 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSOP: A Scalable Online Post-Training System for Vision-Language-Action Models
Jan 06, 2026Vision-language-action (VLA) models achieve strong generalization through large-scale pre-training, but real-world deployment requires expert-level task proficiency in addition to broad generality. Existing post-training approaches for VLA models are typically offline, single-robot, or task-specific, limiting effective on-policy adaptation and scalable learning from real-world interaction. We introduce a Scalable Online Post-training (SOP) system that enables online, distributed, multi-task post-training of generalist VLA models directly in the physical world. SOP tightly couples execution and learning through a closed-loop architecture in which a fleet of robots continuously streams on-policy experience and human intervention signals to a centralized cloud learner, and asynchronously receives updated policies. This design supports prompt on-policy correction, scales experience collection through parallel deployment, and preserves generality during adaptation. SOP is agnostic to the choice of post-training algorithm; we instantiate it with both interactive imitation learning (HG-DAgger) and reinforcement learning (RECAP). Across a range of real-world manipulation tasks including cloth folding, box assembly, and grocery restocking, we show that SOP substantially improves the performance of large pretrained VLA models while maintaining a single shared policy across tasks. Effective post-training can be achieved within hours of real-world interaction, and performance scales near-linearly with the number of robots in the fleet. These results suggest that tightly coupling online learning with fleet-scale deployment is instrumental to enabling efficient, reliable, and scalable post-training of generalist robot policies in the physical world.
CheckManual: A New Challenge and Benchmark for Manual-based Appliance Manipulation
Jun 11, 2025Correct use of electrical appliances has significantly improved human life quality. Unlike simple tools that can be manipulated with common sense, different parts of electrical appliances have specific functions defined by manufacturers. If we want the robot to heat bread by microwave, we should enable them to review the microwave manual first. From the manual, it can learn about component functions, interaction methods, and representative task steps about appliances. However, previous manual-related works remain limited to question-answering tasks while existing manipulation researchers ignore the manual's important role and fail to comprehend multi-page manuals. In this paper, we propose the first manual-based appliance manipulation benchmark CheckManual. Specifically, we design a large model-assisted human-revised data generation pipeline to create manuals based on CAD appliance models. With these manuals, we establish novel manual-based manipulation challenges, metrics, and simulator environments for model performance evaluation. Furthermore, we propose the first manual-based manipulation planning model ManualPlan to set up a group of baselines for the CheckManual benchmark.
OmniManip: Towards General Robotic Manipulation via Object-Centric Interaction Primitives as Spatial Constraints
Jan 07, 2025



The development of general robotic systems capable of manipulating in unstructured environments is a significant challenge. While Vision-Language Models(VLM) excel in high-level commonsense reasoning, they lack the fine-grained 3D spatial understanding required for precise manipulation tasks. Fine-tuning VLM on robotic datasets to create Vision-Language-Action Models(VLA) is a potential solution, but it is hindered by high data collection costs and generalization issues. To address these challenges, we propose a novel object-centric representation that bridges the gap between VLM's high-level reasoning and the low-level precision required for manipulation. Our key insight is that an object's canonical space, defined by its functional affordances, provides a structured and semantically meaningful way to describe interaction primitives, such as points and directions. These primitives act as a bridge, translating VLM's commonsense reasoning into actionable 3D spatial constraints. In this context, we introduce a dual closed-loop, open-vocabulary robotic manipulation system: one loop for high-level planning through primitive resampling, interaction rendering and VLM checking, and another for low-level execution via 6D pose tracking. This design ensures robust, real-time control without requiring VLM fine-tuning. Extensive experiments demonstrate strong zero-shot generalization across diverse robotic manipulation tasks, highlighting the potential of this approach for automating large-scale simulation data generation.
