 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Physical Interaction Skills from Human Demonstrations
Jul 28, 2025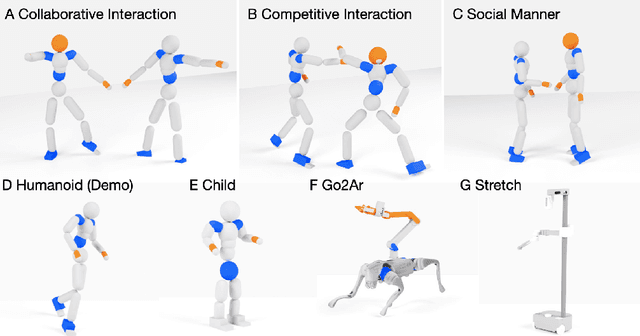
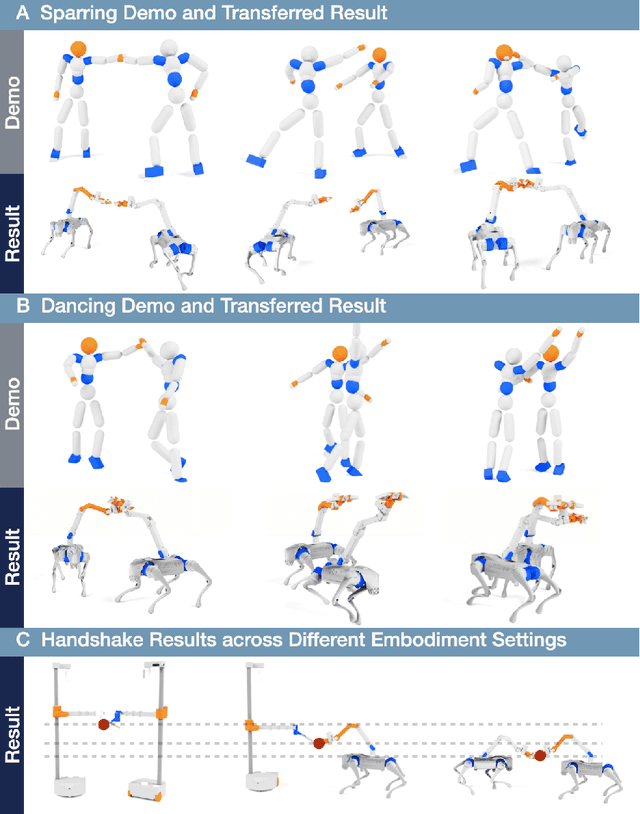
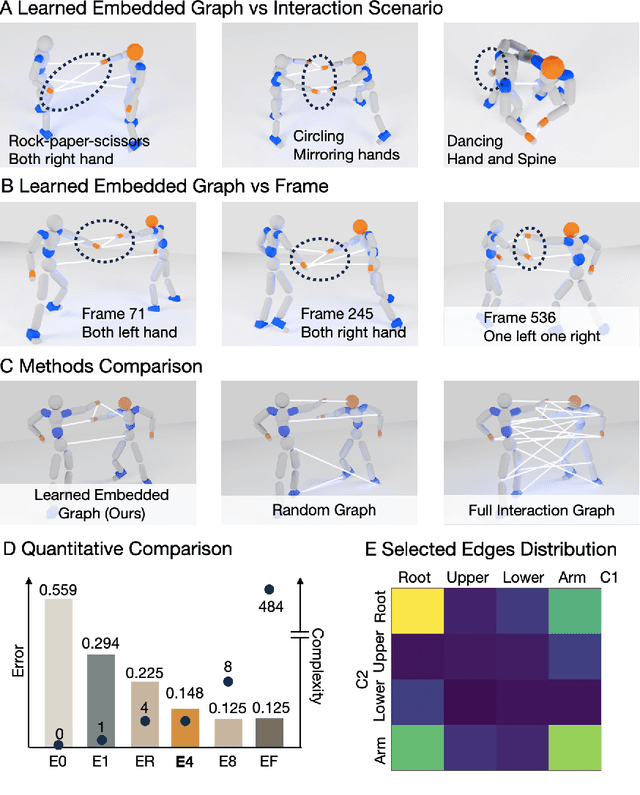
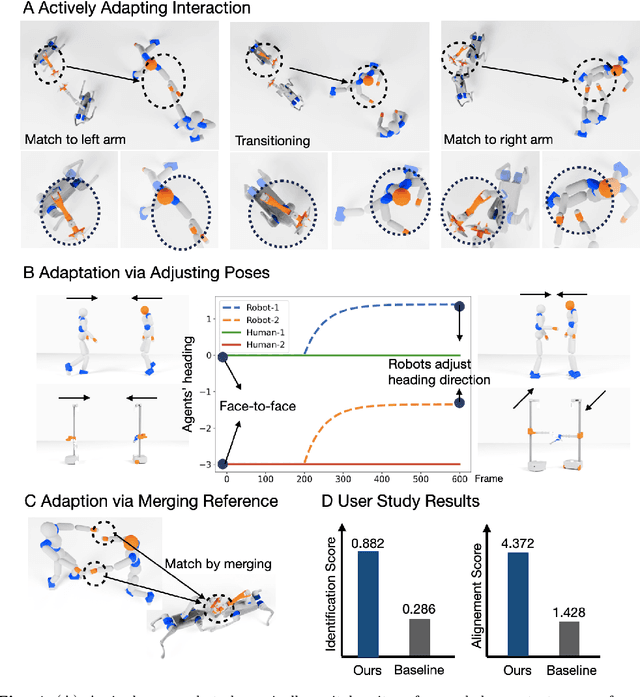
Learning physical interaction skills, such as dancing, handshaking, or sparring, remains a fundamental challenge for agents operating in human environments, particularly when the agent's morphology differs significantly from that of the demonstrator. Existing approaches often rely on handcrafted objectives or morphological similarity, limiting their capacity for generalization. Here, we introduce a framework that enables agents with diverse embodiments to learn wholebbody interaction behaviors directly from human demonstrations. The framework extracts a compact, transferable representation of interaction dynamics, called the Embedded Interaction Graph (EIG), which captures key spatiotemporal relationships between the interacting agents. This graph is then used as an imitation objective to train control policies in physics-based simulations, allowing the agent to generate motions that are both semantically meaningful and physically feasible. We demonstrate BuddyImitation on multiple agents, such as humans, quadrupedal robots with manipulators, or mobile manipulators and various interaction scenarios, including sparring, handshaking, rock-paper-scissors, or dancing. Our results demonstrate a promising path toward coordinated behaviors across morphologically distinct characters via cross embodiment interaction learning.
Estimating Ego-Body Pose from Doubly Sparse Egocentric Video Data
Nov 05, 2024



We study the problem of estimating the body movements of a camera wearer from egocentric videos. Current methods for ego-body pose estimation rely on temporally dense sensor data, such as IMU measurements from spatially sparse body parts like the head and hands. However, we propose that even temporally sparse observations, such as hand poses captured intermittently from egocentric videos during natural or periodic hand movements, can effectively constrain overall body motion. Naively applying diffusion models to generate full-body pose from head pose and sparse hand pose leads to suboptimal results. To overcome this, we develop a two-stage approach that decomposes the problem into temporal completion and spatial completion. First, our method employs masked autoencoders to impute hand trajectories by leveraging the spatiotemporal correlations between the head pose sequence and intermittent hand poses, providing uncertainty estimates. Subsequently, we employ conditional diffusion models to generate plausible full-body motions based on these temporally dense trajectories of the head and hands, guided by the uncertainty estimates from the imputation. The effectiveness of our method was rigorously tested and validated through comprehensive experiments conducted on various HMD setup with AMASS and Ego-Exo4D datasets.
