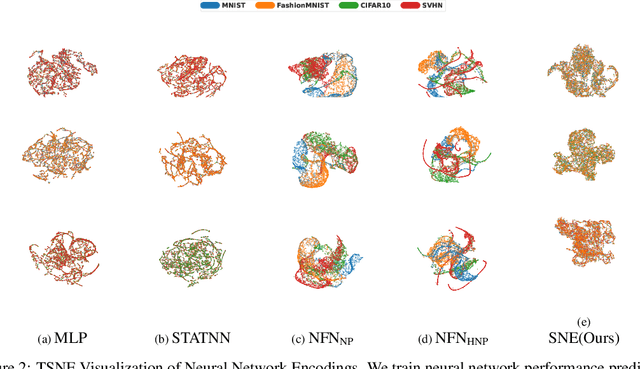
We propose an approach to neural network weight encoding for generalization performance prediction that utilizes set-to-set and set-to-vector functions to efficiently encode neural network parameters. Our approach is capable of encoding neural networks in a modelzoo of mixed architecture and different parameter sizes as opposed to previous approaches that require custom encoding models for different architectures. Furthermore, our \textbf{S}et-based \textbf{N}eural network \textbf{E}ncoder (SNE) takes into consideration the hierarchical computational structure of neural networks by utilizing a layer-wise encoding scheme that culminates to encoding all layer-wise encodings to obtain the neural network encoding vector. Additionally, we introduce a \textit{pad-chunk-encode} pipeline to efficiently encode neural network layers that is adjustable to computational and memory constraints. We also introduce two new tasks for neural network generalization performance prediction: cross-dataset and cross-architecture. In cross-dataset performance prediction, we evaluate how well performance predictors generalize across modelzoos trained on different datasets but of the same architecture. In cross-architecture performance prediction, we evaluate how well generalization performance predictors transfer to modelzoos of different architecture. Experimentally, we show that SNE outperforms the relevant baselines on the cross-dataset task and provide the first set of results on the cross-architecture task.
Distortion-Aware Network Pruning and Feature Reuse for Real-time Video Segmentation
Jun 20, 2022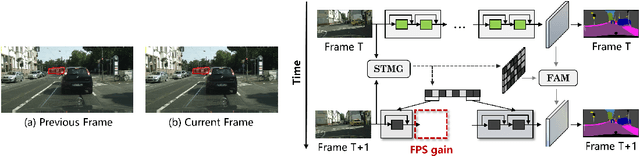
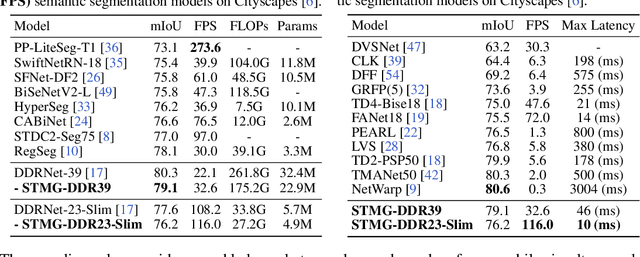
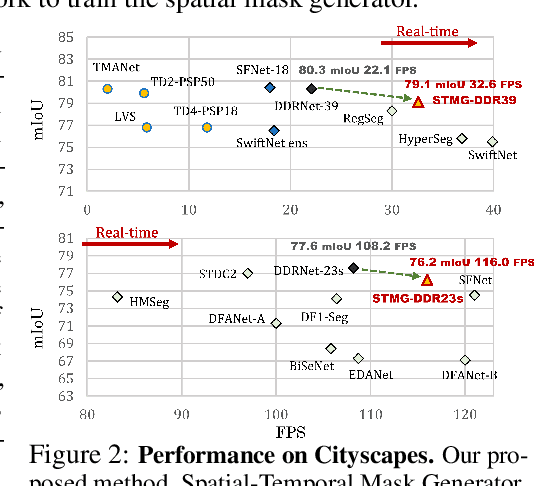
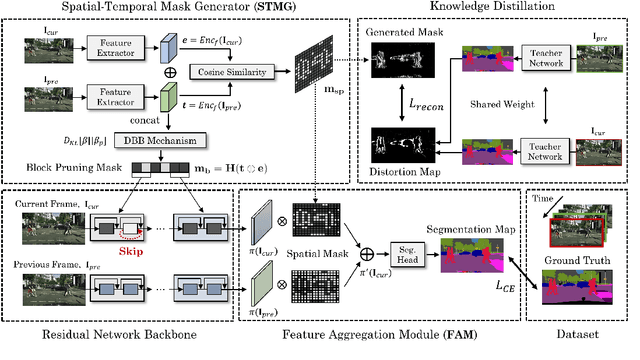
Real-time video segmentation is a crucial task for many real-world applications such as autonomous driving and robot control. Since state-of-the-art semantic segmentation models are often too heavy for real-time applications despite their impressive performance, researchers have proposed lightweight architectures with speed-accuracy trade-offs, achieving real-time speed at the expense of reduced accuracy. In this paper, we propose a novel framework to speed up any architecture with skip-connections for real-time vision tasks by exploiting the temporal locality in videos. Specifically, at the arrival of each frame, we transform the features from the previous frame to reuse them at specific spatial bins. We then perform partial computation of the backbone network on the regions of the current frame that captures temporal differences between the current and previous frame. This is done by dynamically dropping out residual blocks using a gating mechanism which decides which blocks to drop based on inter-frame distortion. We validate our Spatial-Temporal Mask Generator (STMG) on video semantic segmentation benchmarks with multiple backbone networks, and show that our method largely speeds up inference with minimal loss of accuracy.