LiDAR-LLM: Exploring the Potential of Large Language Models for 3D LiDAR Understanding
Dec 21, 2023Recently, Large Language Models (LLMs) and Multimodal Large Language Models (MLLMs) have shown promise in instruction following and 2D image understanding. While these models are powerful, they have not yet been developed to comprehend the more challenging 3D physical scenes, especially when it comes to the sparse outdoor LiDAR data. In this paper, we introduce LiDAR-LLM, which takes raw LiDAR data as input and harnesses the remarkable reasoning capabilities of LLMs to gain a comprehensive understanding of outdoor 3D scenes. The central insight of our LiDAR-LLM is the reformulation of 3D outdoor scene cognition as a language modeling problem, encompassing tasks such as 3D captioning, 3D grounding, 3D question answering, etc. Specifically, due to the scarcity of 3D LiDAR-text pairing data, we introduce a three-stage training strategy and generate relevant datasets, progressively aligning the 3D modality with the language embedding space of LLM. Furthermore, we design a View-Aware Transformer (VAT) to connect the 3D encoder with the LLM, which effectively bridges the modality gap and enhances the LLM's spatial orientation comprehension of visual features. Our experiments show that LiDAR-LLM possesses favorable capabilities to comprehend various instructions regarding 3D scenes and engage in complex spatial reasoning. LiDAR-LLM attains a 40.9 BLEU-1 on the 3D captioning task and achieves a 63.1\% classification accuracy and a 14.3\% BEV mIoU on the 3D grounding task. Web page: https://sites.google.com/view/lidar-llm
RenderOcc: Vision-Centric 3D Occupancy Prediction with 2D Rendering Supervision
Sep 18, 2023



3D occupancy prediction holds significant promise in the fields of robot perception and autonomous driving, which quantifies 3D scenes into grid cells with semantic labels. Recent works mainly utilize complete occupancy labels in 3D voxel space for supervision. However, the expensive annotation process and sometimes ambiguous labels have severely constrained the usability and scalability of 3D occupancy models. To address this, we present RenderOcc, a novel paradigm for training 3D occupancy models only using 2D labels. Specifically, we extract a NeRF-style 3D volume representation from multi-view images, and employ volume rendering techniques to establish 2D renderings, thus enabling direct 3D supervision from 2D semantics and depth labels. Additionally, we introduce an Auxiliary Ray method to tackle the issue of sparse viewpoints in autonomous driving scenarios, which leverages sequential frames to construct comprehensive 2D rendering for each object. To our best knowledge, RenderOcc is the first attempt to train multi-view 3D occupancy models only using 2D labels, reducing the dependence on costly 3D occupancy annotations. Extensive experiments demonstrate that RenderOcc achieves comparable performance to models fully supervised with 3D labels, underscoring the significance of this approach in real-world applications.
DiffuseIR:Diffusion Models For Isotropic Reconstruction of 3D Microscopic Images
Jun 21, 2023



Three-dimensional microscopy is often limited by anisotropic spatial resolution, resulting in lower axial resolution than lateral resolution. Current State-of-The-Art (SoTA) isotropic reconstruction methods utilizing deep neural networks can achieve impressive super-resolution performance in fixed imaging settings. However, their generality in practical use is limited by degraded performance caused by artifacts and blurring when facing unseen anisotropic factors. To address these issues, we propose DiffuseIR, an unsupervised method for isotropic reconstruction based on diffusion models. First, we pre-train a diffusion model to learn the structural distribution of biological tissue from lateral microscopic images, resulting in generating naturally high-resolution images. Then we use low-axial-resolution microscopy images to condition the generation process of the diffusion model and generate high-axial-resolution reconstruction results. Since the diffusion model learns the universal structural distribution of biological tissues, which is independent of the axial resolution, DiffuseIR can reconstruct authentic images with unseen low-axial resolutions into a high-axial resolution without requiring re-training. The proposed DiffuseIR achieves SoTA performance in experiments on EM data and can even compete with supervised methods.
