 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiscrete-WAM: Unified Discrete Vision-Action Token Editing for World-Policy Learning
Jun 04, 2026Autonomous driving requires reasoning about how ego actions shape the evolution of the surrounding world. However, most end-to-end methods rely on direct state-to-action mappings, capturing correlations without explicitly modeling action-conditioned dynamics. Conversely, continuous-latent world models often lack compositional structure for causal reasoning across counterfactual futures. We introduce Discrete-WAM, a unified latent vision-action world policy that represents future visual states and ego actions as aligned discrete tokens, enabling compositional causal reasoning across alternative futures. Built upon this unified discrete alignment, Discrete-WAM establishes a shared discrete diffusion framework with unified generative tasks, jointly formulating world modeling, world-action policy, and hierarchical decision-enabled policy, supporting compositional generalization across diverse driving scenarios. Experiments on large-scale autonomous-driving benchmarks show that Discrete-WAM achieves competitive performance while supporting controllable generation and counterfactual reasoning, offering a principled path toward more reliable decision-making.
OneVL: One-Step Latent Reasoning and Planning with Vision-Language Explanation
Apr 20, 2026Chain-of-Thought (CoT) reasoning has become a powerful driver of trajectory prediction in VLA-based autonomous driving, yet its autoregressive nature imposes a latency cost that is prohibitive for real-time deployment. Latent CoT methods attempt to close this gap by compressing reasoning into continuous hidden states, but consistently fall short of their explicit counterparts. We suggest that this is due to purely linguistic latent representations compressing a symbolic abstraction of the world, rather than the causal dynamics that actually govern driving. Thus, we present OneVL (One-step latent reasoning and planning with Vision-Language explanations), a unified VLA and World Model framework that routes reasoning through compact latent tokens supervised by dual auxiliary decoders. Alongside a language decoder that reconstructs text CoT, we introduce a visual world model decoder that predicts future-frame tokens, forcing the latent space to internalize the causal dynamics of road geometry, agent motion, and environmental change. A three-stage training pipeline progressively aligns these latents with trajectory, language, and visual objectives, ensuring stable joint optimization. At inference, the auxiliary decoders are discarded and all latent tokens are prefilled in a single parallel pass, matching the speed of answer-only prediction. Across four benchmarks, OneVL becomes the first latent CoT method to surpass explicit CoT, delivering state-of-the-art accuracy at answer-only latency, and providing direct evidence that tighter compression, when guided in both language and world-model supervision, produces more generalizable representations than verbose token-by-token reasoning. Project Page: https://xiaomi-embodied-intelligence.github.io/OneVL
SurroundSDF: Implicit 3D Scene Understanding Based on Signed Distance Field
Mar 21, 2024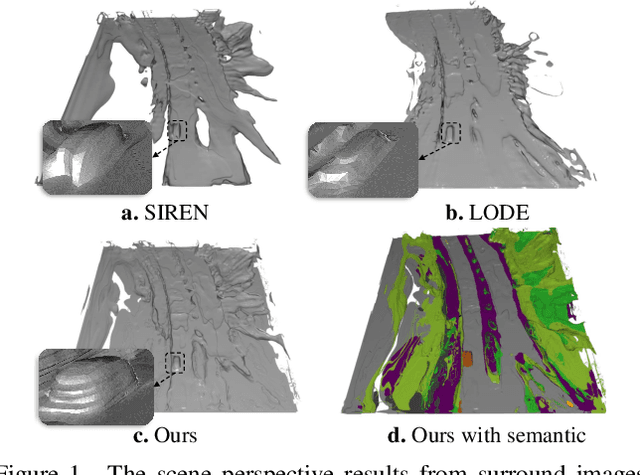



Vision-centric 3D environment understanding is both vital and challenging for autonomous driving systems. Recently, object-free methods have attracted considerable attention. Such methods perceive the world by predicting the semantics of discrete voxel grids but fail to construct continuous and accurate obstacle surfaces. To this end, in this paper, we propose SurroundSDF to implicitly predict the signed distance field (SDF) and semantic field for the continuous perception from surround images. Specifically, we introduce a query-based approach and utilize SDF constrained by the Eikonal formulation to accurately describe the surfaces of obstacles. Furthermore, considering the absence of precise SDF ground truth, we propose a novel weakly supervised paradigm for SDF, referred to as the Sandwich Eikonal formulation, which emphasizes applying correct and dense constraints on both sides of the surface, thereby enhancing the perceptual accuracy of the surface. Experiments suggest that our method achieves SOTA for both occupancy prediction and 3D scene reconstruction tasks on the nuScenes dataset.