M2D2M: Multi-Motion Generation from Text with Discrete Diffusion Models
Jul 19, 2024



We introduce the Multi-Motion Discrete Diffusion Models (M2D2M), a novel approach for human motion generation from textual descriptions of multiple actions, utilizing the strengths of discrete diffusion models. This approach adeptly addresses the challenge of generating multi-motion sequences, ensuring seamless transitions of motions and coherence across a series of actions. The strength of M2D2M lies in its dynamic transition probability within the discrete diffusion model, which adapts transition probabilities based on the proximity between motion tokens, encouraging mixing between different modes. Complemented by a two-phase sampling strategy that includes independent and joint denoising steps, M2D2M effectively generates long-term, smooth, and contextually coherent human motion sequences, utilizing a model trained for single-motion generation. Extensive experiments demonstrate that M2D2M surpasses current state-of-the-art benchmarks for motion generation from text descriptions, showcasing its efficacy in interpreting language semantics and generating dynamic, realistic motions.
CMP: Cooperative Motion Prediction with Multi-Agent Communication
Mar 26, 2024
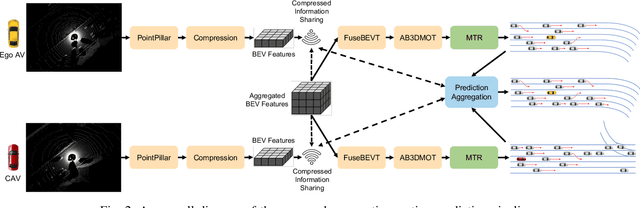
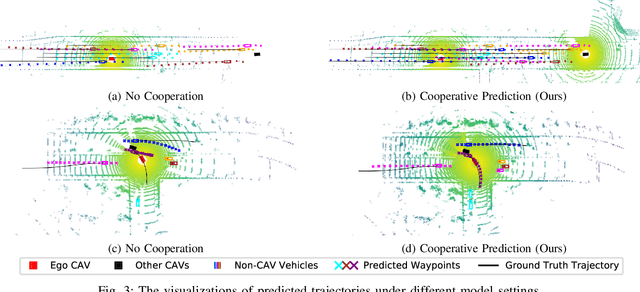
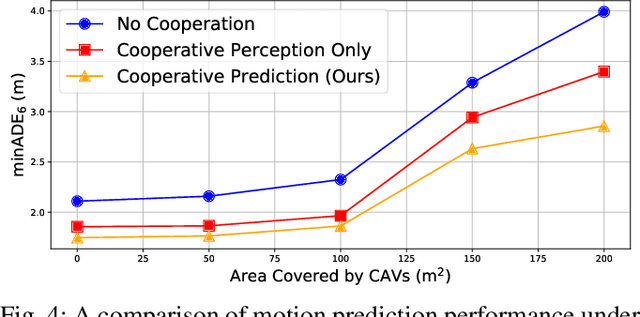
The confluence of the advancement of Autonomous Vehicles (AVs) and the maturity of Vehicle-to-Everything (V2X) communication has enabled the capability of cooperative connected and automated vehicles (CAVs). Building on top of cooperative perception, this paper explores the feasibility and effectiveness of cooperative motion prediction. Our method, CMP, takes LiDAR signals as input to enhance tracking and prediction capabilities. Unlike previous work that focuses separately on either cooperative perception or motion prediction, our framework, to the best of our knowledge, is the first to address the unified problem where CAVs share information in both perception and prediction modules. Incorporated into our design is the unique capability to tolerate realistic V2X bandwidth limitations and transmission delays, while dealing with bulky perception representations. We also propose a prediction aggregation module, which unifies the predictions obtained by different CAVs and generates the final prediction. Through extensive experiments and ablation studies, we demonstrate the effectiveness of our method in cooperative perception, tracking, and motion prediction tasks. In particular, CMP reduces the average prediction error by 17.2\% with fewer missing detections compared with the no cooperation setting. Our work marks a significant step forward in the cooperative capabilities of CAVs, showcasing enhanced performance in complex scenarios.