UniOcc: Unifying Vision-Centric 3D Occupancy Prediction with Geometric and Semantic Rendering
Jun 15, 2023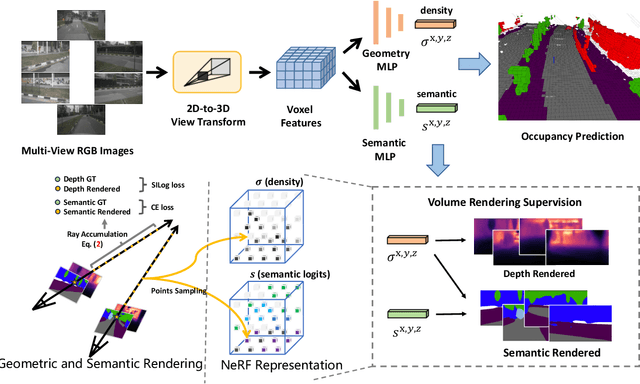
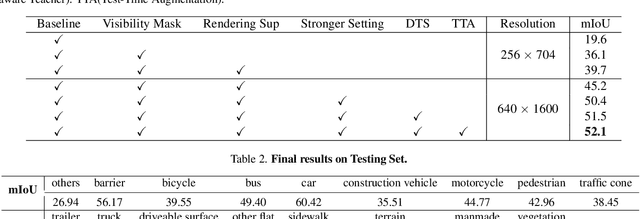
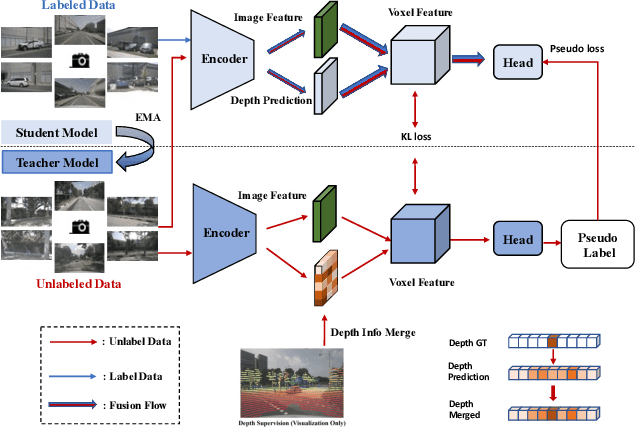

In this technical report, we present our solution, named UniOCC, for the Vision-Centric 3D occupancy prediction track in the nuScenes Open Dataset Challenge at CVPR 2023. Existing methods for occupancy prediction primarily focus on optimizing projected features on 3D volume space using 3D occupancy labels. However, the generation process of these labels is complex and expensive (relying on 3D semantic annotations), and limited by voxel resolution, they cannot provide fine-grained spatial semantics. To address this limitation, we propose a novel Unifying Occupancy (UniOcc) prediction method, explicitly imposing spatial geometry constraint and complementing fine-grained semantic supervision through volume ray rendering. Our method significantly enhances model performance and demonstrates promising potential in reducing human annotation costs. Given the laborious nature of annotating 3D occupancy, we further introduce a Depth-aware Teacher Student (DTS) framework to enhance prediction accuracy using unlabeled data. Our solution achieves 51.27\% mIoU on the official leaderboard with single model, placing 3rd in this challenge.
Exploring Sparse Visual Prompt for Cross-domain Semantic Segmentation
Mar 17, 2023Visual Domain Prompts (VDP) have shown promising potential in addressing visual cross-domain problems. Existing methods adopt VDP in classification domain adaptation (DA), such as tuning image-level or feature-level prompts for target domains. Since the previous dense prompts are opaque and mask out continuous spatial details in the prompt regions, it will suffer from inaccurate contextual information extraction and insufficient domain-specific feature transferring when dealing with the dense prediction (i.e. semantic segmentation) DA problems. Therefore, we propose a novel Sparse Visual Domain Prompts (SVDP) approach tailored for addressing domain shift problems in semantic segmentation, which holds minimal discrete trainable parameters (e.g. 10\%) of the prompt and reserves more spatial information. To better apply SVDP, we propose Domain Prompt Placement (DPP) method to adaptively distribute several SVDP on regions with large data distribution distance based on uncertainty guidance. It aims to extract more local domain-specific knowledge and realizes efficient cross-domain learning. Furthermore, we design a Domain Prompt Updating (DPU) method to optimize prompt parameters differently for each target domain sample with different degrees of domain shift, which helps SVDP to better fit target domain knowledge. Experiments, which are conducted on the widely-used benchmarks (Cityscapes, Foggy-Cityscapes, and ACDC), show that our proposed method achieves state-of-the-art performances on the source-free adaptations, including six Test Time Adaptation and one Continual Test-Time Adaptation in semantic segmentation.