UniOcc: Unifying Vision-Centric 3D Occupancy Prediction with Geometric and Semantic Rendering
Jun 15, 2023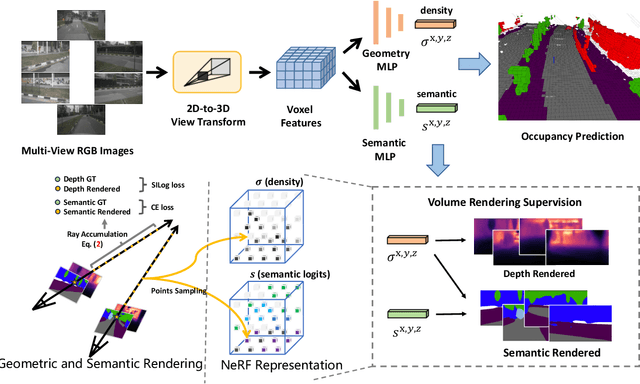
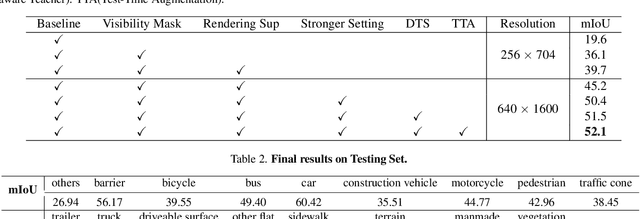
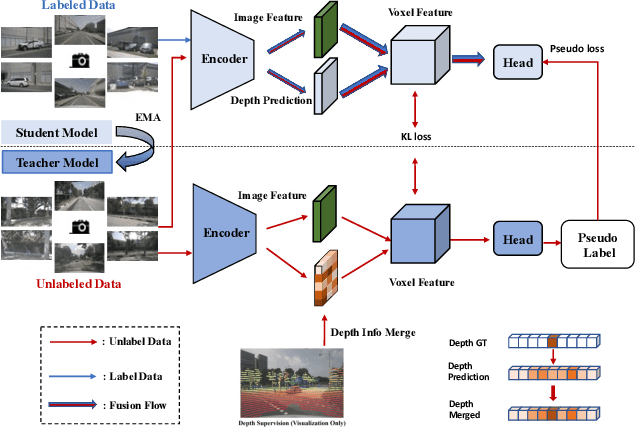

In this technical report, we present our solution, named UniOCC, for the Vision-Centric 3D occupancy prediction track in the nuScenes Open Dataset Challenge at CVPR 2023. Existing methods for occupancy prediction primarily focus on optimizing projected features on 3D volume space using 3D occupancy labels. However, the generation process of these labels is complex and expensive (relying on 3D semantic annotations), and limited by voxel resolution, they cannot provide fine-grained spatial semantics. To address this limitation, we propose a novel Unifying Occupancy (UniOcc) prediction method, explicitly imposing spatial geometry constraint and complementing fine-grained semantic supervision through volume ray rendering. Our method significantly enhances model performance and demonstrates promising potential in reducing human annotation costs. Given the laborious nature of annotating 3D occupancy, we further introduce a Depth-aware Teacher Student (DTS) framework to enhance prediction accuracy using unlabeled data. Our solution achieves 51.27\% mIoU on the official leaderboard with single model, placing 3rd in this challenge.
Learning cross space mapping via DNN using large scale click-through logs
Feb 26, 2023


The gap between low-level visual signals and high-level semantics has been progressively bridged by continuous development of deep neural network (DNN). With recent progress of DNN, almost all image classification tasks have achieved new records of accuracy. To extend the ability of DNN to image retrieval tasks, we proposed a unified DNN model for image-query similarity calculation by simultaneously modeling image and query in one network. The unified DNN is named the cross space mapping (CSM) model, which contains two parts, a convolutional part and a query-embedding part. The image and query are mapped to a common vector space via these two parts respectively, and image-query similarity is naturally defined as an inner product of their mappings in the space. To ensure good generalization ability of the DNN, we learn weights of the DNN from a large number of click-through logs which consists of 23 million clicked image-query pairs between 1 million images and 11.7 million queries. Both the qualitative results and quantitative results on an image retrieval evaluation task with 1000 queries demonstrate the superiority of the proposed method.
