 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSkillDiffuser: Interpretable Hierarchical Planning via Skill Abstractions in Diffusion-Based Task Execution
Paper and Code
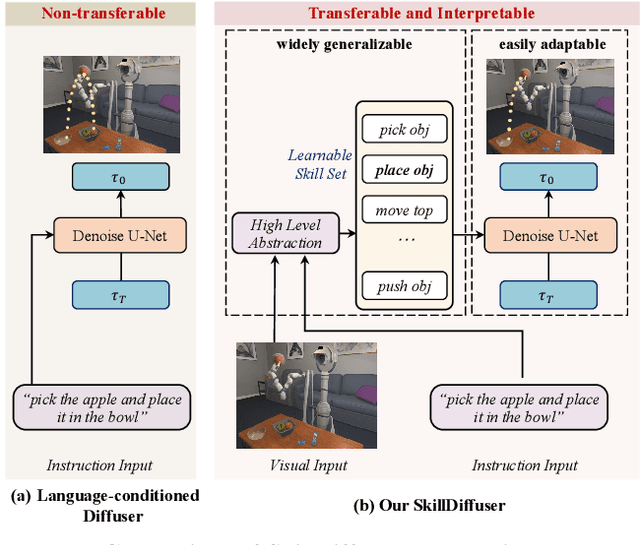
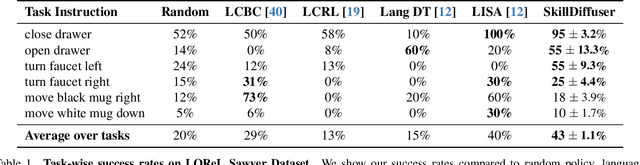
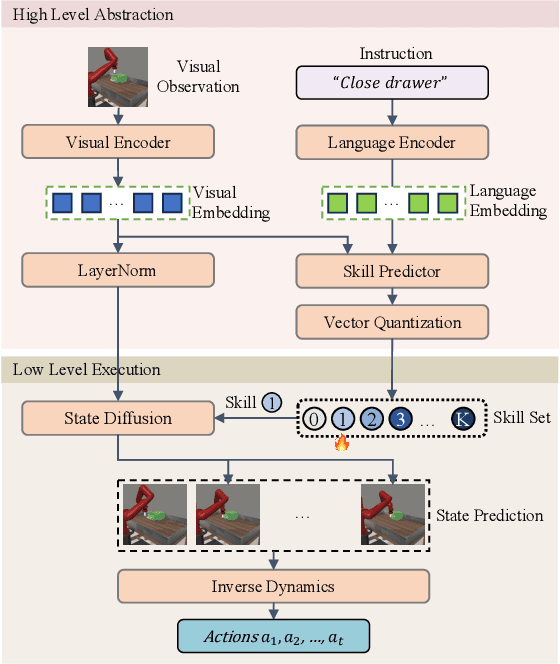
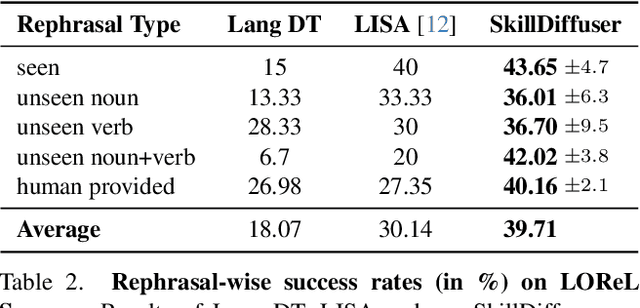
Diffusion models have demonstrated strong potential for robotic trajectory planning. However, generating coherent and long-horizon trajectories from high-level instructions remains challenging, especially for complex tasks requiring multiple sequential skills. We propose SkillDiffuser, an end-to-end hierarchical planning framework integrating interpretable skill learning with conditional diffusion planning to address this problem. At the higher level, the skill abstraction module learns discrete, human-understandable skill representations from visual observations and language instructions. These learned skill embeddings are then used to condition the diffusion model to generate customized latent trajectories aligned with the skills. It allows for generating diverse state trajectories that adhere to the learnable skills. By integrating skill learning with conditional trajectory generation, SkillDiffuser produces coherent behavior following abstract instructions across diverse tasks. Experiments on multi-task robotic manipulation benchmarks like Meta-World and LOReL demonstrate state-of-the-art performance and human-interpretable skill representations from SkillDiffuser.