 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Multi-Modal Deep Learning Framework for Pan-Cancer Prognosis
Jan 13, 2025Prognostic task is of great importance as it closely related to the survival analysis of patients, the optimization of treatment plans and the allocation of resources. The existing prognostic models have shown promising results on specific datasets, but there are limitations in two aspects. On the one hand, they merely explore certain types of modal data, such as patient histopathology WSI and gene expression analysis. On the other hand, they adopt the per-cancer-per-model paradigm, which means the trained models can only predict the prognostic effect of a single type of cancer, resulting in weak generalization ability. In this paper, a deep-learning based model, named UMPSNet, is proposed. Specifically, to comprehensively understand the condition of patients, in addition to constructing encoders for histopathology images and genomic expression profiles respectively, UMPSNet further integrates four types of important meta data (demographic information, cancer type information, treatment protocols, and diagnosis results) into text templates, and then introduces a text encoder to extract textual features. In addition, the optimal transport OT-based attention mechanism is utilized to align and fuse features of different modalities. Furthermore, a guided soft mixture of experts (GMoE) mechanism is introduced to effectively address the issue of distribution differences among multiple cancer datasets. By incorporating the multi-modality of patient data and joint training, UMPSNet outperforms all SOTA approaches, and moreover, it demonstrates the effectiveness and generalization ability of the proposed learning paradigm of a single model for multiple cancer types. The code of UMPSNet is available at https://github.com/binging512/UMPSNet.
ICFNet: Integrated Cross-modal Fusion Network for Survival Prediction
Jan 06, 2025



Survival prediction is a crucial task in the medical field and is essential for optimizing treatment options and resource allocation. However, current methods often rely on limited data modalities, resulting in suboptimal performance. In this paper, we propose an Integrated Cross-modal Fusion Network (ICFNet) that integrates histopathology whole slide images, genomic expression profiles, patient demographics, and treatment protocols. Specifically, three types of encoders, a residual orthogonal decomposition module and a unification fusion module are employed to merge multi-modal features to enhance prediction accuracy. Additionally, a balanced negative log-likelihood loss function is designed to ensure fair training across different patients. Extensive experiments demonstrate that our ICFNet outperforms state-of-the-art algorithms on five public TCGA datasets, including BLCA, BRCA, GBMLGG, LUAD, and UCEC, and shows its potential to support clinical decision-making and advance precision medicine. The codes are available at: https://github.com/binging512/ICFNet.
