 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAR-MAP: Are Autoregressive Large Language Models Implicit Teachers for Diffusion Large Language Models?
Feb 03, 2026Diffusion Large Language Models (DLLMs) have emerged as a powerful alternative to autoregressive models, enabling parallel token generation across multiple positions. However, preference alignment of DLLMs remains challenging due to high variance introduced by Evidence Lower Bound (ELBO)-based likelihood estimation. In this work, we propose AR-MAP, a novel transfer learning framework that leverages preference-aligned autoregressive LLMs (AR-LLMs) as implicit teachers for DLLM alignment. We reveal that DLLMs can effectively absorb alignment knowledge from AR-LLMs through simple weight scaling, exploiting the shared architectural structure between these divergent generation paradigms. Crucially, our approach circumvents the high variance and computational overhead of direct DLLM alignment and comprehensive experiments across diverse preference alignment tasks demonstrate that AR-MAP achieves competitive or superior performance compared to existing DLLM-specific alignment methods, achieving 69.08\% average score across all tasks and models. Our Code is available at https://github.com/AMAP-ML/AR-MAP.
Forget by Uncertainty: Orthogonal Entropy Unlearning for Quantized Neural Networks
Jan 31, 2026The deployment of quantized neural networks on edge devices, combined with privacy regulations like GDPR, creates an urgent need for machine unlearning in quantized models. However, existing methods face critical challenges: they induce forgetting by training models to memorize incorrect labels, conflating forgetting with misremembering, and employ scalar gradient reweighting that cannot resolve directional conflicts between gradients. We propose OEU, a novel Orthogonal Entropy Unlearning framework with two key innovations: 1) Entropy-guided unlearning maximizes prediction uncertainty on forgotten data, achieving genuine forgetting rather than confident misprediction, and 2) Gradient orthogonal projection eliminates interference by projecting forgetting gradients onto the orthogonal complement of retain gradients, providing theoretical guarantees for utility preservation under first-order approximation. Extensive experiments demonstrate that OEU outperforms existing methods in both forgetting effectiveness and retain accuracy.
Noise-Aware and Dynamically Adaptive Federated Defense Framework for SAR Image Target Recognition
Dec 31, 2025As a critical application of computational intelligence in remote sensing, deep learning-based synthetic aperture radar (SAR) image target recognition facilitates intelligent perception but typically relies on centralized training, where multi-source SAR data are uploaded to a single server, raising privacy and security concerns. Federated learning (FL) provides an emerging computational intelligence paradigm for SAR image target recognition, enabling cross-site collaboration while preserving local data privacy. However, FL confronts critical security risks, where malicious clients can exploit SAR's multiplicative speckle noise to conceal backdoor triggers, severely challenging the robustness of the computational intelligence model. To address this challenge, we propose NADAFD, a noise-aware and dynamically adaptive federated defense framework that integrates frequency-domain, spatial-domain, and client-behavior analyses to counter SAR-specific backdoor threats. Specifically, we introduce a frequency-domain collaborative inversion mechanism to expose cross-client spectral inconsistencies indicative of hidden backdoor triggers. We further design a noise-aware adversarial training strategy that embeds $Γ$-distributed speckle characteristics into mask-guided adversarial sample generation to enhance robustness against both backdoor attacks and SAR speckle noise. In addition, we present a dynamic health assessment module that tracks client update behaviors across training rounds and adaptively adjusts aggregation weights to mitigate evolving malicious contributions. Experiments on MSTAR and OpenSARShip datasets demonstrate that NADAFD achieves higher accuracy on clean test samples and a lower backdoor attack success rate on triggered inputs than existing federated backdoor defenses for SAR target recognition.
A Systematic Study of Model Extraction Attacks on Graph Foundation Models
Nov 14, 2025Graph machine learning has advanced rapidly in tasks such as link prediction, anomaly detection, and node classification. As models scale up, pretrained graph models have become valuable intellectual assets because they encode extensive computation and domain expertise. Building on these advances, Graph Foundation Models (GFMs) mark a major step forward by jointly pretraining graph and text encoders on massive and diverse data. This unifies structural and semantic understanding, enables zero-shot inference, and supports applications such as fraud detection and biomedical analysis. However, the high pretraining cost and broad cross-domain knowledge in GFMs also make them attractive targets for model extraction attacks (MEAs). Prior work has focused only on small graph neural networks trained on a single graph, leaving the security implications for large-scale and multimodal GFMs largely unexplored. This paper presents the first systematic study of MEAs against GFMs. We formalize a black-box threat model and define six practical attack scenarios covering domain-level and graph-specific extraction goals, architectural mismatch, limited query budgets, partial node access, and training data discrepancies. To instantiate these attacks, we introduce a lightweight extraction method that trains an attacker encoder using supervised regression of graph embeddings. Even without contrastive pretraining data, this method learns an encoder that stays aligned with the victim text encoder and preserves its zero-shot inference ability on unseen graphs. Experiments on seven datasets show that the attacker can approximate the victim model using only a tiny fraction of its original training cost, with almost no loss in accuracy. These findings reveal that GFMs greatly expand the MEA surface and highlight the need for deployment-aware security defenses in large-scale graph learning systems.
