 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSciFig: Towards Automating Scientific Figure Generation
Jan 07, 2026Creating high-quality figures and visualizations for scientific papers is a time-consuming task that requires both deep domain knowledge and professional design skills. Despite over 2.5 million scientific papers published annually, the figure generation process remains largely manual. We introduce $\textbf{SciFig}$, an end-to-end AI agent system that generates publication-ready pipeline figures directly from research paper texts. SciFig uses a hierarchical layout generation strategy, which parses research descriptions to identify component relationships, groups related elements into functional modules, and generates inter-module connections to establish visual organization. Furthermore, an iterative chain-of-thought (CoT) feedback mechanism progressively improves layouts through multiple rounds of visual analysis and reasoning. We introduce a rubric-based evaluation framework that analyzes 2,219 real scientific figures to extract evaluation rubrics and automatically generates comprehensive evaluation criteria. SciFig demonstrates remarkable performance: achieving 70.1$\%$ overall quality on dataset-level evaluation and 66.2$\%$ on paper-specific evaluation, and consistently high scores across metrics such as visual clarity, structural organization, and scientific accuracy. SciFig figure generation pipeline and our evaluation benchmark will be open-sourced.
Towards more transferable adversarial attack in black-box manner
May 23, 2025Adversarial attacks have become a well-explored domain, frequently serving as evaluation baselines for model robustness. Among these, black-box attacks based on transferability have received significant attention due to their practical applicability in real-world scenarios. Traditional black-box methods have generally focused on improving the optimization framework (e.g., utilizing momentum in MI-FGSM) to enhance transferability, rather than examining the dependency on surrogate white-box model architectures. Recent state-of-the-art approach DiffPGD has demonstrated enhanced transferability by employing diffusion-based adversarial purification models for adaptive attacks. The inductive bias of diffusion-based adversarial purification aligns naturally with the adversarial attack process, where both involving noise addition, reducing dependency on surrogate white-box model selection. However, the denoising process of diffusion models incurs substantial computational costs through chain rule derivation, manifested in excessive VRAM consumption and extended runtime. This progression prompts us to question whether introducing diffusion models is necessary. We hypothesize that a model sharing similar inductive bias to diffusion-based adversarial purification, combined with an appropriate loss function, could achieve comparable or superior transferability while dramatically reducing computational overhead. In this paper, we propose a novel loss function coupled with a unique surrogate model to validate our hypothesis. Our approach leverages the score of the time-dependent classifier from classifier-guided diffusion models, effectively incorporating natural data distribution knowledge into the adversarial optimization process. Experimental results demonstrate significantly improved transferability across diverse model architectures while maintaining robustness against diffusion-based defenses.
My Face Is Mine, Not Yours: Facial Protection Against Diffusion Model Face Swapping
May 21, 2025The proliferation of diffusion-based deepfake technologies poses significant risks for unauthorized and unethical facial image manipulation. While traditional countermeasures have primarily focused on passive detection methods, this paper introduces a novel proactive defense strategy through adversarial attacks that preemptively protect facial images from being exploited by diffusion-based deepfake systems. Existing adversarial protection methods predominantly target conventional generative architectures (GANs, AEs, VAEs) and fail to address the unique challenges presented by diffusion models, which have become the predominant framework for high-quality facial deepfakes. Current diffusion-specific adversarial approaches are limited by their reliance on specific model architectures and weights, rendering them ineffective against the diverse landscape of diffusion-based deepfake implementations. Additionally, they typically employ global perturbation strategies that inadequately address the region-specific nature of facial manipulation in deepfakes.
T2ICount: Enhancing Cross-modal Understanding for Zero-Shot Counting
Feb 28, 2025



Zero-shot object counting aims to count instances of arbitrary object categories specified by text descriptions. Existing methods typically rely on vision-language models like CLIP, but often exhibit limited sensitivity to text prompts. We present T2ICount, a diffusion-based framework that leverages rich prior knowledge and fine-grained visual understanding from pretrained diffusion models. While one-step denoising ensures efficiency, it leads to weakened text sensitivity. To address this challenge, we propose a Hierarchical Semantic Correction Module that progressively refines text-image feature alignment, and a Representational Regional Coherence Loss that provides reliable supervision signals by leveraging the cross-attention maps extracted from the denosing U-Net. Furthermore, we observe that current benchmarks mainly focus on majority objects in images, potentially masking models' text sensitivity. To address this, we contribute a challenging re-annotated subset of FSC147 for better evaluation of text-guided counting ability. Extensive experiments demonstrate that our method achieves superior performance across different benchmarks. Code is available at https://github.com/cha15yq/T2ICount.
MMAD-Purify: A Precision-Optimized Framework for Efficient and Scalable Multi-Modal Attacks
Oct 17, 2024

