 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMitigating Trade-off: Stream and Query-guided Aggregation for Efficient and Effective 3D Occupancy Prediction
Mar 28, 2025



3D occupancy prediction has emerged as a key perception task for autonomous driving, as it reconstructs 3D environments to provide a comprehensive scene understanding. Recent studies focus on integrating spatiotemporal information obtained from past observations to improve prediction accuracy, using a multi-frame fusion approach that processes multiple past frames together. However, these methods struggle with a trade-off between efficiency and accuracy, which significantly limits their practicality. To mitigate this trade-off, we propose StreamOcc, a novel framework that aggregates spatio-temporal information in a stream-based manner. StreamOcc consists of two key components: (i) Stream-based Voxel Aggregation, which effectively accumulates past observations while minimizing computational costs, and (ii) Query-guided Aggregation, which recurrently aggregates instance-level features of dynamic objects into corresponding voxel features, refining fine-grained details of dynamic objects. Experiments on the Occ3D-nuScenes dataset show that StreamOcc achieves state-of-the-art performance in real-time settings, while reducing memory usage by more than 50% compared to previous methods.
Addressing Diverging Training Costs using Local Restoration for Precise Bird's Eye View Map Construction
May 02, 2024Recent advancements in Bird's Eye View (BEV) fusion for map construction have demonstrated remarkable mapping of urban environments. However, their deep and bulky architecture incurs substantial amounts of backpropagation memory and computing latency. Consequently, the problem poses an unavoidable bottleneck in constructing high-resolution (HR) BEV maps, as their large-sized features cause significant increases in costs including GPU memory consumption and computing latency, named diverging training costs issue. Affected by the problem, most existing methods adopt low-resolution (LR) BEV and struggle to estimate the precise locations of urban scene components like road lanes, and sidewalks. As the imprecision leads to risky self-driving, the diverging training costs issue has to be resolved. In this paper, we address the issue with our novel Trumpet Neural Network (TNN) mechanism. The framework utilizes LR BEV space and outputs an up-sampled semantic BEV map to create a memory-efficient pipeline. To this end, we introduce Local Restoration of BEV representation. Specifically, the up-sampled BEV representation has severely aliased, blocky signals, and thick semantic labels. Our proposed Local Restoration restores the signals and thins (or narrows down) the width of the labels. Our extensive experiments show that the TNN mechanism provides a plug-and-play memory-efficient pipeline, thereby enabling the effective estimation of real-sized (or precise) semantic labels for BEV map construction.
BroadBEV: Collaborative LiDAR-camera Fusion for Broad-sighted Bird's Eye View Map Construction
Sep 25, 2023A recent sensor fusion in a Bird's Eye View (BEV) space has shown its utility in various tasks such as 3D detection, map segmentation, etc. However, the approach struggles with inaccurate camera BEV estimation, and a perception of distant areas due to the sparsity of LiDAR points. In this paper, we propose a broad BEV fusion (BroadBEV) that addresses the problems with a spatial synchronization approach of cross-modality. Our strategy aims to enhance camera BEV estimation for a broad-sighted perception while simultaneously improving the completion of LiDAR's sparsity in the entire BEV space. Toward that end, we devise Point-scattering that scatters LiDAR BEV distribution to camera depth distribution. The method boosts the learning of depth estimation of the camera branch and induces accurate location of dense camera features in BEV space. For an effective BEV fusion between the spatially synchronized features, we suggest ColFusion that applies self-attention weights of LiDAR and camera BEV features to each other. Our extensive experiments demonstrate that BroadBEV provides a broad-sighted BEV perception with remarkable performance gains.
Scan Context++: Structural Place Recognition Robust to Rotation and Lateral Variations in Urban Environments
Sep 28, 2021
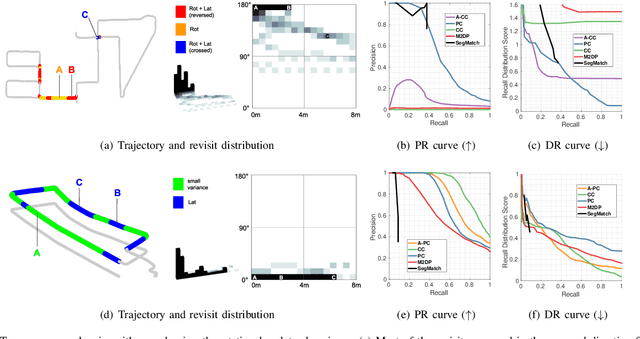
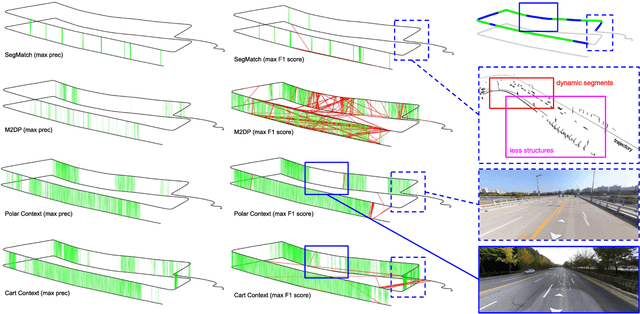
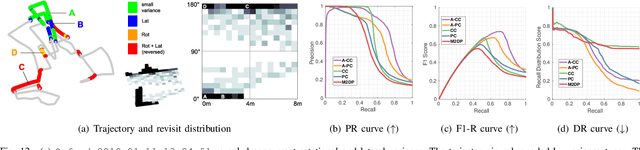
Place recognition is a key module in robotic navigation. The existing line of studies mostly focuses on visual place recognition to recognize previously visited places solely based on their appearance. In this paper, we address structural place recognition by recognizing a place based on structural appearance, namely from range sensors. Extending our previous work on a rotation invariant spatial descriptor, the proposed descriptor completes a generic descriptor robust to both rotation (heading) and translation when roll-pitch motions are not severe. We introduce two sub-descriptors and enable topological place retrieval followed by the 1-DOF semi-metric localization thereby bridging the gap between topological place retrieval and metric localization. The proposed method has been evaluated thoroughly in terms of environmental complexity and scale. The source code is available and can easily be integrated into existing LiDAR simultaneous localization and mapping (SLAM).