* Accepted by IEEE Transactions on Multimedia 2015
SFNet: Faster, Accurate, and Domain Agnostic Semantic Segmentation via Semantic Flow
Jul 10, 2022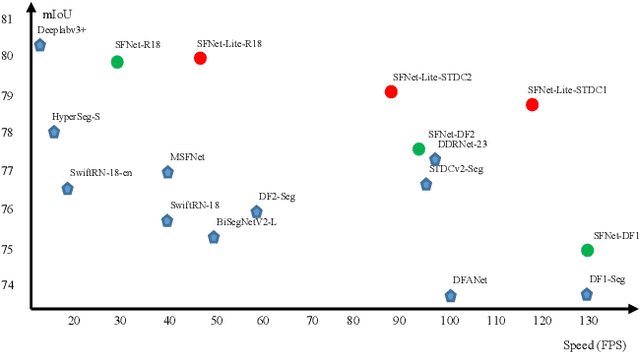



In this paper, we focus on exploring effective methods for faster, accurate, and domain agnostic semantic segmentation. Inspired by the Optical Flow for motion alignment between adjacent video frames, we propose a Flow Alignment Module (FAM) to learn \textit{Semantic Flow} between feature maps of adjacent levels, and broadcast high-level features to high resolution features effectively and efficiently. Furthermore, integrating our FAM to a common feature pyramid structure exhibits superior performance over other real-time methods even on light-weight backbone networks, such as ResNet-18 and DFNet. Then to further speed up the inference procedure, we also present a novel Gated Dual Flow Alignment Module to directly align high resolution feature maps and low resolution feature maps where we term improved version network as SFNet-Lite. Extensive experiments are conducted on several challenging datasets, where results show the effectiveness of both SFNet and SFNet-Lite. In particular, the proposed SFNet-Lite series achieve 80.1 mIoU while running at 60 FPS using ResNet-18 backbone and 78.8 mIoU while running at 120 FPS using STDC backbone on RTX-3090. Moreover, we unify four challenging driving datasets (i.e., Cityscapes, Mapillary, IDD and BDD) into one large dataset, which we named Unified Driving Segmentation (UDS) dataset. It contains diverse domain and style information. We benchmark several representative works on UDS. Both SFNet and SFNet-Lite still achieve the best speed and accuracy trade-off on UDS which serves as a strong baseline in such a new challenging setting. All the code and models are publicly available at https://github.com/lxtGH/SFSegNets.
