 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMiLA: Multi-view Intensive-fidelity Long-term Video Generation World Model for Autonomous Driving
Mar 20, 2025In recent years, data-driven techniques have greatly advanced autonomous driving systems, but the need for rare and diverse training data remains a challenge, requiring significant investment in equipment and labor. World models, which predict and generate future environmental states, offer a promising solution by synthesizing annotated video data for training. However, existing methods struggle to generate long, consistent videos without accumulating errors, especially in dynamic scenes. To address this, we propose MiLA, a novel framework for generating high-fidelity, long-duration videos up to one minute. MiLA utilizes a Coarse-to-Re(fine) approach to both stabilize video generation and correct distortion of dynamic objects. Additionally, we introduce a Temporal Progressive Denoising Scheduler and Joint Denoising and Correcting Flow modules to improve the quality of generated videos. Extensive experiments on the nuScenes dataset show that MiLA achieves state-of-the-art performance in video generation quality. For more information, visit the project website: https://github.com/xiaomi-mlab/mila.github.io.
CPAny: Couple With Any Encoder to Refer Multi-Object Tracking
Mar 10, 2025Referring Multi-Object Tracking (RMOT) aims to localize target trajectories specified by natural language expressions in videos. Existing RMOT methods mainly follow two paradigms, namely, one-stage strategies and two-stage ones. The former jointly trains tracking with referring but suffers from substantial computational overhead. Although the latter improves computational efficiency, its CLIP-inspired dual-tower architecture restricts compatibility with other visual/text backbones and is not future-proof. To overcome these limitations, we propose CPAny, a novel encoder-decoder framework for two-stage RMOT, which introduces two core components: (1) a Contextual Visual Semantic Abstractor (CVSA) performs context-aware aggregation on visual backbone features and projects them into a unified semantic space; (2) a Parallel Semantic Summarizer (PSS) decodes the visual and linguistic features at the semantic level in parallel and generates referring scores. By replacing the inherent feature alignment of encoders with a self-constructed unified semantic space, CPAny achieves flexible compatibility with arbitrary emerging visual / text encoders. Meanwhile, CPAny aggregates contextual information by encoding only once and processes multiple expressions in parallel, significantly reducing computational redundancy. Extensive experiments on the Refer-KITTI and Refer-KITTI-V2 datasets show that CPAny outperforms SOTA methods across diverse encoder combinations, with a particular 7.77\% HOTA improvement on Refer-KITTI-V2. Code will be available soon.
Learning A Zero-shot Occupancy Network from Vision Foundation Models via Self-supervised Adaptation
Mar 10, 2025Estimating the 3D world from 2D monocular images is a fundamental yet challenging task due to the labour-intensive nature of 3D annotations. To simplify label acquisition, this work proposes a novel approach that bridges 2D vision foundation models (VFMs) with 3D tasks by decoupling 3D supervision into an ensemble of image-level primitives, e.g., semantic and geometric components. As a key motivator, we leverage the zero-shot capabilities of vision-language models for image semantics. However, due to the notorious ill-posed problem - multiple distinct 3D scenes can produce identical 2D projections, directly inferring metric depth from a monocular image in a zero-shot manner is unsuitable. In contrast, 2D VFMs provide promising sources of relative depth, which theoretically aligns with metric depth when properly scaled and offset. Thus, we adapt the relative depth derived from VFMs into metric depth by optimising the scale and offset using temporal consistency, also known as novel view synthesis, without access to ground-truth metric depth. Consequently, we project the semantics into 3D space using the reconstructed metric depth, thereby providing 3D supervision. Extensive experiments on nuScenes and SemanticKITTI demonstrate the effectiveness of our framework. For instance, the proposed method surpasses the current state-of-the-art by 3.34% mIoU on nuScenes for voxel occupancy prediction.