Multi-Agent Dynamic Relational Reasoning for Social Robot Navigation
Jan 22, 2024Social robot navigation can be helpful in various contexts of daily life but requires safe human-robot interactions and efficient trajectory planning. While modeling pairwise relations has been widely studied in multi-agent interacting systems, the ability to capture larger-scale group-wise activities is limited. In this paper, we propose a systematic relational reasoning approach with explicit inference of the underlying dynamically evolving relational structures, and we demonstrate its effectiveness for multi-agent trajectory prediction and social robot navigation. In addition to the edges between pairs of nodes (i.e., agents), we propose to infer hyperedges that adaptively connect multiple nodes to enable group-wise reasoning in an unsupervised manner. Our approach infers dynamically evolving relation graphs and hypergraphs to capture the evolution of relations, which the trajectory predictor employs to generate future states. Meanwhile, we propose to regularize the sharpness and sparsity of the learned relations and the smoothness of the relation evolution, which proves to enhance training stability and model performance. The proposed approach is validated on synthetic crowd simulations and real-world benchmark datasets. Experiments demonstrate that the approach infers reasonable relations and achieves state-of-the-art prediction performance. In addition, we present a deep reinforcement learning (DRL) framework for social robot navigation, which incorporates relational reasoning and trajectory prediction systematically. In a group-based crowd simulation, our method outperforms the strongest baseline by a significant margin in terms of safety, efficiency, and social compliance in dense, interactive scenarios.
SkillDiffuser: Interpretable Hierarchical Planning via Skill Abstractions in Diffusion-Based Task Execution
Dec 18, 2023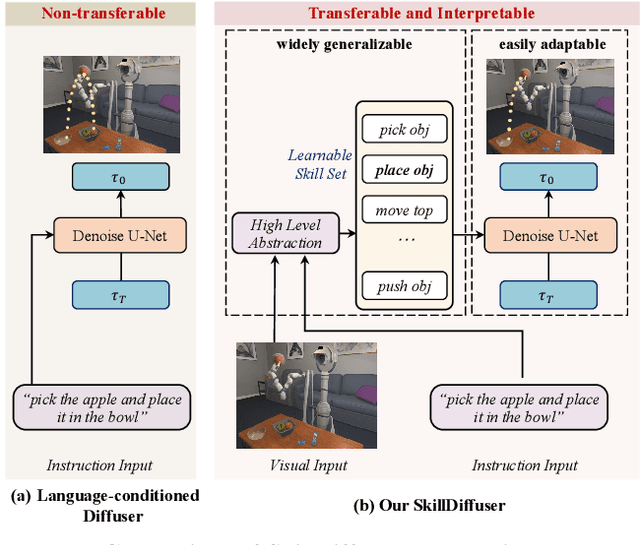
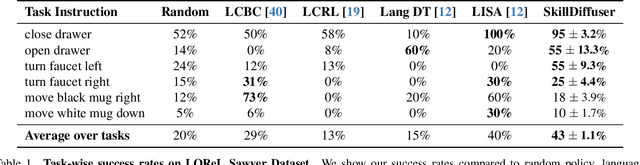
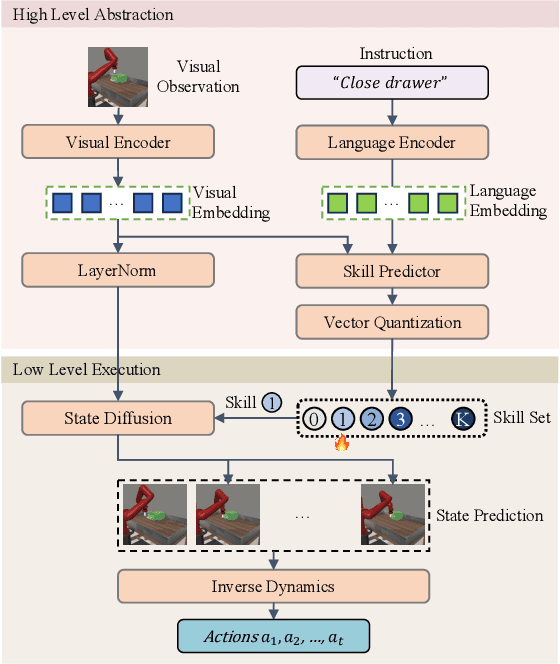
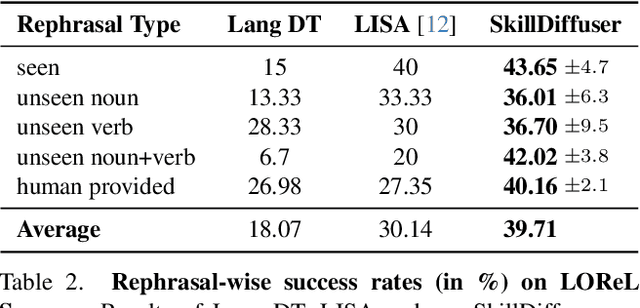