Set-based Meta-Interpolation for Few-Task Meta-Learning
May 20, 2022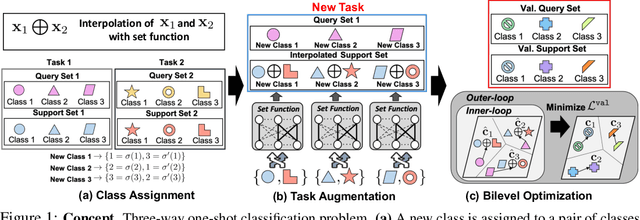
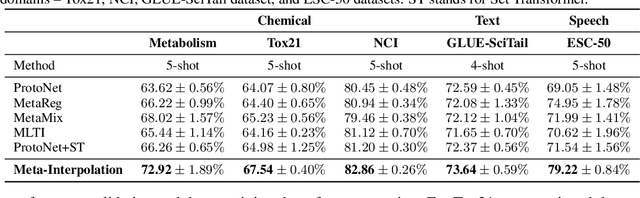
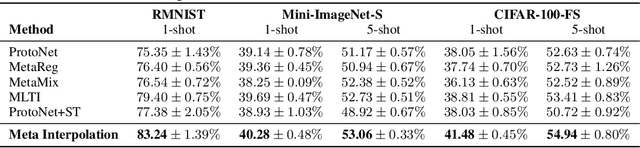
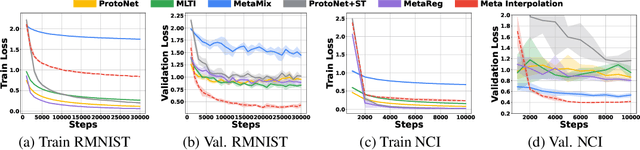
Meta-learning approaches enable machine learning systems to adapt to new tasks given few examples by leveraging knowledge from related tasks. However, a large number of meta-training tasks are still required for generalization to unseen tasks during meta-testing, which introduces a critical bottleneck for real-world problems that come with only few tasks, due to various reasons including the difficulty and cost of constructing tasks. Recently, several task augmentation methods have been proposed to tackle this issue using domain-specific knowledge to design augmentation techniques to densify the meta-training task distribution. However, such reliance on domain-specific knowledge renders these methods inapplicable to other domains. While Manifold Mixup based task augmentation methods are domain-agnostic, we empirically find them ineffective on non-image domains. To tackle these limitations, we propose a novel domain-agnostic task augmentation method, Meta-Interpolation, which utilizes expressive neural set functions to densify the meta-training task distribution using bilevel optimization. We empirically validate the efficacy of Meta-Interpolation on eight datasets spanning across various domains such as image classification, molecule property prediction, text classification and speech recognition. Experimentally, we show that Meta-Interpolation consistently outperforms all the relevant baselines. Theoretically, we prove that task interpolation with the set function regularizes the meta-learner to improve generalization.