Improving Video Instance Segmentation via Temporal Pyramid Routing
Jul 28, 2021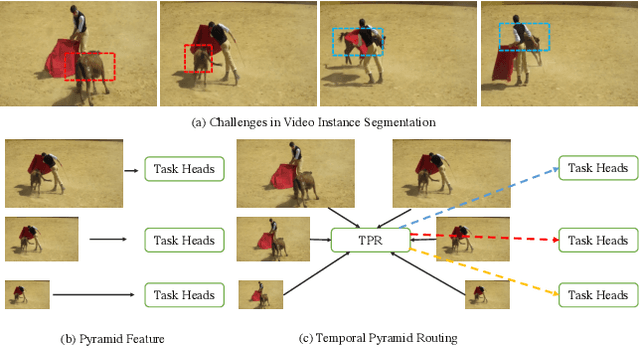
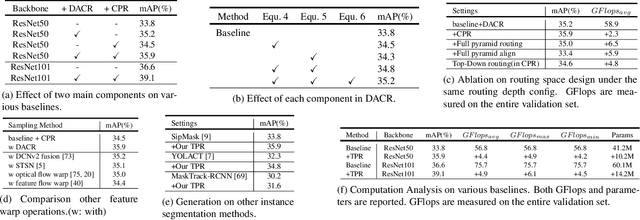
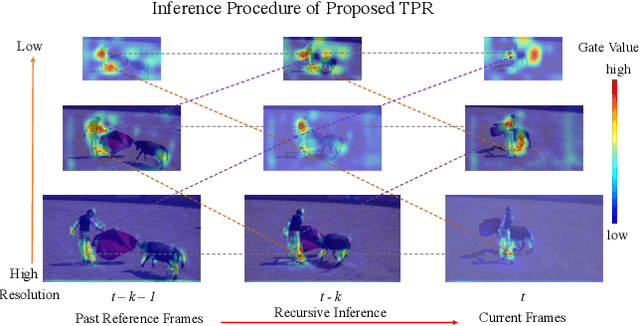
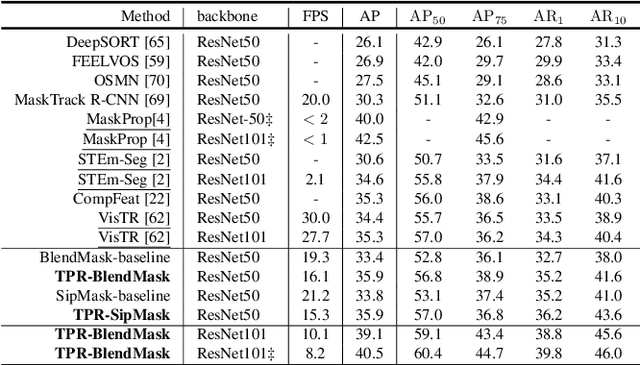
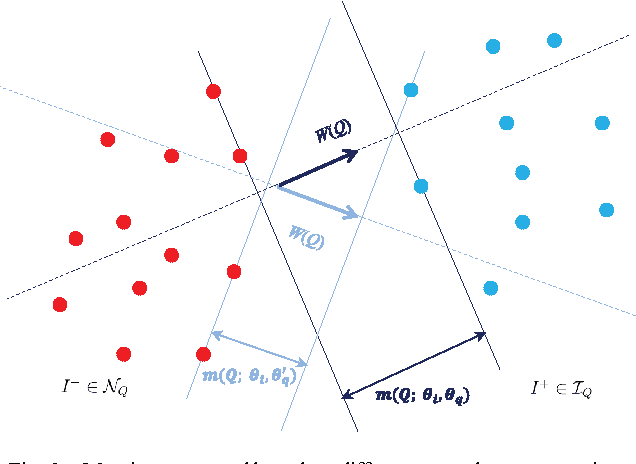
Video Instance Segmentation (VIS) is a new and inherently multi-task problem, which aims to detect, segment and track each instance in a video sequence. Existing approaches are mainly based on single-frame features or single-scale features of multiple frames, where temporal information or multi-scale information is ignored. To incorporate both temporal and scale information, we propose a Temporal Pyramid Routing (TPR) strategy to conditionally align and conduct pixel-level aggregation from a feature pyramid pair of two adjacent frames. Specifically, TPR contains two novel components, including Dynamic Aligned Cell Routing (DACR) and Cross Pyramid Routing (CPR), where DACR is designed for aligning and gating pyramid features across temporal dimension, while CPR transfers temporally aggregated features across scale dimension. Moreover, our approach is a plug-and-play module and can be easily applied to existing instance segmentation methods. Extensive experiments on YouTube-VIS dataset demonstrate the effectiveness and efficiency of the proposed approach on several state-of-the-art instance segmentation methods. Codes and trained models will be publicly available to facilitate future research.(\url{https://github.com/lxtGH/TemporalPyramidRouting}).