Diffusion models have demonstrated strong potential for robotic trajectory planning. However, generating coherent and long-horizon trajectories from high-level instructions remains challenging, especially for complex tasks requiring multiple sequential skills. We propose SkillDiffuser, an end-to-end hierarchical planning framework integrating interpretable skill learning with conditional diffusion planning to address this problem. At the higher level, the skill abstraction module learns discrete, human-understandable skill representations from visual observations and language instructions. These learned skill embeddings are then used to condition the diffusion model to generate customized latent trajectories aligned with the skills. It allows for generating diverse state trajectories that adhere to the learnable skills. By integrating skill learning with conditional trajectory generation, SkillDiffuser produces coherent behavior following abstract instructions across diverse tasks. Experiments on multi-task robotic manipulation benchmarks like Meta-World and LOReL demonstrate state-of-the-art performance and human-interpretable skill representations from SkillDiffuser.
Learning Physical Dynamics with Subequivariant Graph Neural Networks
Oct 13, 2022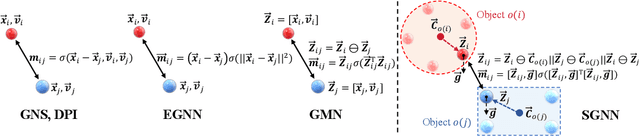
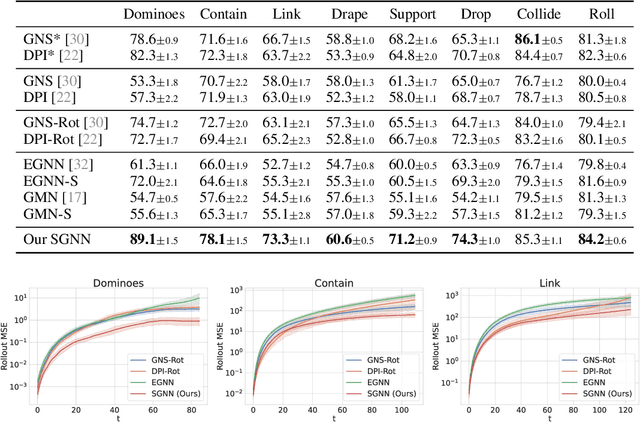
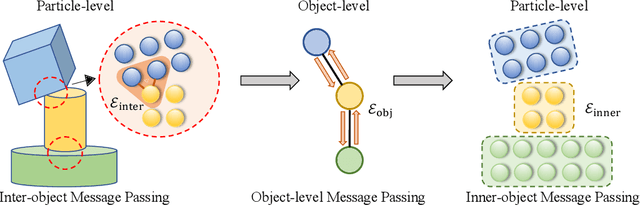
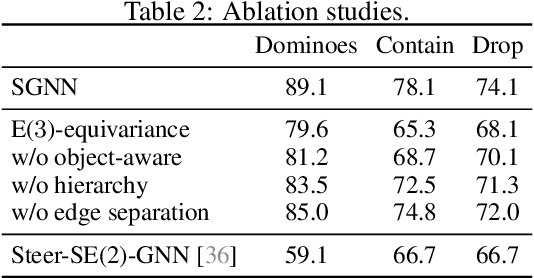
Graph Neural Networks (GNNs) have become a prevailing tool for learning physical dynamics. However, they still encounter several challenges: 1) Physical laws abide by symmetry, which is a vital inductive bias accounting for model generalization and should be incorporated into the model design. Existing simulators either consider insufficient symmetry, or enforce excessive equivariance in practice when symmetry is partially broken by gravity. 2) Objects in the physical world possess diverse shapes, sizes, and properties, which should be appropriately processed by the model. To tackle these difficulties, we propose a novel backbone, Subequivariant Graph Neural Network, which 1) relaxes equivariance to subequivariance by considering external fields like gravity, where the universal approximation ability holds theoretically; 2) introduces a new subequivariant object-aware message passing for learning physical interactions between multiple objects of various shapes in the particle-based representation; 3) operates in a hierarchical fashion, allowing for modeling long-range and complex interactions. Our model achieves on average over 3% enhancement in contact prediction accuracy across 8 scenarios on Physion and 2X lower rollout MSE on RigidFall compared with state-of-the-art GNN simulators, while exhibiting strong generalization and data efficiency.
