 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient Video Representation Learning via Masked Video Modeling with Motion-centric Token Selection
Nov 19, 2022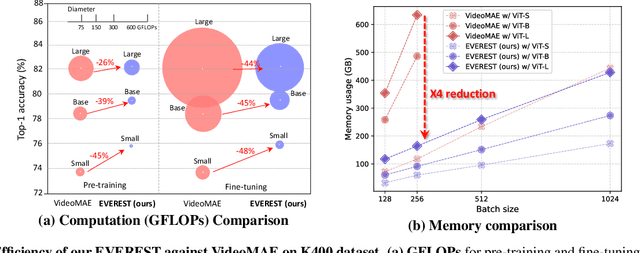
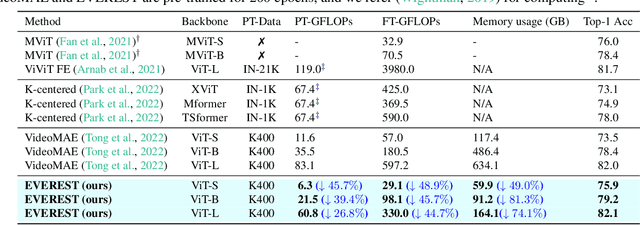
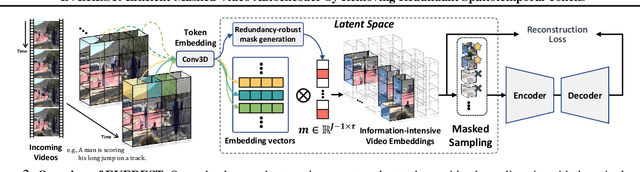

Self-supervised Video Representation Learning (VRL) aims to learn transferrable representations from uncurated, unlabeled video streams that could be utilized for diverse downstream tasks. With recent advances in Masked Image Modeling (MIM), in which the model learns to predict randomly masked regions in the images given only the visible patches, MIM-based VRL methods have emerged and demonstrated their potential by significantly outperforming previous VRL methods. However, they require an excessive amount of computations due to the added temporal dimension. This is because existing MIM-based VRL methods overlook spatial and temporal inequality of information density among the patches in arriving videos by resorting to random masking strategies, thereby wasting computations on predicting uninformative tokens/frames. To tackle these limitations of Masked Video Modeling, we propose a new token selection method that masks our more important tokens according to the object's motions in an online manner, which we refer to as Motion-centric Token Selection. Further, we present a dynamic frame selection strategy that allows the model to focus on informative and causal frames with minimal redundancy. We validate our method over multiple benchmark and Ego4D datasets, showing that the pre-trained model using our proposed method significantly outperforms state-of-the-art VRL methods on downstream tasks, such as action recognition and object state change classification while largely reducing memory requirements during pre-training and fine-tuning.
Distortion-Aware Network Pruning and Feature Reuse for Real-time Video Segmentation
Jun 20, 2022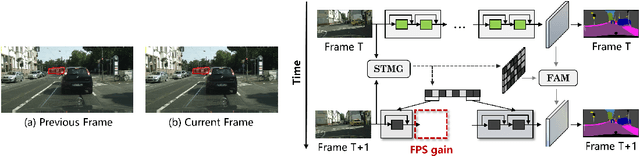
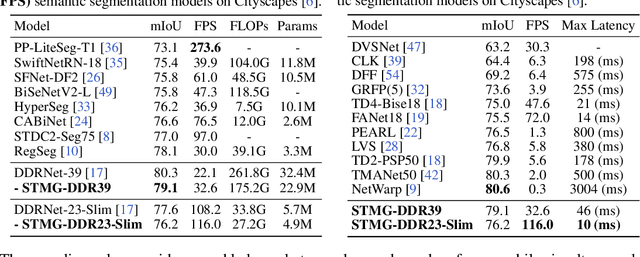
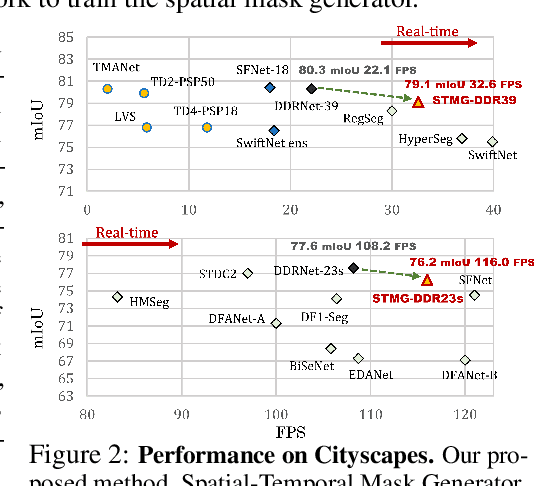
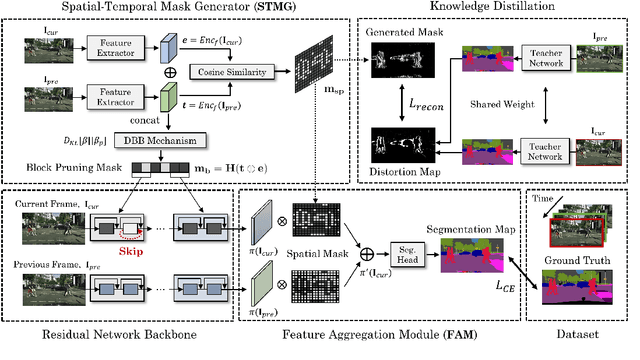
Real-time video segmentation is a crucial task for many real-world applications such as autonomous driving and robot control. Since state-of-the-art semantic segmentation models are often too heavy for real-time applications despite their impressive performance, researchers have proposed lightweight architectures with speed-accuracy trade-offs, achieving real-time speed at the expense of reduced accuracy. In this paper, we propose a novel framework to speed up any architecture with skip-connections for real-time vision tasks by exploiting the temporal locality in videos. Specifically, at the arrival of each frame, we transform the features from the previous frame to reuse them at specific spatial bins. We then perform partial computation of the backbone network on the regions of the current frame that captures temporal differences between the current and previous frame. This is done by dynamically dropping out residual blocks using a gating mechanism which decides which blocks to drop based on inter-frame distortion. We validate our Spatial-Temporal Mask Generator (STMG) on video semantic segmentation benchmarks with multiple backbone networks, and show that our method largely speeds up inference with minimal loss of accuracy.