 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOrdered Local Momentum for Asynchronous Distributed Learning under Arbitrary Delays
Jan 18, 2026Momentum SGD (MSGD) serves as a foundational optimizer in training deep models due to momentum's key role in accelerating convergence and enhancing generalization. Meanwhile, asynchronous distributed learning is crucial for training large-scale deep models, especially when the computing capabilities of the workers in the cluster are heterogeneous. To reduce communication frequency, local updates are widely adopted in distributed learning. However, how to implement asynchronous distributed MSGD with local updates remains unexplored. To solve this problem, we propose a novel method, called \underline{or}dered \underline{lo}cal \underline{mo}mentum (OrLoMo), for asynchronous distributed learning. In OrLoMo, each worker runs MSGD locally. Then the local momentum from each worker will be aggregated by the server in order based on its global iteration index. To the best of our knowledge, OrLoMo is the first method to implement asynchronous distributed MSGD with local updates. We prove the convergence of OrLoMo for non-convex problems under arbitrary delays. Experiments validate that OrLoMo can outperform its synchronous counterpart and other asynchronous methods.
From Supervision to Exploration: What Does Protein Language Model Learn During Reinforcement Learning?
Oct 02, 2025Protein language models (PLMs) have advanced computational protein science through large-scale pretraining and scalable architectures. In parallel, reinforcement learning (RL) has broadened exploration and enabled precise multi-objective optimization in protein design. Yet whether RL can push PLMs beyond their pretraining priors to uncover latent sequence-structure-function rules remains unclear. We address this by pairing RL with PLMs across four domains: antimicrobial peptide design, kinase variant optimization, antibody engineering, and inverse folding. Using diverse RL algorithms and model classes, we ask if RL improves sampling efficiency and, more importantly, if it reveals capabilities not captured by supervised learning. Across benchmarks, RL consistently boosts success rates and sample efficiency. Performance follows a three-factor interaction: task headroom, reward fidelity, and policy capacity jointly determine gains. When rewards are accurate and informative, policies have sufficient capacity, and tasks leave room beyond supervised baselines, improvements scale; when rewards are noisy or capacity is constrained, gains saturate despite exploration. This view yields practical guidance for RL in protein design: prioritize reward modeling and calibration before scaling policy size, match algorithm and regularization strength to task difficulty, and allocate capacity where marginal gains are largest. Implementation is available at https://github.com/chq1155/RL-PLM.
Gated Integration of Low-Rank Adaptation for Continual Learning of Language Models
May 21, 2025Continual learning (CL), which requires the model to learn multiple tasks sequentially, is crucial for language models (LMs). Recently, low-rank adaptation (LoRA), one of the most representative parameter-efficient fine-tuning (PEFT) methods, has gained increasing attention in CL of LMs. However, most existing CL methods based on LoRA typically expand a new LoRA branch to learn each new task and force the new and old LoRA branches to contribute equally to old tasks, potentially leading to forgetting. In this work, we propose a new method, called gated integration of low-rank adaptation (GainLoRA), for CL of LMs. GainLoRA expands a new LoRA branch for each new task and introduces gating modules to integrate the new and old LoRA branches. Furthermore, GainLoRA leverages the new gating module to minimize the contribution from the new LoRA branch to old tasks, effectively mitigating forgetting and improving the model's overall performance. Experimental results on CL benchmarks demonstrate that GainLoRA outperforms existing state-of-the-art methods.
PoseX: AI Defeats Physics Approaches on Protein-Ligand Cross Docking
May 03, 2025Recently, significant progress has been made in protein-ligand docking, especially in modern deep learning methods, and some benchmarks were proposed, e.g., PoseBench, Plinder. However, these benchmarks suffer from less practical evaluation setups (e.g., blind docking, self docking), or heavy framework that involves training, raising challenges to assess docking methods efficiently. To fill this gap, we proposed PoseX, an open-source benchmark focusing on self-docking and cross-docking, to evaluate the algorithmic advances practically and comprehensively. Specifically, first, we curate a new evaluation dataset with 718 entries for self docking and 1,312 for cross docking; second, we incorporate 22 docking methods across three methodological categories, including (1) traditional physics-based methods (e.g., Schr\"odinger Glide), (2) AI docking methods (e.g., DiffDock), (3) AI co-folding methods (e.g., AlphaFold3); third, we design a relaxation method as post-processing to minimize conformation energy and refine binding pose; fourth, we released a leaderboard to rank submitted models in real time. We draw some key insights via extensive experiments: (1) AI-based approaches have already surpassed traditional physics-based approaches in overall docking accuracy (RMSD). The longstanding generalization issues that have plagued AI molecular docking have been significantly alleviated in the latest models. (2) The stereochemical deficiencies of AI-based approaches can be greatly alleviated with post-processing relaxation. Combining AI docking methods with the enhanced relaxation method achieves the best performance to date. (3) AI co-folding methods commonly face ligand chirality issues, which cannot be resolved by relaxation. The code, curated dataset and leaderboard are released at https://github.com/CataAI/PoseX.