Cloud-Device Collaborative Adaptation to Continual Changing Environments in the Real-world
Dec 02, 2022
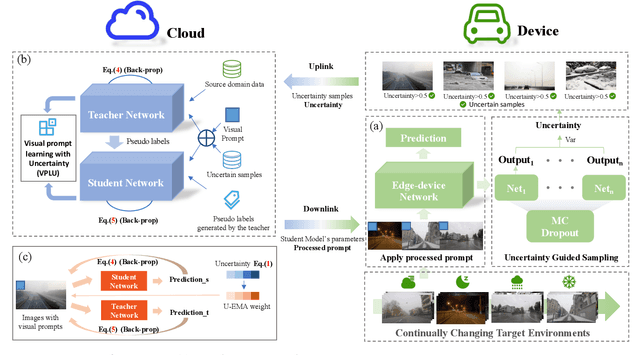
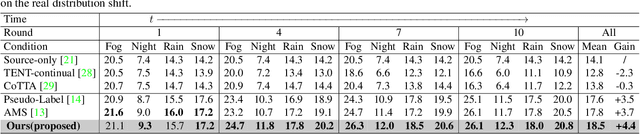
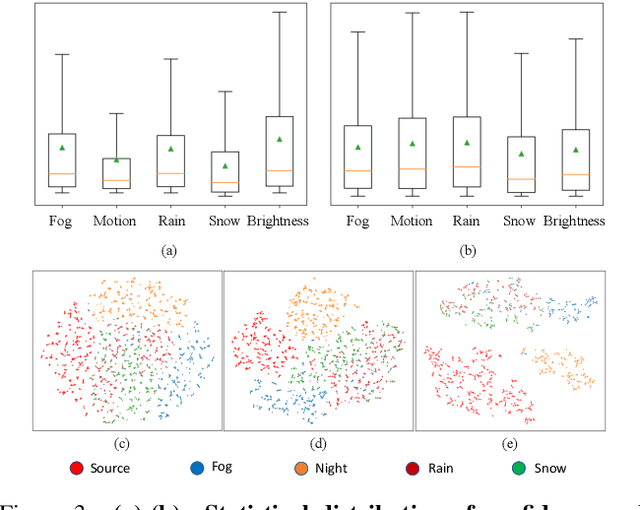
When facing changing environments in the real world, the lightweight model on client devices suffers from severe performance drops under distribution shifts. The main limitations of the existing device model lie in (1) unable to update due to the computation limit of the device, (2) the limited generalization ability of the lightweight model. Meanwhile, recent large models have shown strong generalization capability on the cloud while they can not be deployed on client devices due to poor computation constraints. To enable the device model to deal with changing environments, we propose a new learning paradigm of Cloud-Device Collaborative Continual Adaptation, which encourages collaboration between cloud and device and improves the generalization of the device model. Based on this paradigm, we further propose an Uncertainty-based Visual Prompt Adapted (U-VPA) teacher-student model to transfer the generalization capability of the large model on the cloud to the device model. Specifically, we first design the Uncertainty Guided Sampling (UGS) to screen out challenging data continuously and transmit the most out-of-distribution samples from the device to the cloud. Then we propose a Visual Prompt Learning Strategy with Uncertainty guided updating (VPLU) to specifically deal with the selected samples with more distribution shifts. We transmit the visual prompts to the device and concatenate them with the incoming data to pull the device testing distribution closer to the cloud training distribution. We conduct extensive experiments on two object detection datasets with continually changing environments. Our proposed U-VPA teacher-student framework outperforms previous state-of-the-art test time adaptation and device-cloud collaboration methods. The code and datasets will be released.