Global Aggregation then Local Distribution for Scene Parsing
Jul 28, 2021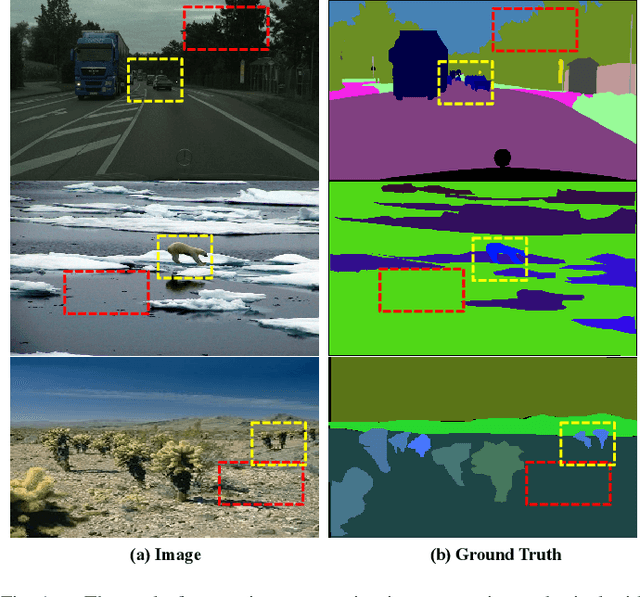
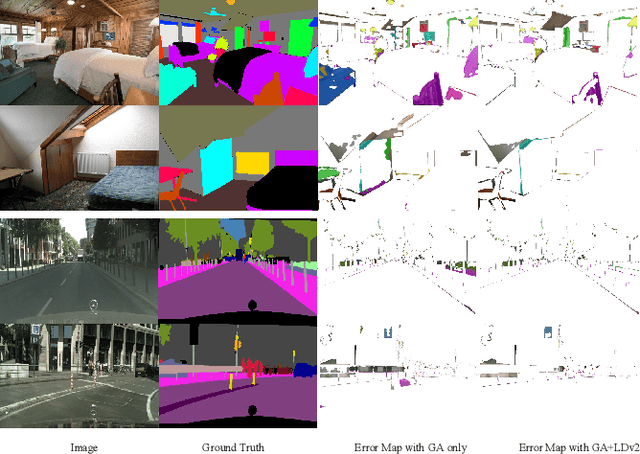

Modelling long-range contextual relationships is critical for pixel-wise prediction tasks such as semantic segmentation. However, convolutional neural networks (CNNs) are inherently limited to model such dependencies due to the naive structure in its building modules (\eg, local convolution kernel). While recent global aggregation methods are beneficial for long-range structure information modelling, they would oversmooth and bring noise to the regions containing fine details (\eg,~boundaries and small objects), which are very much cared for the semantic segmentation task. To alleviate this problem, we propose to explore the local context for making the aggregated long-range relationship being distributed more accurately in local regions. In particular, we design a novel local distribution module which models the affinity map between global and local relationship for each pixel adaptively. Integrating existing global aggregation modules, we show that our approach can be modularized as an end-to-end trainable block and easily plugged into existing semantic segmentation networks, giving rise to the \emph{GALD} networks. Despite its simplicity and versatility, our approach allows us to build new state of the art on major semantic segmentation benchmarks including Cityscapes, ADE20K, Pascal Context, Camvid and COCO-stuff. Code and trained models are released at \url{https://github.com/lxtGH/GALD-DGCNet} to foster further research.
BoundarySqueeze: Image Segmentation as Boundary Squeezing
May 25, 2021
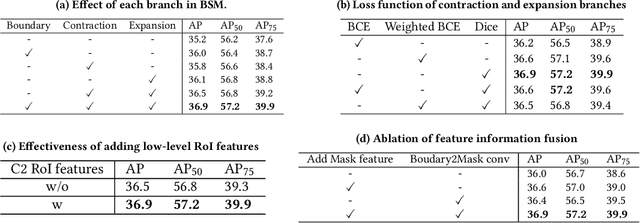

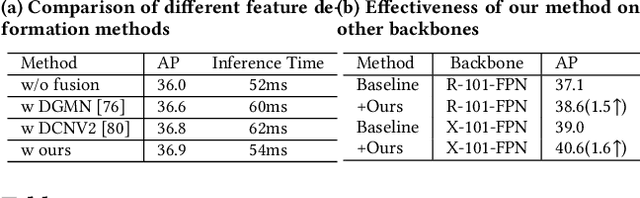
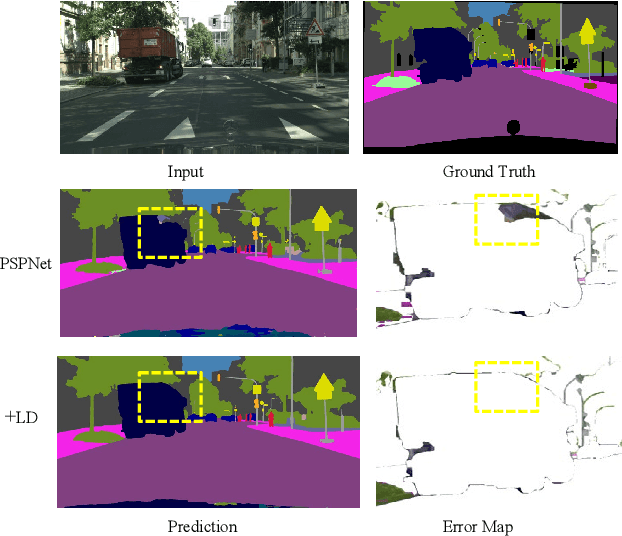
We propose a novel method for fine-grained high-quality image segmentation of both objects and scenes. Inspired by dilation and erosion from morphological image processing techniques, we treat the pixel level segmentation problems as squeezing object boundary. From this perspective, we propose \textbf{Boundary Squeeze} module: a novel and efficient module that squeezes the object boundary from both inner and outer directions which leads to precise mask representation. To generate such squeezed representation, we propose a new bidirectionally flow-based warping process and design specific loss signals to supervise the learning process. Boundary Squeeze Module can be easily applied to both instance and semantic segmentation tasks as a plug-and-play module by building on top of existing models. We show that our simple yet effective design can lead to high qualitative results on several different datasets and we also provide several different metrics on boundary to prove the effectiveness over previous work. Moreover, the proposed module is light-weighted and thus has potential for practical usage. Our method yields large gains on COCO, Cityscapes, for both instance and semantic segmentation and outperforms previous state-of-the-art PointRend in both accuracy and speed under the same setting. Code and model will be available.
