 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInteger or Floating Point? New Outlooks for Low-Bit Quantization on Large Language Models
May 21, 2023



Efficient deployment of large language models (LLMs) necessitates low-bit quantization to minimize model size and inference cost. While low-bit integer formats (e.g., INT8/INT4) have been the conventional choice, emerging low-bit floating-point formats (e.g., FP8/FP4) offer a compelling alternative and are gaining support from cutting-edge hardware, such as NVIDIA's H100 GPU. However, the superiority of low-bit INT versus FP formats for quantization on LLMs remains unclear. In this study, we conduct a comparative analysis of INT and FP quantization with the same bit-width, revealing that the optimal quantization format varies across different layers due to the complexity and diversity of tensor distribution. Consequently, we advocate the Mixture of Formats Quantization (MoFQ), which selects the optimal format on a layer-wise basis. This simple yet effective approach achieves state-of-the-art results in both weight-only (W-only) and weight-activation (WA) post-training quantization scenarios when tested on LLaMA across various tasks. In 4-bit W-only quantization, MoFQ surpasses GPTQ without complex hyperparameter tuning and with an order of magnitude faster quantization speed. While in 8-bit WA quantization, MoFQ significantly outperforms INT/FP-only methods, achieving performance close to the full precision model. Notably, MoFQ incurs no hardware overhead compared to INT/FP-only quantization, as the bit-width remains unchanged.
Cloud-Device Collaborative Adaptation to Continual Changing Environments in the Real-world
Dec 02, 2022
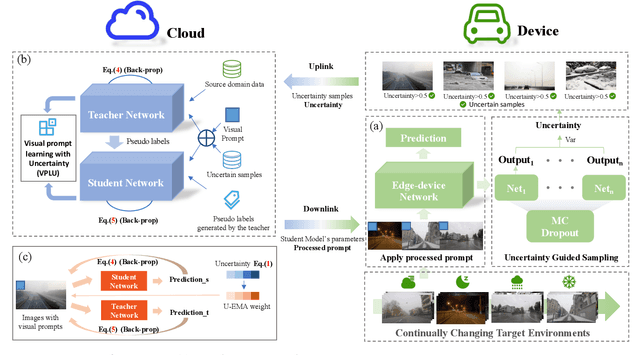
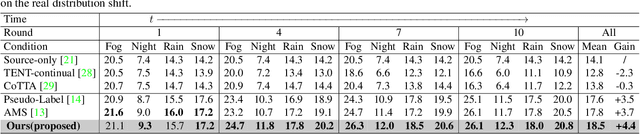
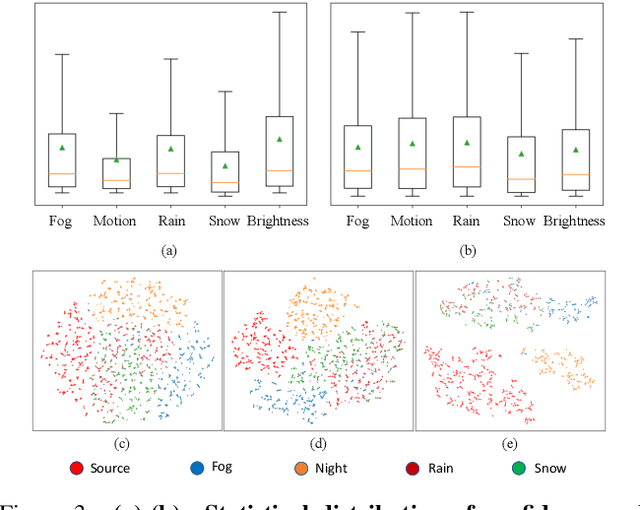
When facing changing environments in the real world, the lightweight model on client devices suffers from severe performance drops under distribution shifts. The main limitations of the existing device model lie in (1) unable to update due to the computation limit of the device, (2) the limited generalization ability of the lightweight model. Meanwhile, recent large models have shown strong generalization capability on the cloud while they can not be deployed on client devices due to poor computation constraints. To enable the device model to deal with changing environments, we propose a new learning paradigm of Cloud-Device Collaborative Continual Adaptation, which encourages collaboration between cloud and device and improves the generalization of the device model. Based on this paradigm, we further propose an Uncertainty-based Visual Prompt Adapted (U-VPA) teacher-student model to transfer the generalization capability of the large model on the cloud to the device model. Specifically, we first design the Uncertainty Guided Sampling (UGS) to screen out challenging data continuously and transmit the most out-of-distribution samples from the device to the cloud. Then we propose a Visual Prompt Learning Strategy with Uncertainty guided updating (VPLU) to specifically deal with the selected samples with more distribution shifts. We transmit the visual prompts to the device and concatenate them with the incoming data to pull the device testing distribution closer to the cloud training distribution. We conduct extensive experiments on two object detection datasets with continually changing environments. Our proposed U-VPA teacher-student framework outperforms previous state-of-the-art test time adaptation and device-cloud collaboration methods. The code and datasets will be released.
