 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCPAny: Couple With Any Encoder to Refer Multi-Object Tracking
Mar 10, 2025Referring Multi-Object Tracking (RMOT) aims to localize target trajectories specified by natural language expressions in videos. Existing RMOT methods mainly follow two paradigms, namely, one-stage strategies and two-stage ones. The former jointly trains tracking with referring but suffers from substantial computational overhead. Although the latter improves computational efficiency, its CLIP-inspired dual-tower architecture restricts compatibility with other visual/text backbones and is not future-proof. To overcome these limitations, we propose CPAny, a novel encoder-decoder framework for two-stage RMOT, which introduces two core components: (1) a Contextual Visual Semantic Abstractor (CVSA) performs context-aware aggregation on visual backbone features and projects them into a unified semantic space; (2) a Parallel Semantic Summarizer (PSS) decodes the visual and linguistic features at the semantic level in parallel and generates referring scores. By replacing the inherent feature alignment of encoders with a self-constructed unified semantic space, CPAny achieves flexible compatibility with arbitrary emerging visual / text encoders. Meanwhile, CPAny aggregates contextual information by encoding only once and processes multiple expressions in parallel, significantly reducing computational redundancy. Extensive experiments on the Refer-KITTI and Refer-KITTI-V2 datasets show that CPAny outperforms SOTA methods across diverse encoder combinations, with a particular 7.77\% HOTA improvement on Refer-KITTI-V2. Code will be available soon.
Hierarchical IoU Tracking based on Interval
Jun 19, 2024



Multi-Object Tracking (MOT) aims to detect and associate all targets of given classes across frames. Current dominant solutions, e.g. ByteTrack and StrongSORT++, follow the hybrid pipeline, which first accomplish most of the associations in an online manner, and then refine the results using offline tricks such as interpolation and global link. While this paradigm offers flexibility in application, the disjoint design between the two stages results in suboptimal performance. In this paper, we propose the Hierarchical IoU Tracking framework, dubbed HIT, which achieves unified hierarchical tracking by utilizing tracklet intervals as priors. To ensure the conciseness, only IoU is utilized for association, while discarding the heavy appearance models, tricky auxiliary cues, and learning-based association modules. We further identify three inconsistency issues regarding target size, camera movement and hierarchical cues, and design corresponding solutions to guarantee the reliability of associations. Though its simplicity, our method achieves promising performance on four datasets, i.e., MOT17, KITTI, DanceTrack and VisDrone, providing a strong baseline for future tracking method design. Moreover, we experiment on seven trackers and prove that HIT can be seamlessly integrated with other solutions, whether they are motion-based, appearance-based or learning-based. Our codes will be released at https://github.com/dyhBUPT/HIT.
YYDS: Visible-Infrared Person Re-Identification with Coarse Descriptions
Mar 07, 2024
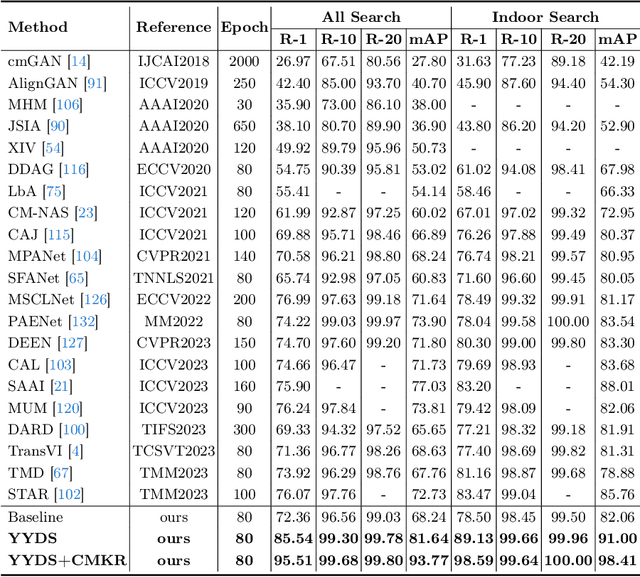


Visible-infrared person re-identification (VI-ReID) is challenging due to considerable cross-modality discrepancies. Existing works mainly focus on learning modality-invariant features while suppressing modality-specific ones. However, retrieving visible images only depends on infrared samples is an extreme problem because of the absence of color information. To this end, we present the Refer-VI-ReID settings, which aims to match target visible images from both infrared images and coarse language descriptions (e.g., "a man with red top and black pants") to complement the missing color information. To address this task, we design a Y-Y-shape decomposition structure, dubbed YYDS, to decompose and aggregate texture and color features of targets. Specifically, the text-IoU regularization strategy is firstly presented to facilitate the decomposition training, and a joint relation module is then proposed to infer the aggregation. Furthermore, the cross-modal version of k-reciprocal re-ranking algorithm is investigated, named CMKR, in which three neighbor search strategies and one local query expansion method are explored to alleviate the modality bias problem of the near neighbors. We conduct experiments on SYSU-MM01, RegDB and LLCM datasets with our manually annotated descriptions. Both YYDS and CMKR achieve remarkable improvements over SOTA methods on all three datasets. Codes are available at https://github.com/dyhBUPT/YYDS.