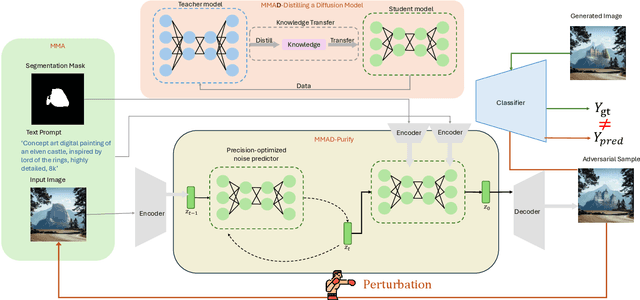
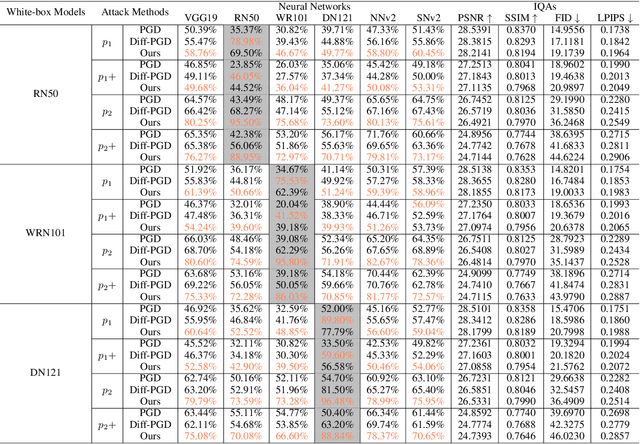
Neural networks have achieved remarkable performance across a wide range of tasks, yet they remain susceptible to adversarial perturbations, which pose significant risks in safety-critical applications. With the rise of multimodality, diffusion models have emerged as powerful tools not only for generative tasks but also for various applications such as image editing, inpainting, and super-resolution. However, these models still lack robustness due to limited research on attacking them to enhance their resilience. Traditional attack techniques, such as gradient-based adversarial attacks and diffusion model-based methods, are hindered by computational inefficiencies and scalability issues due to their iterative nature. To address these challenges, we introduce an innovative framework that leverages the distilled backbone of diffusion models and incorporates a precision-optimized noise predictor to enhance the effectiveness of our attack framework. This approach not only enhances the attack's potency but also significantly reduces computational costs. Our framework provides a cutting-edge solution for multi-modal adversarial attacks, ensuring reduced latency and the generation of high-fidelity adversarial examples with superior success rates. Furthermore, we demonstrate that our framework achieves outstanding transferability and robustness against purification defenses, outperforming existing gradient-based attack models in both effectiveness and efficiency.
Instant Adversarial Purification with Adversarial Consistency Distillation
Sep 02, 2024



Neural networks, despite their remarkable performance in widespread applications, including image classification, are also known to be vulnerable to subtle adversarial noise. Although some diffusion-based purification methods have been proposed, for example, DiffPure, those methods are time-consuming. In this paper, we propose One Step Control Purification (OSCP), a diffusion-based purification model that can purify the adversarial image in one Neural Function Evaluation (NFE) in diffusion models. We use Latent Consistency Model (LCM) and ControlNet for our one-step purification. OSCP is computationally friendly and time efficient compared to other diffusion-based purification methods; we achieve defense success rate of 74.19\% on ImageNet, only requiring 0.1s for each purification. Moreover, there is a fundamental incongruence between consistency distillation and adversarial perturbation. To address this ontological dissonance, we propose Gaussian Adversarial Noise Distillation (GAND), a novel consistency distillation framework that facilitates a more nuanced reconciliation of the latent space dynamics, effectively bridging the natural and adversarial manifolds. Our experiments show that the GAND does not need a Full Fine Tune (FFT); PEFT, e.g., LoRA is sufficient.
A Grey-box Attack against Latent Diffusion Model-based Image Editing by Posterior Collapse
Aug 20, 2024
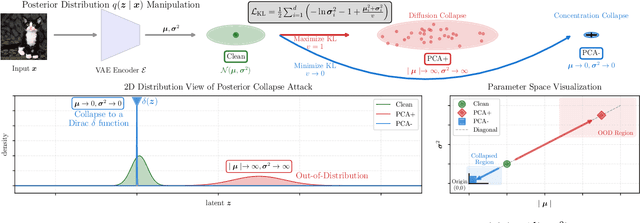