Towards Efficient Scene Understanding via Squeeze Reasoning
Nov 06, 2020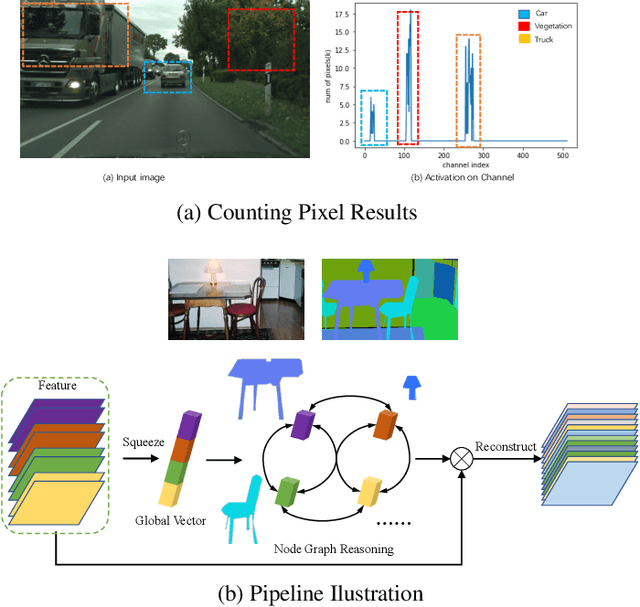

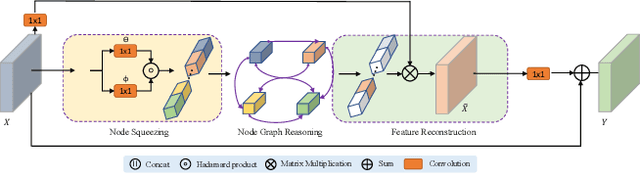
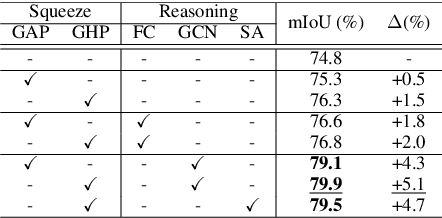
Graph-based convolutional model such as non-local block has shown to be effective for strengthening the context modeling ability in convolutional neural networks (CNNs). However, its pixel-wise computational overhead is prohibitive which renders it unsuitable for high resolution imagery. In this paper, we explore the efficiency of context graph reasoning and propose a novel framework called Squeeze Reasoning. Instead of propagating information on the spatial map, we first learn to squeeze the input feature into a channel-wise global vector and perform reasoning within the single vector where the computation cost can be significantly reduced. Specifically, we build the node graph in the vector where each node represents an abstract semantic concept. The refined feature within the same semantic category results to be consistent, which is thus beneficial for downstream tasks. We show that our approach can be modularized as an end-to-end trained block and can be easily plugged into existing networks. Despite its simplicity and being lightweight, our strategy allows us to establish a new state-of-the-art on semantic segmentation and show significant improvements with respect to strong, state-of-the-art baselines on various other scene understanding tasks including object detection, instance segmentation and panoptic segmentation. Code will be made available to foster any further research