Self-Supervised Multi-Frame Neural Scene Flow
Mar 24, 2024



Neural Scene Flow Prior (NSFP) and Fast Neural Scene Flow (FNSF) have shown remarkable adaptability in the context of large out-of-distribution autonomous driving. Despite their success, the underlying reasons for their astonishing generalization capabilities remain unclear. Our research addresses this gap by examining the generalization capabilities of NSFP through the lens of uniform stability, revealing that its performance is inversely proportional to the number of input point clouds. This finding sheds light on NSFP's effectiveness in handling large-scale point cloud scene flow estimation tasks. Motivated by such theoretical insights, we further explore the improvement of scene flow estimation by leveraging historical point clouds across multiple frames, which inherently increases the number of point clouds. Consequently, we propose a simple and effective method for multi-frame point cloud scene flow estimation, along with a theoretical evaluation of its generalization abilities. Our analysis confirms that the proposed method maintains a limited generalization error, suggesting that adding multiple frames to the scene flow optimization process does not detract from its generalizability. Extensive experimental results on large-scale autonomous driving Waymo Open and Argoverse lidar datasets demonstrate that the proposed method achieves state-of-the-art performance.
SurroundSDF: Implicit 3D Scene Understanding Based on Signed Distance Field
Mar 21, 2024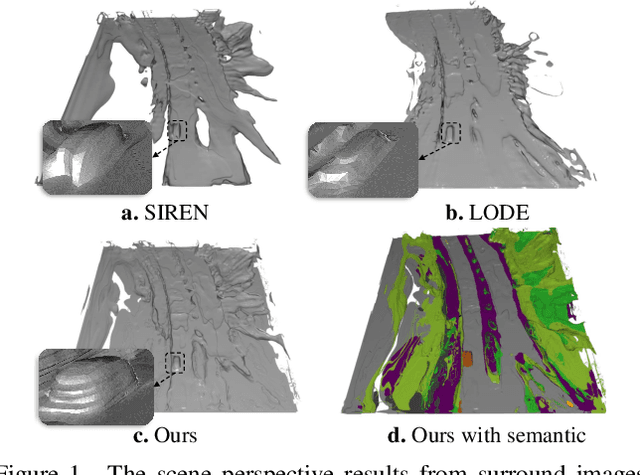



Vision-centric 3D environment understanding is both vital and challenging for autonomous driving systems. Recently, object-free methods have attracted considerable attention. Such methods perceive the world by predicting the semantics of discrete voxel grids but fail to construct continuous and accurate obstacle surfaces. To this end, in this paper, we propose SurroundSDF to implicitly predict the signed distance field (SDF) and semantic field for the continuous perception from surround images. Specifically, we introduce a query-based approach and utilize SDF constrained by the Eikonal formulation to accurately describe the surfaces of obstacles. Furthermore, considering the absence of precise SDF ground truth, we propose a novel weakly supervised paradigm for SDF, referred to as the Sandwich Eikonal formulation, which emphasizes applying correct and dense constraints on both sides of the surface, thereby enhancing the perceptual accuracy of the surface. Experiments suggest that our method achieves SOTA for both occupancy prediction and 3D scene reconstruction tasks on the nuScenes dataset.
Globally Optimal Event-Based Divergence Estimation for Ventral Landing
Sep 27, 2022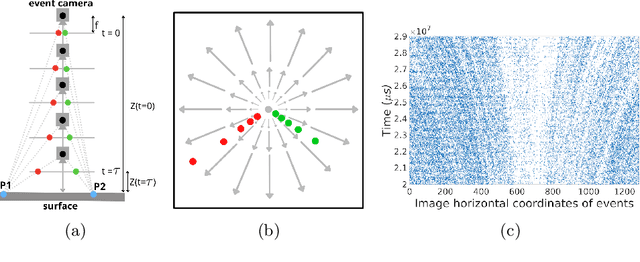

Event sensing is a major component in bio-inspired flight guidance and control systems. We explore the usage of event cameras for predicting time-to-contact (TTC) with the surface during ventral landing. This is achieved by estimating divergence (inverse TTC), which is the rate of radial optic flow, from the event stream generated during landing. Our core contributions are a novel contrast maximisation formulation for event-based divergence estimation, and a branch-and-bound algorithm to exactly maximise contrast and find the optimal divergence value. GPU acceleration is conducted to speed up the global algorithm. Another contribution is a new dataset containing real event streams from ventral landing that was employed to test and benchmark our method. Owing to global optimisation, our algorithm is much more capable at recovering the true divergence, compared to other heuristic divergence estimators or event-based optic flow methods. With GPU acceleration, our method also achieves competitive runtimes.