OMG: Observe Multiple Granularities for Natural Language-Based Vehicle Retrieval
Apr 18, 2022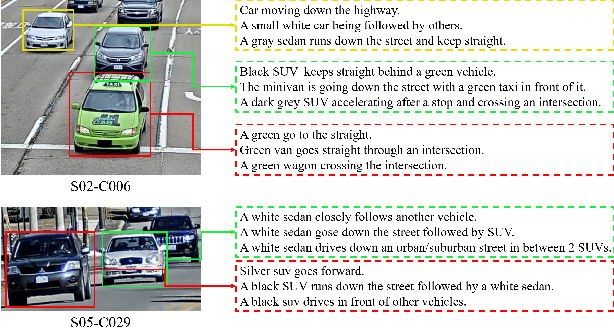
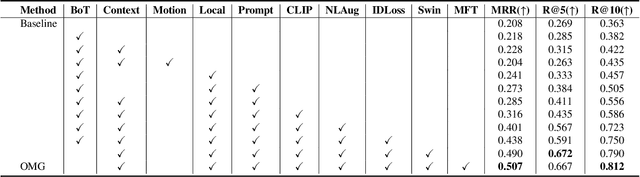
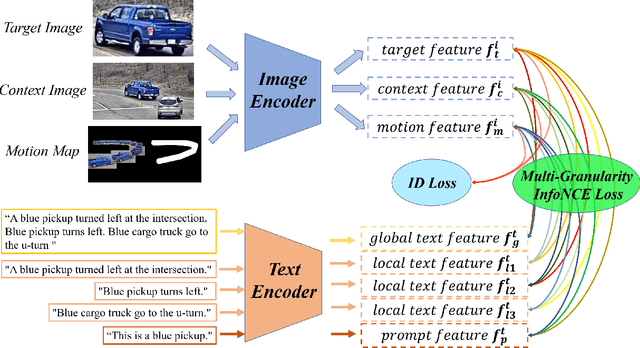
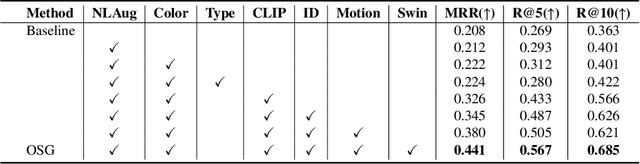
Retrieving tracked-vehicles by natural language descriptions plays a critical role in smart city construction. It aims to find the best match for the given texts from a set of tracked vehicles in surveillance videos. Existing works generally solve it by a dual-stream framework, which consists of a text encoder, a visual encoder and a cross-modal loss function. Although some progress has been made, they failed to fully exploit the information at various levels of granularity. To tackle this issue, we propose a novel framework for the natural language-based vehicle retrieval task, OMG, which Observes Multiple Granularities with respect to visual representation, textual representation and objective functions. For the visual representation, target features, context features and motion features are encoded separately. For the textual representation, one global embedding, three local embeddings and a color-type prompt embedding are extracted to represent various granularities of semantic features. Finally, the overall framework is optimized by a cross-modal multi-granularity contrastive loss function. Experiments demonstrate the effectiveness of our method. Our OMG significantly outperforms all previous methods and ranks the 9th on the 6th AI City Challenge Track2. The codes are available at https://github.com/dyhBUPT/OMG.
PAMI-AD: An Activity Detector Exploiting Part-attention and Motion Information in Surveillance Videos
Mar 08, 2022
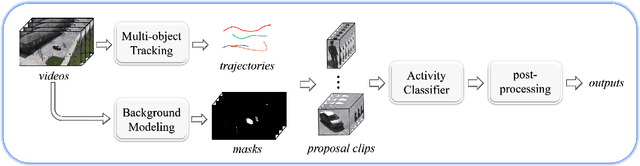
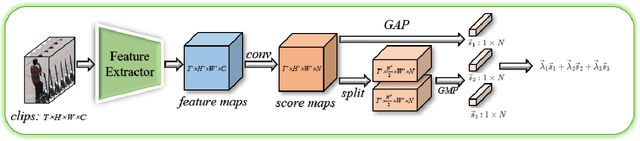

Activity detection in surveillance videos is a challenging task caused by small objects, complex activity categories, its untrimmed nature, etc. In this work, we propose an effective activity detection system for person-only and vehicle-only activities in untrimmed surveillance videos, named PAMI-AD. It consists of four modules, i.e., multi-object tracking, background modeling, activity classifier and post-processing. In particular, we propose a novel part-attention mechanism for person-only activities and a simple but strong motion information encoding method for vehicle-only activities. Our proposed system achieves the best results on the VIRAT dataset. Furthermore, our team won the 1st place in the TRECVID 2021 ActEV challenge.