EvolveHypergraph: Group-Aware Dynamic Relational Reasoning for Trajectory Prediction
Aug 10, 2022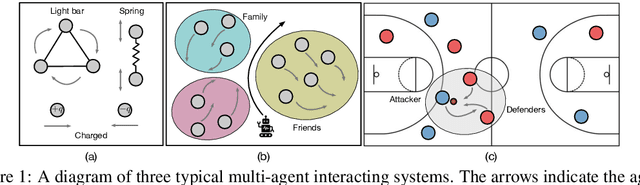
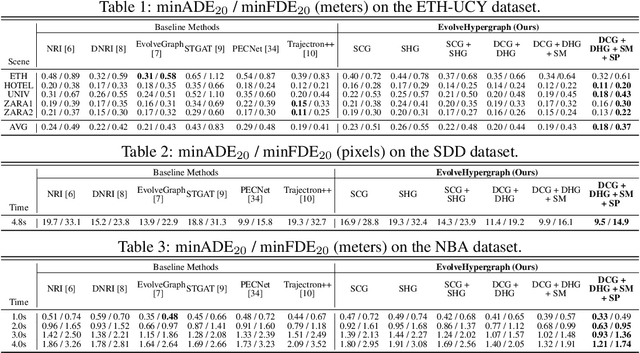
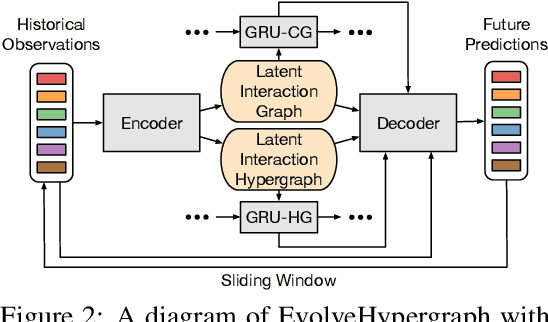
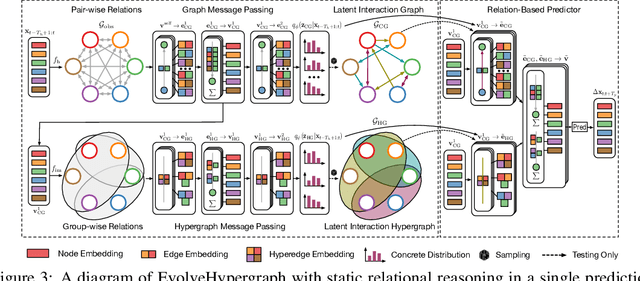
While the modeling of pair-wise relations has been widely studied in multi-agent interacting systems, its ability to capture higher-level and larger-scale group-wise activities is limited. In this paper, we propose a group-aware relational reasoning approach (named EvolveHypergraph) with explicit inference of the underlying dynamically evolving relational structures, and we demonstrate its effectiveness for multi-agent trajectory prediction. In addition to the edges between a pair of nodes (i.e., agents), we propose to infer hyperedges that adaptively connect multiple nodes to enable group-aware relational reasoning in an unsupervised manner without fixing the number of hyperedges. The proposed approach infers the dynamically evolving relation graphs and hypergraphs over time to capture the evolution of relations, which are used by the trajectory predictor to obtain future states. Moreover, we propose to regularize the smoothness of the relation evolution and the sparsity of the inferred graphs or hypergraphs, which effectively improves training stability and enhances the explainability of inferred relations. The proposed approach is validated on both synthetic crowd simulations and multiple real-world benchmark datasets. Our approach infers explainable, reasonable group-aware relations and achieves state-of-the-art performance in long-term prediction.