Doubly Reparameterized Importance Weighted Structure Learning for Scene Graph Generation
Jun 22, 2022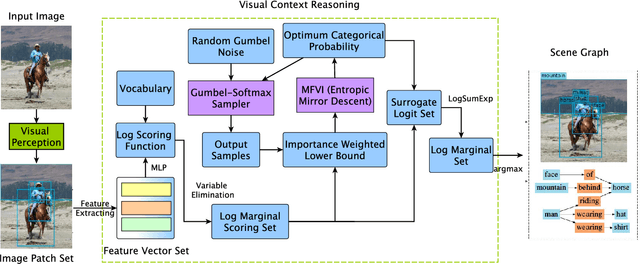
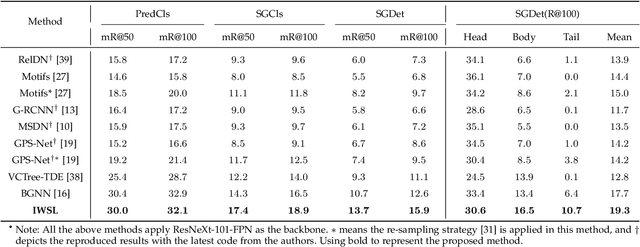
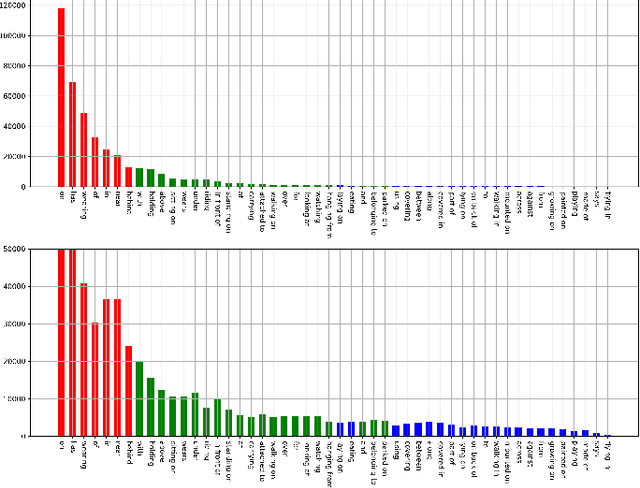
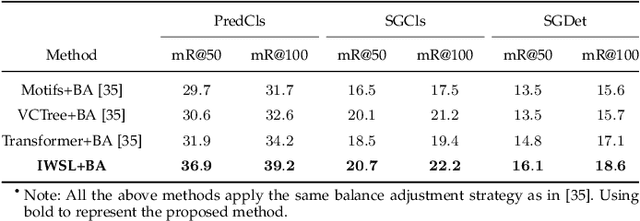
As a structured prediction task, scene graph generation, given an input image, aims to explicitly model objects and their relationships by constructing a visually-grounded scene graph. In the current literature, such task is universally solved via a message passing neural network based mean field variational Bayesian methodology. The classical loose evidence lower bound is generally chosen as the variational inference objective, which could induce oversimplified variational approximation and thus underestimate the underlying complex posterior. In this paper, we propose a novel doubly reparameterized importance weighted structure learning method, which employs a tighter importance weighted lower bound as the variational inference objective. It is computed from multiple samples drawn from a reparameterizable Gumbel-Softmax sampler and the resulting constrained variational inference task is solved by a generic entropic mirror descent algorithm. The resulting doubly reparameterized gradient estimator reduces the variance of the corresponding derivatives with a beneficial impact on learning. The proposed method achieves the state-of-the-art performance on various popular scene graph generation benchmarks.
Importance Weighted Structure Learning for Scene Graph Generation
May 14, 2022Scene graph generation is a structured prediction task aiming to explicitly model objects and their relationships via constructing a visually-grounded scene graph for an input image. Currently, the message passing neural network based mean field variational Bayesian methodology is the ubiquitous solution for such a task, in which the variational inference objective is often assumed to be the classical evidence lower bound. However, the variational approximation inferred from such loose objective generally underestimates the underlying posterior, which often leads to inferior generation performance. In this paper, we propose a novel importance weighted structure learning method aiming to approximate the underlying log-partition function with a tighter importance weighted lower bound, which is computed from multiple samples drawn from a reparameterizable Gumbel-Softmax sampler. A generic entropic mirror descent algorithm is applied to solve the resulting constrained variational inference task. The proposed method achieves the state-of-the-art performance on various popular scene graph generation benchmarks.