Can LLMs Refuse Questions They Do Not Know? Measuring Knowledge-Aware Refusal in Factual Tasks
Oct 02, 2025Large Language Models (LLMs) should refuse to answer questions beyond their knowledge. This capability, which we term knowledge-aware refusal, is crucial for factual reliability. However, existing metrics fail to faithfully measure this ability. On the one hand, simple refusal-based metrics are biased by refusal rates and yield inconsistent scores when models exhibit different refusal tendencies. On the other hand, existing calibration metrics are proxy-based, capturing the performance of auxiliary calibration processes rather than the model's actual refusal behavior. In this work, we propose the Refusal Index (RI), a principled metric that measures how accurately LLMs refuse questions they do not know. We define RI as Spearman's rank correlation between refusal probability and error probability. To make RI practically measurable, we design a lightweight two-pass evaluation method that efficiently estimates RI from observed refusal rates across two standard evaluation runs. Extensive experiments across 16 models and 5 datasets demonstrate that RI accurately quantifies a model's intrinsic knowledge-aware refusal capability in factual tasks. Notably, RI remains stable across different refusal rates and provides consistent model rankings independent of a model's overall accuracy and refusal rates. More importantly, RI provides insight into an important but previously overlooked aspect of LLM factuality: while LLMs achieve high accuracy on factual tasks, their refusal behavior can be unreliable and fragile. This finding highlights the need to complement traditional accuracy metrics with the Refusal Index for comprehensive factuality evaluation.
IMPQ: Interaction-Aware Layerwise Mixed Precision Quantization for LLMs
Sep 18, 2025Large Language Models (LLMs) promise impressive capabilities, yet their multi-billion-parameter scale makes on-device or low-resource deployment prohibitive. Mixed-precision quantization offers a compelling solution, but existing methods struggle when the average precision drops below four bits, as they rely on isolated, layer-specific metrics that overlook critical inter-layer interactions affecting overall performance. In this paper, we propose two innovations to address these limitations. First, we frame the mixed-precision quantization problem as a cooperative game among layers and introduce Shapley-based Progressive Quantization Estimation (SPQE) to efficiently obtain accurate Shapley estimates of layer sensitivities and inter-layer interactions. Second, building upon SPQE, we propose Interaction-aware Mixed-Precision Quantization (IMPQ) which translates these Shapley estimates into a binary quadratic optimization formulation, assigning either 2 or 4-bit precision to layers under strict memory constraints. Comprehensive experiments conducted on Llama-3, Gemma-2, and Qwen-3 models across three independent PTQ backends (Quanto, HQQ, GPTQ) demonstrate IMPQ's scalability and consistently superior performance compared to methods relying solely on isolated metrics. Across average precisions spanning 4 bit down to 2 bit, IMPQ cuts Perplexity by 20 to 80 percent relative to the best baseline, with the margin growing as the bit-width tightens.
SepPrune: Structured Pruning for Efficient Deep Speech Separation
May 17, 2025Although deep learning has substantially advanced speech separation in recent years, most existing studies continue to prioritize separation quality while overlooking computational efficiency, an essential factor for low-latency speech processing in real-time applications. In this paper, we propose SepPrune, the first structured pruning framework specifically designed to compress deep speech separation models and reduce their computational cost. SepPrune begins by analyzing the computational structure of a given model to identify layers with the highest computational burden. It then introduces a differentiable masking strategy to enable gradient-driven channel selection. Based on the learned masks, SepPrune prunes redundant channels and fine-tunes the remaining parameters to recover performance. Extensive experiments demonstrate that this learnable pruning paradigm yields substantial advantages for channel pruning in speech separation models, outperforming existing methods. Notably, a model pruned with SepPrune can recover 85% of the performance of a pre-trained model (trained over hundreds of epochs) with only one epoch of fine-tuning, and achieves convergence 36$\times$ faster than training from scratch. Code is available at https://github.com/itsnotacie/SepPrune.
Mitigating Group-Level Fairness Disparities in Federated Visual Language Models
May 03, 2025Visual language models (VLMs) have shown remarkable capabilities in multimodal tasks but face challenges in maintaining fairness across demographic groups, particularly when deployed in federated learning (FL) environments. This paper addresses the critical issue of group fairness in federated VLMs by introducing FVL-FP, a novel framework that combines FL with fair prompt tuning techniques. We focus on mitigating demographic biases while preserving model performance through three innovative components: (1) Cross-Layer Demographic Fair Prompting (CDFP), which adjusts potentially biased embeddings through counterfactual regularization; (2) Demographic Subspace Orthogonal Projection (DSOP), which removes demographic bias in image representations by mapping fair prompt text to group subspaces; and (3) Fair-aware Prompt Fusion (FPF), which dynamically balances client contributions based on both performance and fairness metrics. Extensive evaluations across four benchmark datasets demonstrate that our approach reduces demographic disparity by an average of 45\% compared to standard FL approaches, while maintaining task performance within 6\% of state-of-the-art results. FVL-FP effectively addresses the challenges of non-IID data distributions in federated settings and introduces minimal computational overhead while providing significant fairness benefits. Our work presents a parameter-efficient solution to the critical challenge of ensuring equitable performance across demographic groups in privacy-preserving multimodal systems.