Analysis of Quantization on MLP-based Vision Models
Sep 14, 2022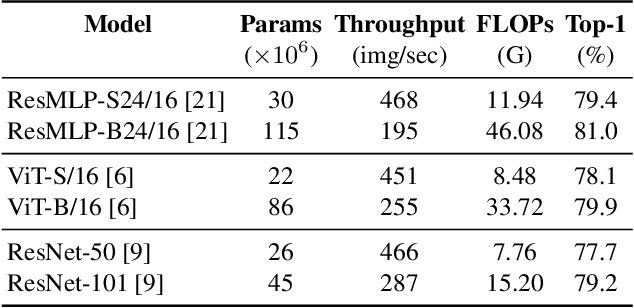

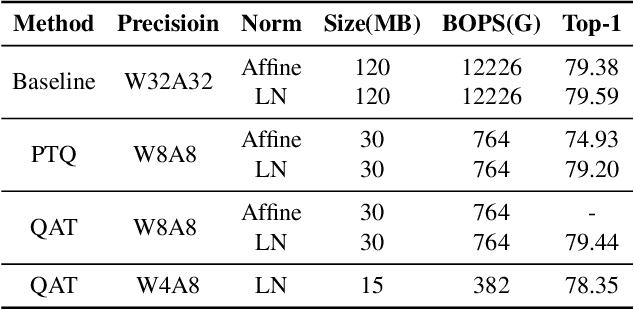
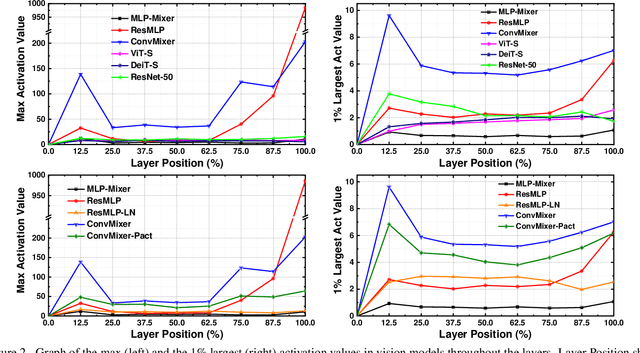
Quantization is wildly taken as a model compression technique, which obtains efficient models by converting floating-point weights and activations in the neural network into lower-bit integers. Quantization has been proven to work well on convolutional neural networks and transformer-based models. Despite the decency of these models, recent works have shown that MLP-based models are able to achieve comparable results on various tasks ranging from computer vision, NLP to 3D point cloud, while achieving higher throughput due to the parallelism and network simplicity. However, as we show in the paper, directly applying quantization to MLP-based models will lead to significant accuracy degradation. Based on our analysis, two major issues account for the accuracy gap: 1) the range of activations in MLP-based models can be too large to quantize, and 2) specific components in the MLP-based models are sensitive to quantization. Consequently, we propose to 1) apply LayerNorm to control the quantization range of activations, 2) utilize bounded activation functions, 3) apply percentile quantization on activations, 4) use our improved module named multiple token-mixing MLPs, and 5) apply linear asymmetric quantizer for sensitive operations. Equipped with the abovementioned techniques, our Q-MLP models can achieve 79.68% accuracy on ImageNet with 8-bit uniform quantization (model size 30 MB) and 78.47% with 4-bit quantization (15 MB).