GIAOTracker: A comprehensive framework for MCMOT with global information and optimizing strategies in VisDrone 2021
Feb 24, 2022
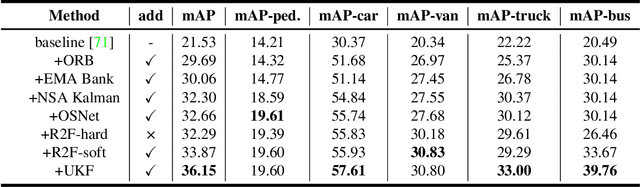
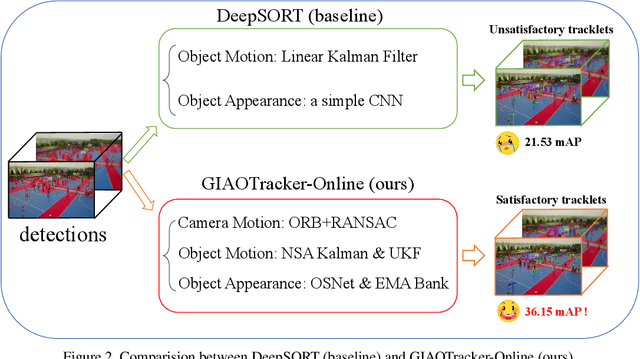
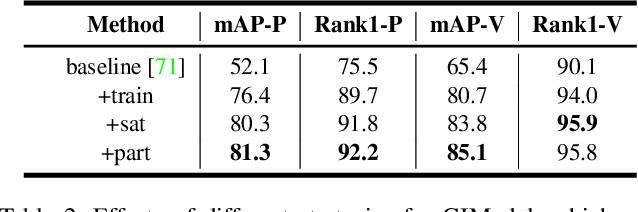
In recent years, algorithms for multiple object tracking tasks have benefited from great progresses in deep models and video quality. However, in challenging scenarios like drone videos, they still suffer from problems, such as small objects, camera movements and view changes. In this paper, we propose a new multiple object tracker, which employs Global Information And some Optimizing strategies, named GIAOTracker. It consists of three stages, i.e., online tracking, global link and post-processing. Given detections in every frame, the first stage generates reliable tracklets using information of camera motion, object motion and object appearance. Then they are associated into trajectories by exploiting global clues and refined through four post-processing methods. With the effectiveness of the three stages, GIAOTracker achieves state-of-the-art performance on the VisDrone MOT dataset and wins the 3rd place in the VisDrone2021 MOT Challenge.
* ICCV 2021 Workshop
VisDrone-CC2020: The Vision Meets Drone Crowd Counting Challenge Results
Jul 19, 2021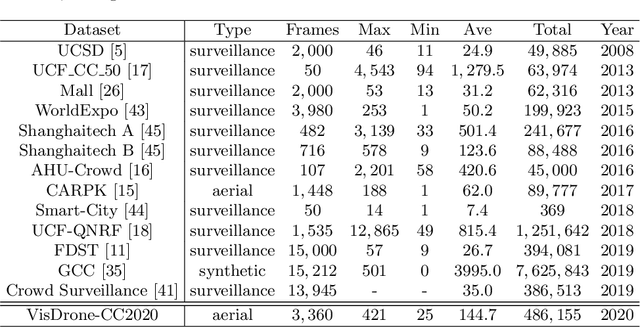

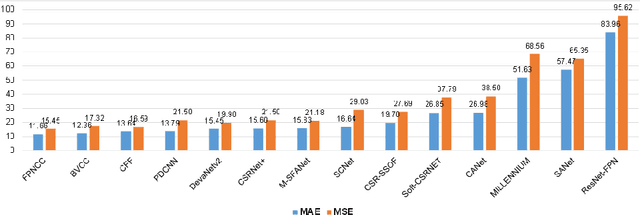
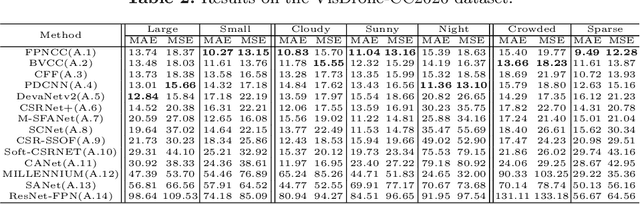
Crowd counting on the drone platform is an interesting topic in computer vision, which brings new challenges such as small object inference, background clutter and wide viewpoint. However, there are few algorithms focusing on crowd counting on the drone-captured data due to the lack of comprehensive datasets. To this end, we collect a large-scale dataset and organize the Vision Meets Drone Crowd Counting Challenge (VisDrone-CC2020) in conjunction with the 16th European Conference on Computer Vision (ECCV 2020) to promote the developments in the related fields. The collected dataset is formed by $3,360$ images, including $2,460$ images for training, and $900$ images for testing. Specifically, we manually annotate persons with points in each video frame. There are $14$ algorithms from $15$ institutes submitted to the VisDrone-CC2020 Challenge. We provide a detailed analysis of the evaluation results and conclude the challenge. More information can be found at the website: \url{http://www.aiskyeye.com/}.
* The method description of A7 Mutil-Scale Aware based SFANet (M-SFANet) is updated and missing references are added