TimeDP: Learning to Generate Multi-Domain Time Series with Domain Prompts
Jan 09, 2025



Time series generation models are crucial for applications like data augmentation and privacy preservation. Most existing time series generation models are typically designed to generate data from one specified domain. While leveraging data from other domain for better generalization is proved to work in other application areas, this approach remains challenging for time series modeling due to the large divergence in patterns among different real world time series categories. In this paper, we propose a multi-domain time series diffusion model with domain prompts, named TimeDP. In TimeDP, we utilize a time series semantic prototype module which defines time series prototypes to represent time series basis, each prototype vector serving as "word" representing some elementary time series feature. A prototype assignment module is applied to extract the extract domain specific prototype weights, for learning domain prompts as generation condition. During sampling, we extract "domain prompt" with few-shot samples from the target domain and use the domain prompts as condition to generate time series samples. Experiments demonstrate that our method outperforms baselines to provide the state-of-the-art in-domain generation quality and strong unseen domain generation capability.
Hashing for Protein Structure Similarity Search
Nov 13, 2024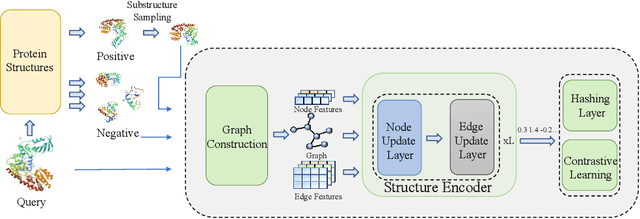
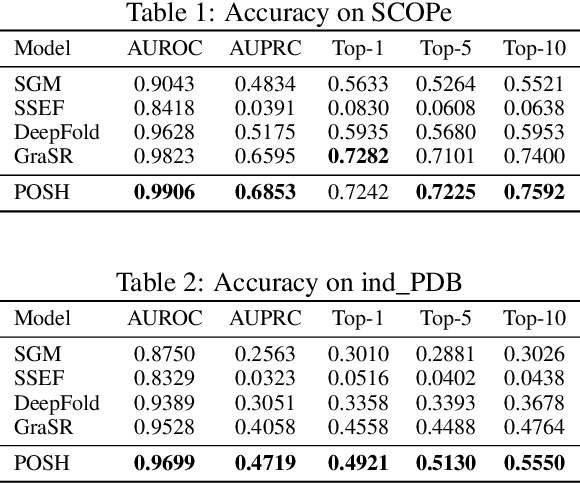
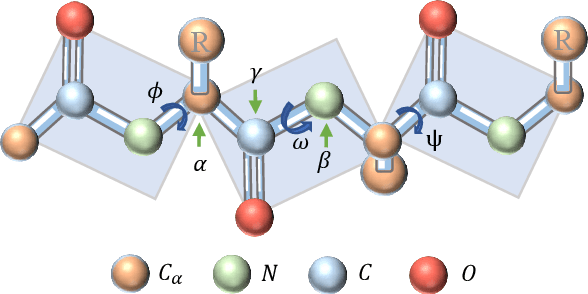
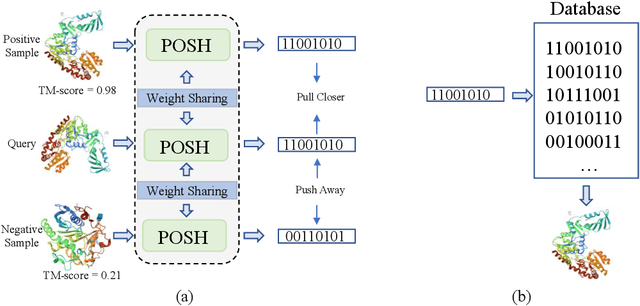
Protein structure similarity search (PSSS), which tries to search proteins with similar structures, plays a crucial role across diverse domains from drug design to protein function prediction and molecular evolution. Traditional alignment-based PSSS methods, which directly calculate alignment on the protein structures, are highly time-consuming with high memory cost. Recently, alignment-free methods, which represent protein structures as fixed-length real-valued vectors, are proposed for PSSS. Although these methods have lower time and memory cost than alignment-based methods, their time and memory cost is still too high for large-scale PSSS, and their accuracy is unsatisfactory. In this paper, we propose a novel method, called $\underline{\text{p}}$r$\underline{\text{o}}$tein $\underline{\text{s}}$tructure $\underline{\text{h}}$ashing (POSH), for PSSS. POSH learns a binary vector representation for each protein structure, which can dramatically reduce the time and memory cost for PSSS compared with real-valued vector representation based methods. Furthermore, in POSH we also propose expressive hand-crafted features and a structure encoder to well model both node and edge interactions in proteins. Experimental results on real datasets show that POSH can outperform other methods to achieve state-of-the-art accuracy. Furthermore, POSH achieves a memory saving of more than six times and speed improvement of more than four times, compared with other methods.