Mind the Trojan Horse: Image Prompt Adapter Enabling Scalable and Deceptive Jailbreaking
Apr 08, 2025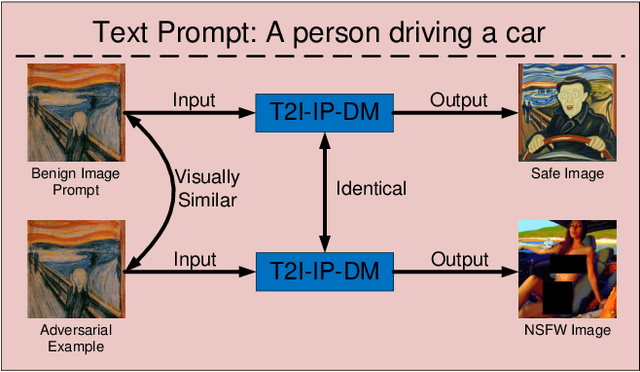
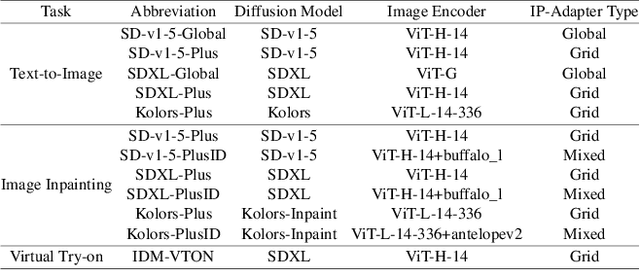
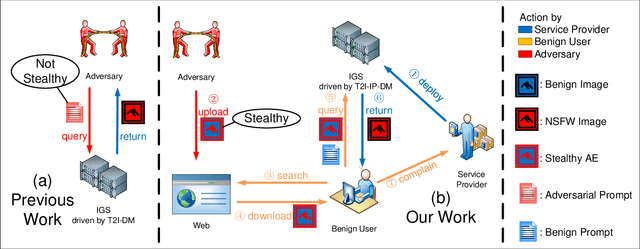
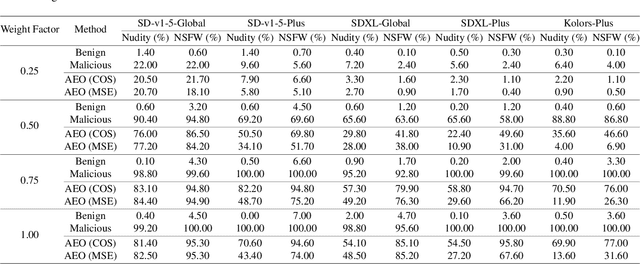
Recently, the Image Prompt Adapter (IP-Adapter) has been increasingly integrated into text-to-image diffusion models (T2I-DMs) to improve controllability. However, in this paper, we reveal that T2I-DMs equipped with the IP-Adapter (T2I-IP-DMs) enable a new jailbreak attack named the hijacking attack. We demonstrate that, by uploading imperceptible image-space adversarial examples (AEs), the adversary can hijack massive benign users to jailbreak an Image Generation Service (IGS) driven by T2I-IP-DMs and mislead the public to discredit the service provider. Worse still, the IP-Adapter's dependency on open-source image encoders reduces the knowledge required to craft AEs. Extensive experiments verify the technical feasibility of the hijacking attack. In light of the revealed threat, we investigate several existing defenses and explore combining the IP-Adapter with adversarially trained models to overcome existing defenses' limitations. Our code is available at https://github.com/fhdnskfbeuv/attackIPA.
ICFNet: Integrated Cross-modal Fusion Network for Survival Prediction
Jan 06, 2025



Survival prediction is a crucial task in the medical field and is essential for optimizing treatment options and resource allocation. However, current methods often rely on limited data modalities, resulting in suboptimal performance. In this paper, we propose an Integrated Cross-modal Fusion Network (ICFNet) that integrates histopathology whole slide images, genomic expression profiles, patient demographics, and treatment protocols. Specifically, three types of encoders, a residual orthogonal decomposition module and a unification fusion module are employed to merge multi-modal features to enhance prediction accuracy. Additionally, a balanced negative log-likelihood loss function is designed to ensure fair training across different patients. Extensive experiments demonstrate that our ICFNet outperforms state-of-the-art algorithms on five public TCGA datasets, including BLCA, BRCA, GBMLGG, LUAD, and UCEC, and shows its potential to support clinical decision-making and advance precision medicine. The codes are available at: https://github.com/binging512/ICFNet.