Asynchronous Optimisation for Event-based Visual Odometry
Mar 02, 2022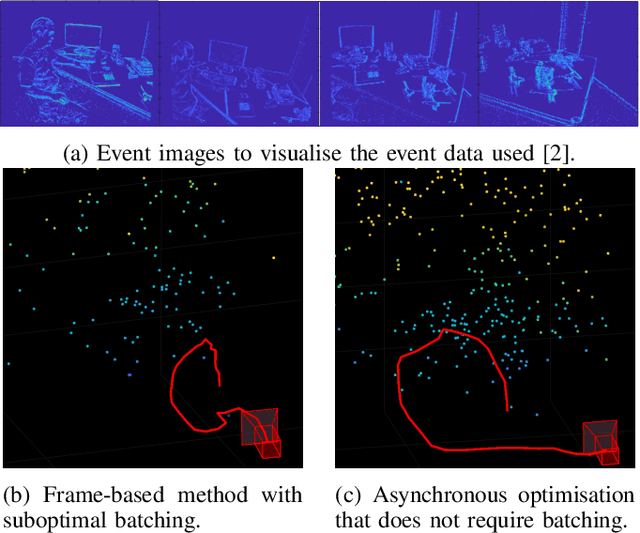


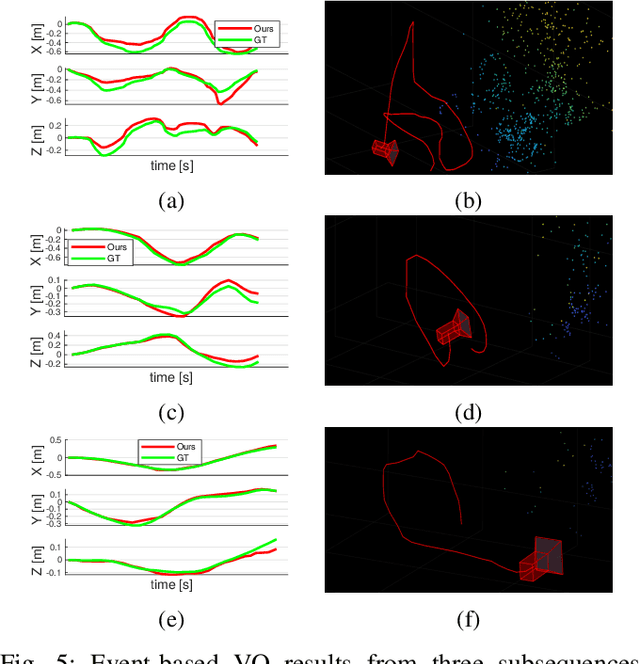
Event cameras open up new possibilities for robotic perception due to their low latency and high dynamic range. On the other hand, developing effective event-based vision algorithms that fully exploit the beneficial properties of event cameras remains work in progress. In this paper, we focus on event-based visual odometry (VO). While existing event-driven VO pipelines have adopted continuous-time representations to asynchronously process event data, they either assume a known map, restrict the camera to planar trajectories, or integrate other sensors into the system. Towards map-free event-only monocular VO in SE(3), we propose an asynchronous structure-from-motion optimisation back-end. Our formulation is underpinned by a principled joint optimisation problem involving non-parametric Gaussian Process motion modelling and incremental maximum a posteriori inference. A high-performance incremental computation engine is employed to reason about the camera trajectory with every incoming event. We demonstrate the robustness of our asynchronous back-end in comparison to frame-based methods which depend on accurate temporal accumulation of measurements.