Hashing based Contrastive Learning for Virtual Screening
Jul 29, 2024Virtual screening (VS) is a critical step in computer-aided drug discovery, aiming to identify molecules that bind to a specific target receptor like protein. Traditional VS methods, such as docking, are often too time-consuming for screening large-scale molecular databases. Recent advances in deep learning have demonstrated that learning vector representations for both proteins and molecules using contrastive learning can outperform traditional docking methods. However, given that target databases often contain billions of molecules, real-valued vector representations adopted by existing methods can still incur significant memory and time costs in VS. To address this problem, in this paper we propose a hashing-based contrastive learning method, called DrugHash, for VS. DrugHash treats VS as a retrieval task that uses efficient binary hash codes for retrieval. In particular, DrugHash designs a simple yet effective hashing strategy to enable end-to-end learning of binary hash codes for both protein and molecule modalities, which can dramatically reduce the memory and time costs with higher accuracy compared with existing methods. Experimental results show that DrugHash can outperform existing methods to achieve state-of-the-art accuracy, with a memory saving of 32$\times$ and a speed improvement of 3.5$\times$.
Ordered Momentum for Asynchronous SGD
Jul 27, 2024



Distributed learning is indispensable for training large-scale deep models. Asynchronous SGD~(ASGD) and its variants are commonly used distributed learning methods in many scenarios where the computing capabilities of workers in the cluster are heterogeneous. Momentum has been acknowledged for its benefits in both optimization and generalization in deep model training. However, existing works have found that naively incorporating momentum into ASGD can impede the convergence. In this paper, we propose a novel method, called ordered momentum (OrMo), for ASGD. In OrMo, momentum is incorporated into ASGD by organizing the gradients in order based on their iteration indexes. We theoretically prove the convergence of OrMo for non-convex problems. To the best of our knowledge, this is the first work to establish the convergence analysis of ASGD with momentum without relying on the bounded delay assumption. Empirical results demonstrate that OrMo can achieve better convergence performance compared with ASGD and other asynchronous methods with momentum.
Buffered Asynchronous Secure Aggregation for Cross-Device Federated Learning
Jun 05, 2024



Asynchronous federated learning (AFL) is an effective method to address the challenge of device heterogeneity in cross-device federated learning. However, AFL is usually incompatible with existing secure aggregation protocols used to protect user privacy in federated learning because most existing secure aggregation protocols are based on synchronous aggregation. To address this problem, we propose a novel secure aggregation protocol named buffered asynchronous secure aggregation (BASA) in this paper. Compared with existing protocols, BASA is fully compatible with AFL and provides secure aggregation under the condition that each user only needs one round of communication with the server without relying on any synchronous interaction among users. Based on BASA, we propose the first AFL method which achieves secure aggregation without extra requirements on hardware. We empirically demonstrate that BASA outperforms existing secure aggregation protocols for cross-device federated learning in terms of training efficiency and scalability.
LCQ: Low-Rank Codebook based Quantization for Large Language Models
May 31, 2024Large language models~(LLMs) have recently demonstrated promising performance in many tasks. However, the high storage and computational cost of LLMs has become a challenge for deploying LLMs. Weight quantization has been widely used for model compression, which can reduce both storage and computational cost. Most existing weight quantization methods for LLMs use a rank-one codebook for quantization, which results in substantial accuracy loss when the compression ratio is high. In this paper, we propose a novel weight quantization method, called low-rank codebook based quantization~(LCQ), for LLMs. LCQ adopts a low-rank codebook, the rank of which can be larger than one, for quantization. Experiments show that LCQ can achieve better accuracy than existing methods with a negligibly extra storage cost.