Recent advancements in generative AI, particularly Latent Diffusion Models (LDMs), have revolutionized image synthesis and manipulation. However, these generative techniques raises concerns about data misappropriation and intellectual property infringement. Adversarial attacks on machine learning models have been extensively studied, and a well-established body of research has extended these techniques as a benign metric to prevent the underlying misuse of generative AI. Current approaches to safeguarding images from manipulation by LDMs are limited by their reliance on model-specific knowledge and their inability to significantly degrade semantic quality of generated images. In response to these shortcomings, we propose the Posterior Collapse Attack (PCA) based on the observation that VAEs suffer from posterior collapse during training. Our method minimizes dependence on the white-box information of target models to get rid of the implicit reliance on model-specific knowledge. By accessing merely a small amount of LDM parameters, in specific merely the VAE encoder of LDMs, our method causes a substantial semantic collapse in generation quality, particularly in perceptual consistency, and demonstrates strong transferability across various model architectures. Experimental results show that PCA achieves superior perturbation effects on image generation of LDMs with lower runtime and VRAM. Our method outperforms existing techniques, offering a more robust and generalizable solution that is helpful in alleviating the socio-technical challenges posed by the rapidly evolving landscape of generative AI.
Self-Supervised Learning of Whole and Component-Based Semantic Representations for Person Re-Identification
Dec 01, 2023



Interactive Segmentation Models (ISMs) like the Segment Anything Model have significantly improved various computer vision tasks, yet their application to Person Re-identification (ReID) remains limited. On the other hand, existing semantic pre-training models for ReID often have limitations like predefined parsing ranges or coarse semantics. Additionally, ReID and Clothes-Changing ReID (CC-ReID) are usually treated separately due to their different domains. This paper investigates whether utilizing precise human-centric semantic representation can boost the ReID performance and improve the generalization among various ReID tasks. We propose SemReID, a self-supervised ReID model that leverages ISMs for adaptive part-based semantic extraction, contributing to the improvement of ReID performance. SemReID additionally refines its semantic representation through techniques such as image masking and KoLeo regularization. Evaluation across three types of ReID datasets -- standard ReID, CC-ReID, and unconstrained ReID -- demonstrates superior performance compared to state-of-the-art methods. In addition, recognizing the scarcity of large person datasets with fine-grained semantics, we introduce the novel LUPerson-Part dataset to assist ReID methods in acquiring the fine-grained part semantics for robust performance.
Instruct2Attack: Language-Guided Semantic Adversarial Attacks
Nov 27, 2023We propose Instruct2Attack (I2A), a language-guided semantic attack that generates semantically meaningful perturbations according to free-form language instructions. We make use of state-of-the-art latent diffusion models, where we adversarially guide the reverse diffusion process to search for an adversarial latent code conditioned on the input image and text instruction. Compared to existing noise-based and semantic attacks, I2A generates more natural and diverse adversarial examples while providing better controllability and interpretability. We further automate the attack process with GPT-4 to generate diverse image-specific text instructions. We show that I2A can successfully break state-of-the-art deep neural networks even under strong adversarial defenses, and demonstrate great transferability among a variety of network architectures.
Whole-body Detection, Recognition and Identification at Altitude and Range
Nov 09, 2023In this paper, we address the challenging task of whole-body biometric detection, recognition, and identification at distances of up to 500m and large pitch angles of up to 50 degree. We propose an end-to-end system evaluated on diverse datasets, including the challenging Biometric Recognition and Identification at Range (BRIAR) dataset. Our approach involves pre-training the detector on common image datasets and fine-tuning it on BRIAR's complex videos and images. After detection, we extract body images and employ a feature extractor for recognition. We conduct thorough evaluations under various conditions, such as different ranges and angles in indoor, outdoor, and aerial scenarios. Our method achieves an average F1 score of 98.29% at IoU = 0.7 and demonstrates strong performance in recognition accuracy and true acceptance rate at low false acceptance rates compared to existing models. On a test set of 100 subjects with 444 distractors, our model achieves a rank-20 recognition accuracy of 75.13% and a TAR@1%FAR of 54.09%.