iKUN: Speak to Trackers without Retraining
Dec 25, 2023Referring multi-object tracking (RMOT) aims to track multiple objects based on input textual descriptions. Previous works realize it by simply integrating an extra textual module into the multi-object tracker. However, they typically need to retrain the entire framework and have difficulties in optimization. In this work, we propose an insertable Knowledge Unification Network, termed iKUN, to enable communication with off-the-shelf trackers in a plug-and-play manner. Concretely, a knowledge unification module (KUM) is designed to adaptively extract visual features based on textual guidance. Meanwhile, to improve the localization accuracy, we present a neural version of Kalman filter (NKF) to dynamically adjust process noise and observation noise based on the current motion status. Moreover, to address the problem of open-set long-tail distribution of textual descriptions, a test-time similarity calibration method is proposed to refine the confidence score with pseudo frequency. Extensive experiments on Refer-KITTI dataset verify the effectiveness of our framework. Finally, to speed up the development of RMOT, we also contribute a more challenging dataset, Refer-Dance, by extending public DanceTrack dataset with motion and dressing descriptions. The code and dataset will be released in https://github.com/dyhBUPT/iKUN.
Video-based Visible-Infrared Person Re-Identification with Auxiliary Samples
Nov 27, 2023Visible-infrared person re-identification (VI-ReID) aims to match persons captured by visible and infrared cameras, allowing person retrieval and tracking in 24-hour surveillance systems. Previous methods focus on learning from cross-modality person images in different cameras. However, temporal information and single-camera samples tend to be neglected. To crack this nut, in this paper, we first contribute a large-scale VI-ReID dataset named BUPTCampus. Different from most existing VI-ReID datasets, it 1) collects tracklets instead of images to introduce rich temporal information, 2) contains pixel-aligned cross-modality sample pairs for better modality-invariant learning, 3) provides one auxiliary set to help enhance the optimization, in which each identity only appears in a single camera. Based on our constructed dataset, we present a two-stream framework as baseline and apply Generative Adversarial Network (GAN) to narrow the gap between the two modalities. To exploit the advantages introduced by the auxiliary set, we propose a curriculum learning based strategy to jointly learn from both primary and auxiliary sets. Moreover, we design a novel temporal k-reciprocal re-ranking method to refine the ranking list with fine-grained temporal correlation cues. Experimental results demonstrate the effectiveness of the proposed methods. We also reproduce 9 state-of-the-art image-based and video-based VI-ReID methods on BUPTCampus and our methods show substantial superiority to them. The codes and dataset are available at: https://github.com/dyhBUPT/BUPTCampus.
Dynamic Clustering and Cluster Contrastive Learning for Unsupervised Person Re-identification
Mar 13, 2023Unsupervised Re-ID methods aim at learning robust and discriminative features from unlabeled data. However, existing methods often ignore the relationship between module parameters of Re-ID framework and feature distributions, which may lead to feature misalignment and hinder the model performance. To address this problem, we propose a dynamic clustering and cluster contrastive learning (DCCC) method. Specifically, we first design a dynamic clustering parameters scheduler (DCPS) which adjust the hyper-parameter of clustering to fit the variation of intra- and inter-class distances. Then, a dynamic cluster contrastive learning (DyCL) method is designed to match the cluster representation vectors' weights with the local feature association. Finally, a label smoothing soft contrastive loss ($L_{ss}$) is built to keep the balance between cluster contrastive learning and self-supervised learning with low computational consumption and high computational efficiency. Experiments on several widely used public datasets validate the effectiveness of our proposed DCCC which outperforms previous state-of-the-art methods by achieving the best performance.