Mini-Batch Consistent Slot Set Encoder for Scalable Set Encoding
Mar 02, 2021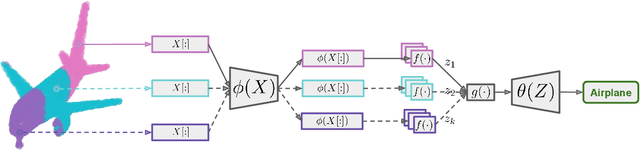

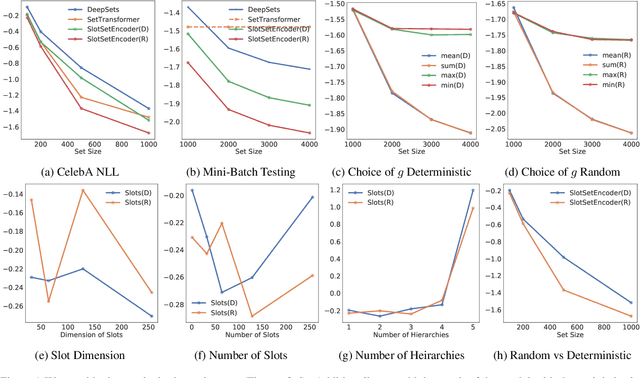

Most existing set encoding algorithms operate under the assumption that all the elements of the set are accessible during training and inference. Additionally, it is assumed that there are enough computational resources available for concurrently processing sets of large cardinality. However, both assumptions fail when the cardinality of the set is prohibitively large such that we cannot even load the set into memory. In more extreme cases, the set size could be potentially unlimited, and the elements of the set could be given in a streaming manner, where the model receives subsets of the full set data at irregular intervals. To tackle such practical challenges in large-scale set encoding, we go beyond the usual constraints of invariance and equivariance and introduce a new property termed Mini-Batch Consistency that is required for large scale mini-batch set encoding. We present a scalable and efficient set encoding mechanism that is amenable to mini-batch processing with respect to set elements and capable of updating set representations as more data arrives. The proposed method respects the required symmetries of invariance and equivariance as well as being Mini-Batch Consistent for random partitions of the input set. We perform extensive experiments and show that our method is computationally efficient and results in rich set encoding representations for set-structured data.
Stochastic Subset Selection
Jun 25, 2020
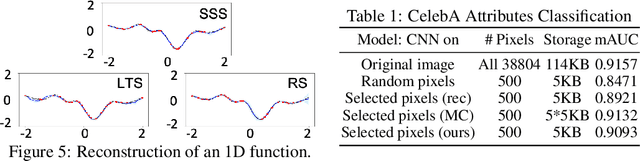
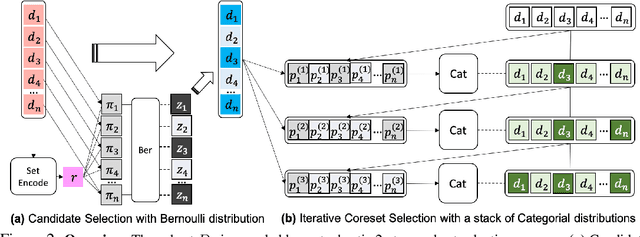
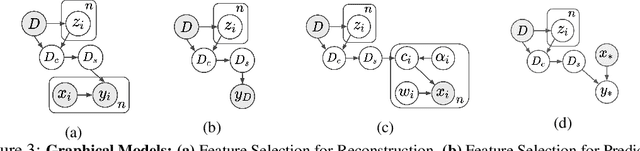
Current machine learning algorithms are designed to work with huge volumes of high dimensional data such as images. However, these algorithms are being increasingly deployed to resource constrained systems such as mobile devices and embedded systems. Even in cases where large computing infrastructure is available, the size of each data instance, as well as datasets, can provide a huge bottleneck in data transfer across communication channels. Also, there is a huge incentive both in energy and monetary terms in reducing both the computational and memory requirements of these algorithms. For non-parametric models that require to leverage the stored training data at the inference time, the increased cost in memory and computation could be even more problematic. In this work, we aim to reduce the volume of data these algorithms must process through an end-to-end two-stage neural subset selection model, where the first stage selects a set of candidate points using a conditionally independent Bernoulli mask followed by an iterative coreset selection via a conditional Categorical distribution. The subset selection model is trained by meta-learning with a distribution of sets. We validate our method on set reconstruction and classification tasks with feature selection as well as the selection of representative samples from a given dataset, on which our method outperforms relevant baselines. We also show in our experiments that our method enhances scalability of non-parametric models such as Neural Processes.