 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStochastic Subset Selection
Jun 25, 2020
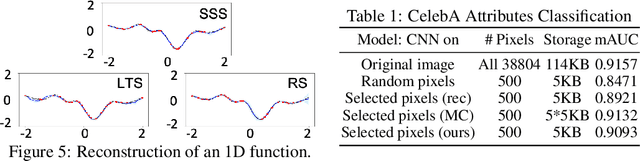
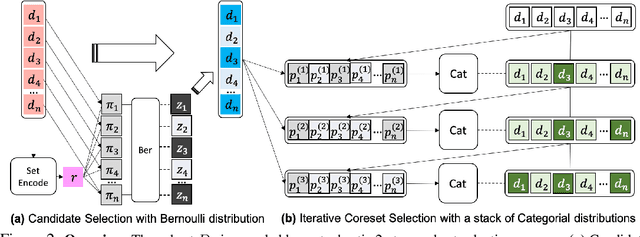
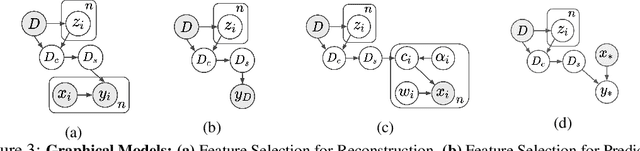
Current machine learning algorithms are designed to work with huge volumes of high dimensional data such as images. However, these algorithms are being increasingly deployed to resource constrained systems such as mobile devices and embedded systems. Even in cases where large computing infrastructure is available, the size of each data instance, as well as datasets, can provide a huge bottleneck in data transfer across communication channels. Also, there is a huge incentive both in energy and monetary terms in reducing both the computational and memory requirements of these algorithms. For non-parametric models that require to leverage the stored training data at the inference time, the increased cost in memory and computation could be even more problematic. In this work, we aim to reduce the volume of data these algorithms must process through an end-to-end two-stage neural subset selection model, where the first stage selects a set of candidate points using a conditionally independent Bernoulli mask followed by an iterative coreset selection via a conditional Categorical distribution. The subset selection model is trained by meta-learning with a distribution of sets. We validate our method on set reconstruction and classification tasks with feature selection as well as the selection of representative samples from a given dataset, on which our method outperforms relevant baselines. We also show in our experiments that our method enhances scalability of non-parametric models such as Neural Processes.
Clinical Risk Prediction with Temporal Probabilistic Asymmetric Multi-Task Learning
Jun 23, 2020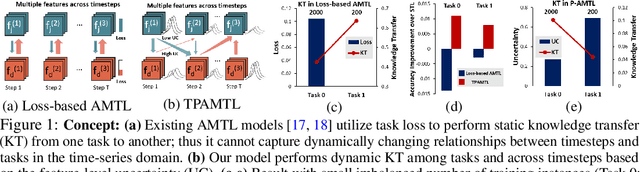

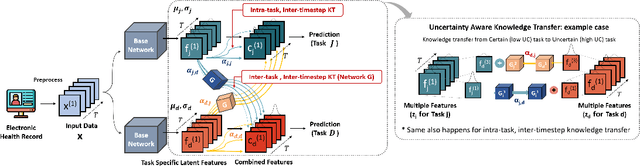

Although recent multi-task learning methods have shown to be effective in improving the generalization of deep neural networks, they should be used with caution for safety-critical applications, such as clinical risk prediction. This is because even if they achieve improved task-average performance, they may still yield degraded performance on individual tasks, which may be critical (e.g., prediction of mortality risk). Existing asymmetric multi-task learning methods tackle this negative transfer problem by performing knowledge transfer from tasks with low loss to tasks with high loss. However, using loss as a measure of reliability is risky since it could be a result of overfitting. In the case of time-series prediction tasks, knowledge learned for one task (e.g., predicting the sepsis onset) at a specific timestep may be useful for learning another task (e.g., prediction of mortality) at a later timestep, but lack of loss at each timestep makes it difficult to measure the reliability at each timestep. To capture such dynamically changing asymmetric relationships between tasks in time-series data, we propose a novel temporal asymmetric multi-task learning model that performs knowledge transfer from certain tasks/timesteps to relevant uncertain tasks, based on feature-level uncertainty. We validate our model on multiple clinical risk prediction tasks against various deep learning models for time-series prediction, which our model significantly outperforms, without any sign of negative transfer. Further qualitative analysis of learned knowledge graphs by clinicians shows that they are helpful in analyzing the predictions of the model. Our final code is available at https://github.com/anhtuan5696/TPAMTL.