EnsembleMOT: A Step towards Ensemble Learning of Multiple Object Tracking
Oct 11, 2022
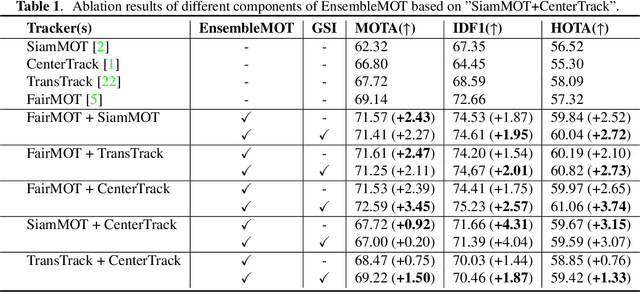

Multiple Object Tracking (MOT) has rapidly progressed in recent years. Existing works tend to design a single tracking algorithm to perform both detection and association. Though ensemble learning has been exploited in many tasks, i.e, classification and object detection, it hasn't been studied in the MOT task, which is mainly caused by its complexity and evaluation metrics. In this paper, we propose a simple but effective ensemble method for MOT, called EnsembleMOT, which merges multiple tracking results from various trackers with spatio-temporal constraints. Meanwhile, several post-processing procedures are applied to filter out abnormal results. Our method is model-independent and doesn't need the learning procedure. What's more, it can easily work in conjunction with other algorithms, e.g., tracklets interpolation. Experiments on the MOT17 dataset demonstrate the effectiveness of the proposed method. Codes are available at https://github.com/dyhBUPT/EnsembleMOT.
OMG: Observe Multiple Granularities for Natural Language-Based Vehicle Retrieval
Apr 18, 2022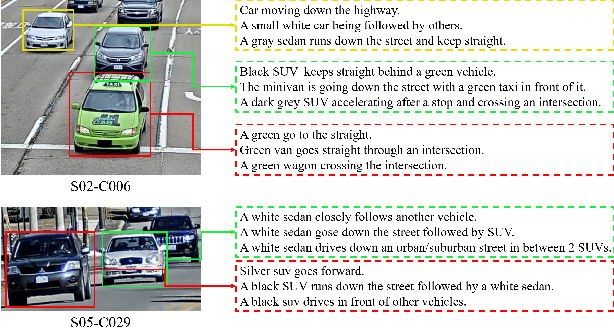
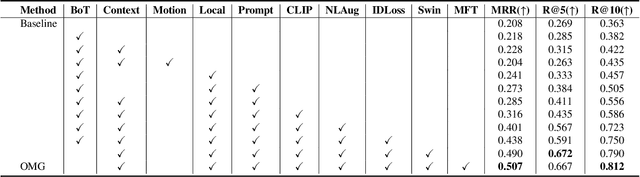
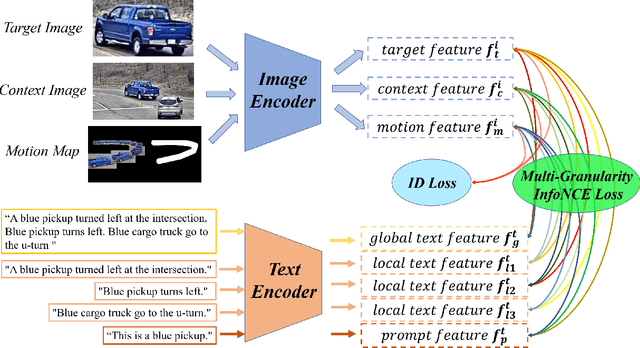
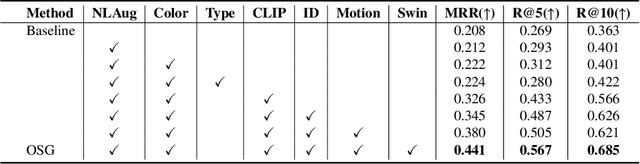
Retrieving tracked-vehicles by natural language descriptions plays a critical role in smart city construction. It aims to find the best match for the given texts from a set of tracked vehicles in surveillance videos. Existing works generally solve it by a dual-stream framework, which consists of a text encoder, a visual encoder and a cross-modal loss function. Although some progress has been made, they failed to fully exploit the information at various levels of granularity. To tackle this issue, we propose a novel framework for the natural language-based vehicle retrieval task, OMG, which Observes Multiple Granularities with respect to visual representation, textual representation and objective functions. For the visual representation, target features, context features and motion features are encoded separately. For the textual representation, one global embedding, three local embeddings and a color-type prompt embedding are extracted to represent various granularities of semantic features. Finally, the overall framework is optimized by a cross-modal multi-granularity contrastive loss function. Experiments demonstrate the effectiveness of our method. Our OMG significantly outperforms all previous methods and ranks the 9th on the 6th AI City Challenge Track2. The codes are available at https://github.com/dyhBUPT/OMG.
