 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSFNet: Faster, Accurate, and Domain Agnostic Semantic Segmentation via Semantic Flow
Paper and Code
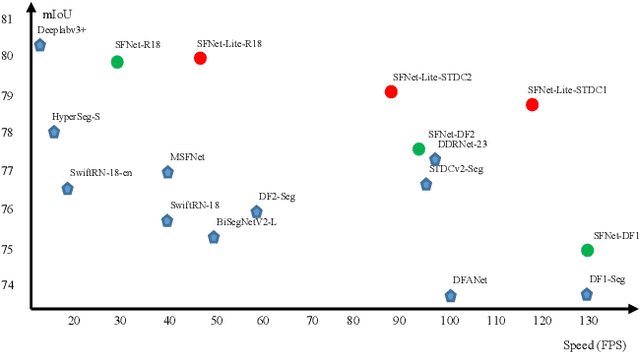



In this paper, we focus on exploring effective methods for faster, accurate, and domain agnostic semantic segmentation. Inspired by the Optical Flow for motion alignment between adjacent video frames, we propose a Flow Alignment Module (FAM) to learn \textit{Semantic Flow} between feature maps of adjacent levels, and broadcast high-level features to high resolution features effectively and efficiently. Furthermore, integrating our FAM to a common feature pyramid structure exhibits superior performance over other real-time methods even on light-weight backbone networks, such as ResNet-18 and DFNet. Then to further speed up the inference procedure, we also present a novel Gated Dual Flow Alignment Module to directly align high resolution feature maps and low resolution feature maps where we term improved version network as SFNet-Lite. Extensive experiments are conducted on several challenging datasets, where results show the effectiveness of both SFNet and SFNet-Lite. In particular, the proposed SFNet-Lite series achieve 80.1 mIoU while running at 60 FPS using ResNet-18 backbone and 78.8 mIoU while running at 120 FPS using STDC backbone on RTX-3090. Moreover, we unify four challenging driving datasets (i.e., Cityscapes, Mapillary, IDD and BDD) into one large dataset, which we named Unified Driving Segmentation (UDS) dataset. It contains diverse domain and style information. We benchmark several representative works on UDS. Both SFNet and SFNet-Lite still achieve the best speed and accuracy trade-off on UDS which serves as a strong baseline in such a new challenging setting. All the code and models are publicly available at https://github.com/lxtGH/SFSegNets.