Constrained Structure Learning for Scene Graph Generation
Jan 27, 2022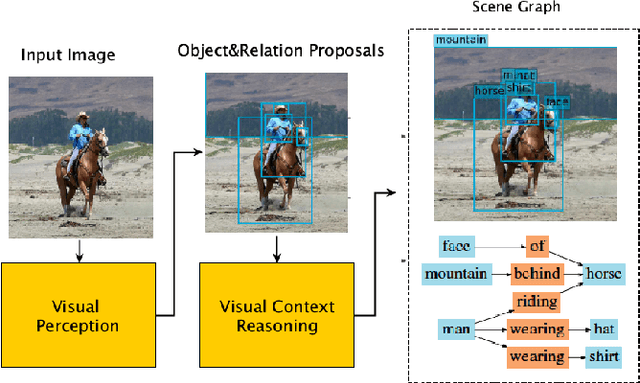
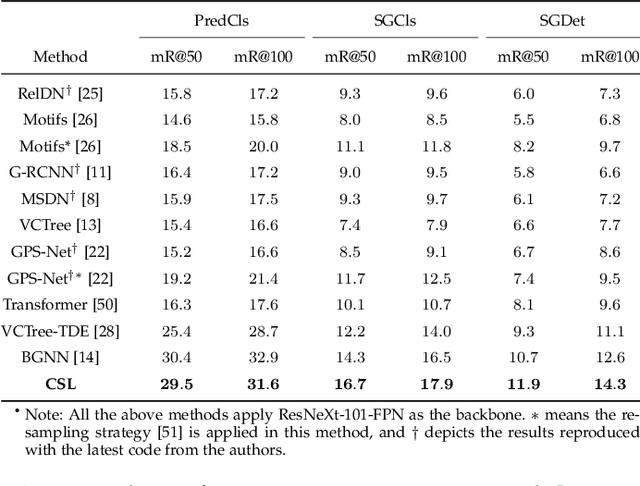
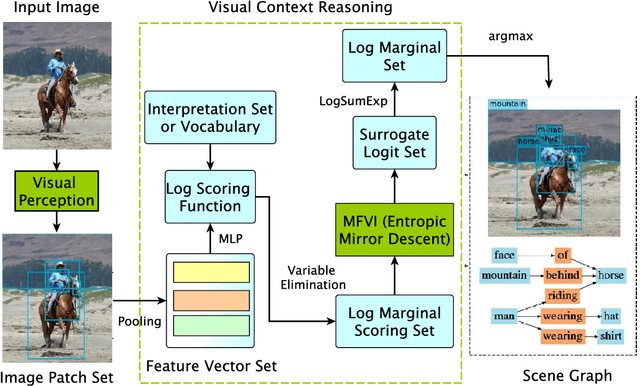
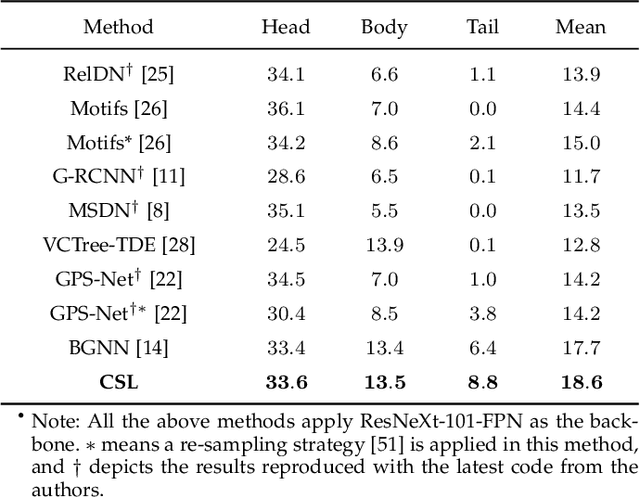
As a structured prediction task, scene graph generation aims to build a visually-grounded scene graph to explicitly model objects and their relationships in an input image. Currently, the mean field variational Bayesian framework is the de facto methodology used by the existing methods, in which the unconstrained inference step is often implemented by a message passing neural network. However, such formulation fails to explore other inference strategies, and largely ignores the more general constrained optimization models. In this paper, we present a constrained structure learning method, for which an explicit constrained variational inference objective is proposed. Instead of applying the ubiquitous message-passing strategy, a generic constrained optimization method - entropic mirror descent - is utilized to solve the constrained variational inference step. We validate the proposed generic model on various popular scene graph generation benchmarks and show that it outperforms the state-of-the-art methods.