PAMI-AD: An Activity Detector Exploiting Part-attention and Motion Information in Surveillance Videos
Mar 08, 2022
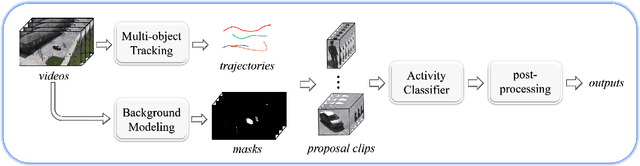
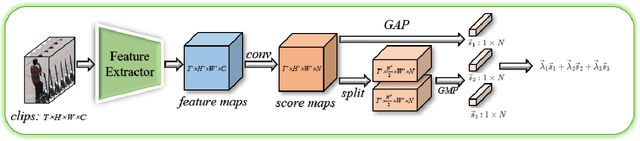

Activity detection in surveillance videos is a challenging task caused by small objects, complex activity categories, its untrimmed nature, etc. In this work, we propose an effective activity detection system for person-only and vehicle-only activities in untrimmed surveillance videos, named PAMI-AD. It consists of four modules, i.e., multi-object tracking, background modeling, activity classifier and post-processing. In particular, we propose a novel part-attention mechanism for person-only activities and a simple but strong motion information encoding method for vehicle-only activities. Our proposed system achieves the best results on the VIRAT dataset. Furthermore, our team won the 1st place in the TRECVID 2021 ActEV challenge.
StrongSORT: Make DeepSORT Great Again
Feb 28, 2022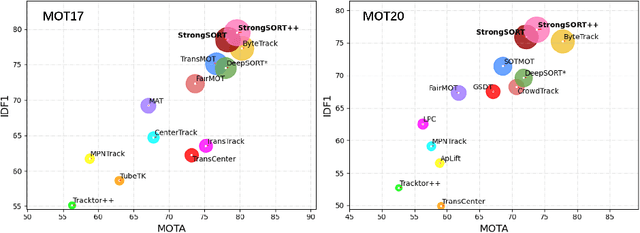

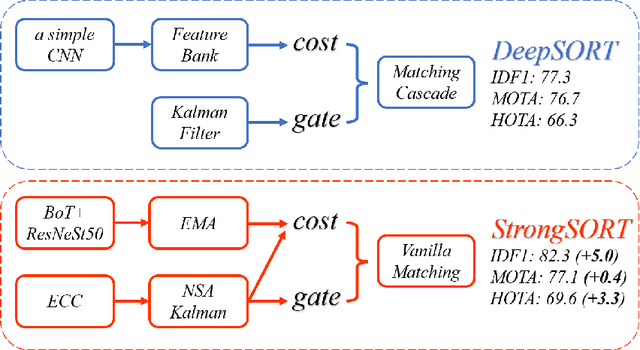
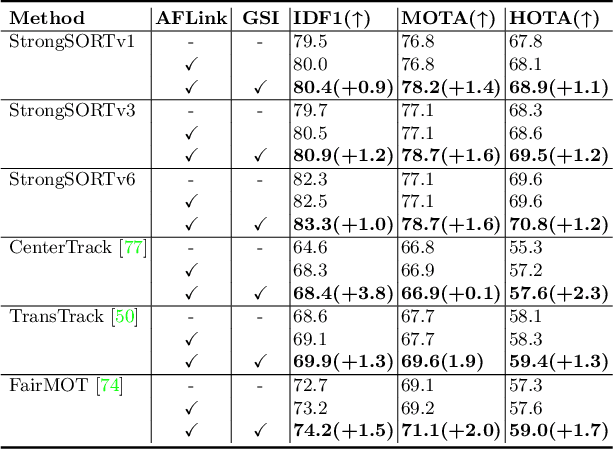
Existing Multi-Object Tracking (MOT) methods can be roughly classified as tracking-by-detection and joint-detection-association paradigms. Although the latter has elicited more attention and demonstrates comparable performance relative to the former, we claim that the tracking-by-detection paradigm is still the optimal solution in terms of tracking accuracy. In this paper, we revisit the classic tracker DeepSORT and upgrade it from various aspects, i.e., detection, embedding and association. The resulting tracker, called StrongSORT, sets new HOTA and IDF1 records on MOT17 and MOT20. We also present two lightweight and plug-and-play algorithms to further refine the tracking results. Firstly, an appearance-free link model (AFLink) is proposed to associate short tracklets into complete trajectories. To the best of our knowledge, this is the first global link model without appearance information. Secondly, we propose Gaussian-smoothed interpolation (GSI) to compensate for missing detections. Instead of ignoring motion information like linear interpolation, GSI is based on the Gaussian process regression algorithm and can achieve more accurate localizations. Moreover, AFLink and GSI can be plugged into various trackers with a negligible extra computational cost (591.9 and 140.9 Hz, respectively, on MOT17). By integrating StrongSORT with the two algorithms, the final tracker StrongSORT++ ranks first on MOT17 and MOT20 in terms of HOTA and IDF1 metrics and surpasses the second-place one by 1.3 - 2.2. Code will be released soon.