Important Object Identification with Semi-Supervised Learning for Autonomous Driving
Mar 05, 2022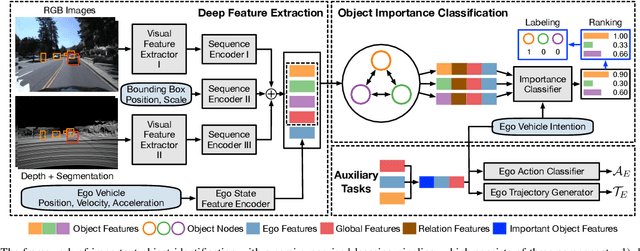
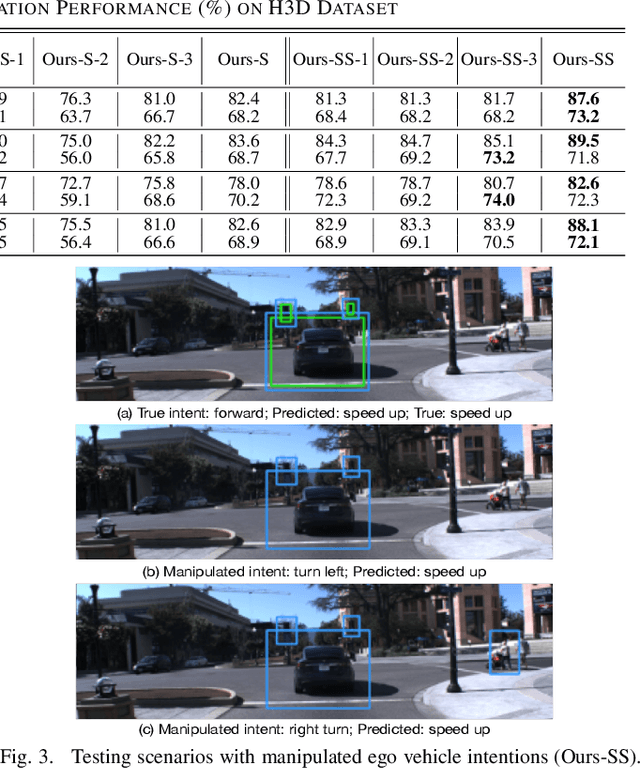
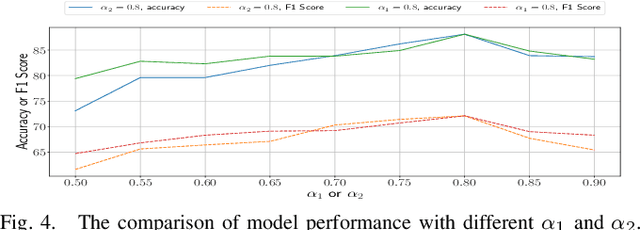
Accurate identification of important objects in the scene is a prerequisite for safe and high-quality decision making and motion planning of intelligent agents (e.g., autonomous vehicles) that navigate in complex and dynamic environments. Most existing approaches attempt to employ attention mechanisms to learn importance weights associated with each object indirectly via various tasks (e.g., trajectory prediction), which do not enforce direct supervision on the importance estimation. In contrast, we tackle this task in an explicit way and formulate it as a binary classification ("important" or "unimportant") problem. We propose a novel approach for important object identification in egocentric driving scenarios with relational reasoning on the objects in the scene. Besides, since human annotations are limited and expensive to obtain, we present a semi-supervised learning pipeline to enable the model to learn from unlimited unlabeled data. Moreover, we propose to leverage the auxiliary tasks of ego vehicle behavior prediction to further improve the accuracy of importance estimation. The proposed approach is evaluated on a public egocentric driving dataset (H3D) collected in complex traffic scenarios. A detailed ablative study is conducted to demonstrate the effectiveness of each model component and the training strategy. Our approach also outperforms rule-based baselines by a large margin.
Learning Differentiable Safety-Critical Control using Control Barrier Functions for Generalization to Novel Environments
Jan 07, 2022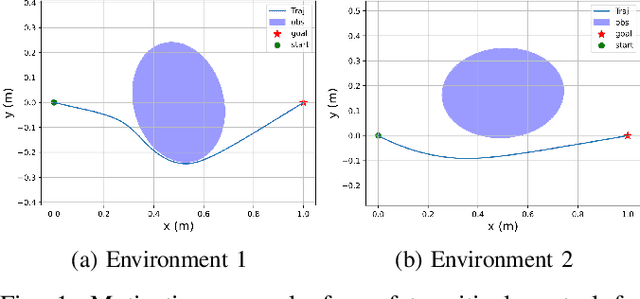
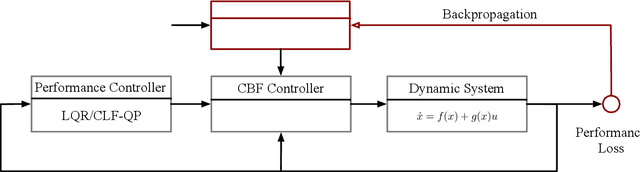
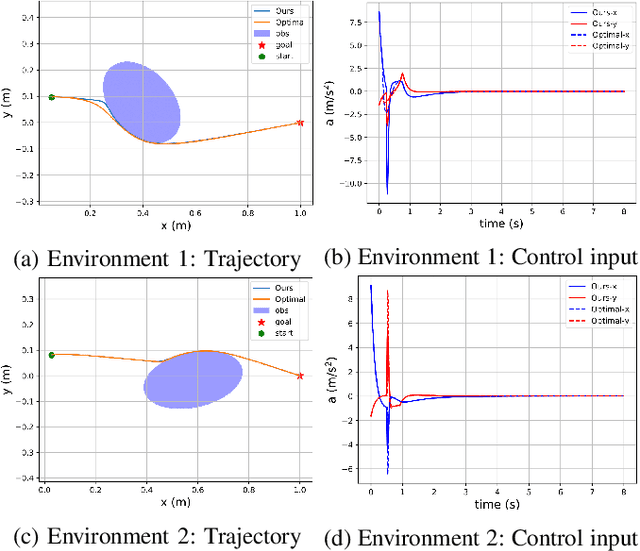
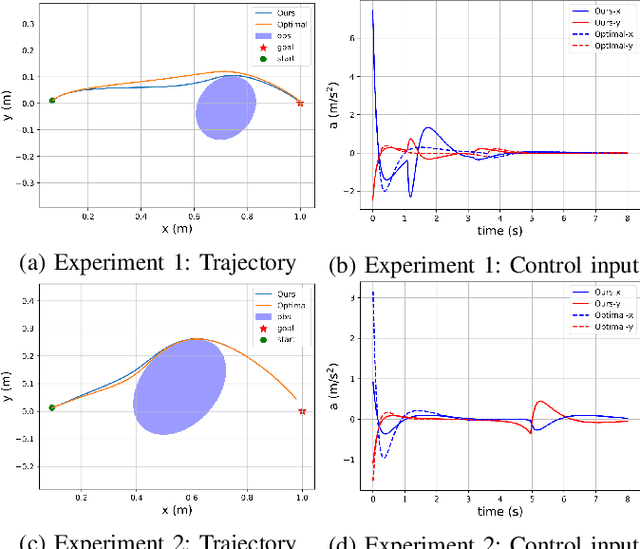
Control barrier functions (CBFs) have become a popular tool to enforce safety of a control system. CBFs are commonly utilized in a quadratic program formulation (CBF-QP) as safety-critical constraints. A class $\mathcal{K}$ function in CBFs usually needs to be tuned manually in order to balance the trade-off between performance and safety for each environment. However, this process is often heuristic and can become intractable for high relative-degree systems. Moreover, it prevents the CBF-QP from generalizing to different environments in the real world. By embedding the optimization procedure of the CBF-QP as a differentiable layer within a deep learning architecture, we propose a differentiable optimization-based safety-critical control framework that enables generalization to new environments with forward invariance guarantees. Finally, we validate the proposed control design with 2D double and quadruple integrator systems in various environments.