 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReason-IAD: Knowledge-Guided Dynamic Latent Reasoning for Explainable Industrial Anomaly Detection
Feb 10, 2026Industrial anomaly detection demands precise reasoning over fine-grained defect patterns. However, existing multimodal large language models (MLLMs), pretrained on general-domain data, often struggle to capture category-specific anomalies, thereby limiting both detection accuracy and interpretability. To address these limitations, we propose Reason-IAD, a knowledge-guided dynamic latent reasoning framework for explainable industrial anomaly detection. Reason-IAD comprises two core components. First, a retrieval-augmented knowledge module incorporates category-specific textual descriptions into the model input, enabling context-aware reasoning over domain-specific defects. Second, an entropy-driven latent reasoning mechanism conducts iterative exploration within a compact latent space using optimizable latent think tokens, guided by an entropy-based reward that encourages confident and stable predictions. Furthermore, a dynamic visual injection strategy selectively incorporates the most informative image patches into the latent sequence, directing the reasoning process toward regions critical for anomaly detection. Extensive experimental results demonstrate that Reason-IAD consistently outperforms state-of-the-art methods. The code will be publicly available at https://github.com/chenpeng052/Reason-IAD.
Text Adversarial Attacks with Dynamic Outputs
Sep 26, 2025Text adversarial attack methods are typically designed for static scenarios with fixed numbers of output labels and a predefined label space, relying on extensive querying of the victim model (query-based attacks) or the surrogate model (transfer-based attacks). To address this gap, we introduce the Textual Dynamic Outputs Attack (TDOA) method, which employs a clustering-based surrogate model training approach to convert the dynamic-output scenario into a static single-output scenario. To improve attack effectiveness, we propose the farthest-label targeted attack strategy, which selects adversarial vectors that deviate most from the model's coarse-grained labels, thereby maximizing disruption. We extensively evaluate TDOA on four datasets and eight victim models (e.g., ChatGPT-4o, ChatGPT-4.1), showing its effectiveness in crafting adversarial examples and its strong potential to compromise large language models with limited access. With a single query per text, TDOA achieves a maximum attack success rate of 50.81\%. Additionally, we find that TDOA also achieves state-of-the-art performance in conventional static output scenarios, reaching a maximum ASR of 82.68\%. Meanwhile, by conceptualizing translation tasks as classification problems with unbounded output spaces, we extend the TDOA framework to generative settings, surpassing prior results by up to 0.64 RDBLEU and 0.62 RDchrF.
Incomplete In-context Learning
May 12, 2025Large vision language models (LVLMs) achieve remarkable performance through Vision In-context Learning (VICL), a process that depends significantly on demonstrations retrieved from an extensive collection of annotated examples (retrieval database). Existing studies often assume that the retrieval database contains annotated examples for all labels. However, in real-world scenarios, delays in database updates or incomplete data annotation may result in the retrieval database containing labeled samples for only a subset of classes. We refer to this phenomenon as an \textbf{incomplete retrieval database} and define the in-context learning under this condition as \textbf{Incomplete In-context Learning (IICL)}. To address this challenge, we propose \textbf{Iterative Judgments and Integrated Prediction (IJIP)}, a two-stage framework designed to mitigate the limitations of IICL. The Iterative Judgments Stage reformulates an \(\boldsymbol{m}\)-class classification problem into a series of \(\boldsymbol{m}\) binary classification tasks, effectively converting the IICL setting into a standard VICL scenario. The Integrated Prediction Stage further refines the classification process by leveraging both the input image and the predictions from the Iterative Judgments Stage to enhance overall classification accuracy. IJIP demonstrates considerable performance across two LVLMs and two datasets under three distinct conditions of label incompleteness, achieving the highest accuracy of 93.9\%. Notably, even in scenarios where labels are fully available, IJIP still achieves the best performance of all six baselines. Furthermore, IJIP can be directly applied to \textbf{Prompt Learning} and is adaptable to the \textbf{text domain}.
No Query, No Access
May 12, 2025Textual adversarial attacks mislead NLP models, including Large Language Models (LLMs), by subtly modifying text. While effective, existing attacks often require knowledge of the victim model, extensive queries, or access to training data, limiting real-world feasibility. To overcome these constraints, we introduce the \textbf{Victim Data-based Adversarial Attack (VDBA)}, which operates using only victim texts. To prevent access to the victim model, we create a shadow dataset with publicly available pre-trained models and clustering methods as a foundation for developing substitute models. To address the low attack success rate (ASR) due to insufficient information feedback, we propose the hierarchical substitution model design, generating substitute models to mitigate the failure of a single substitute model at the decision boundary. Concurrently, we use diverse adversarial example generation, employing various attack methods to generate and select the adversarial example with better similarity and attack effectiveness. Experiments on the Emotion and SST5 datasets show that VDBA outperforms state-of-the-art methods, achieving an ASR improvement of 52.08\% while significantly reducing attack queries to 0. More importantly, we discover that VDBA poses a significant threat to LLMs such as Qwen2 and the GPT family, and achieves the highest ASR of 45.99% even without access to the API, confirming that advanced NLP models still face serious security risks. Our codes can be found at https://anonymous.4open.science/r/VDBA-Victim-Data-based-Adversarial-Attack-36EC/
ROMA: a Read-Only-Memory-based Accelerator for QLoRA-based On-Device LLM
Mar 17, 2025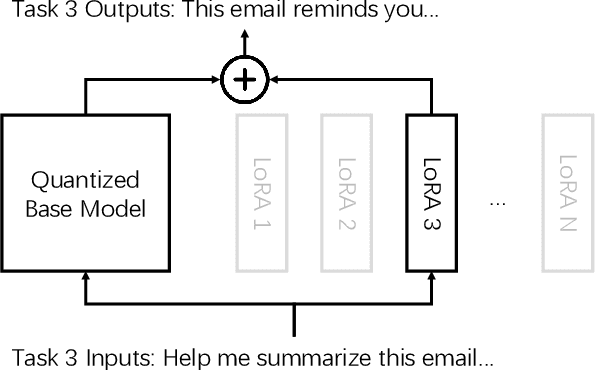
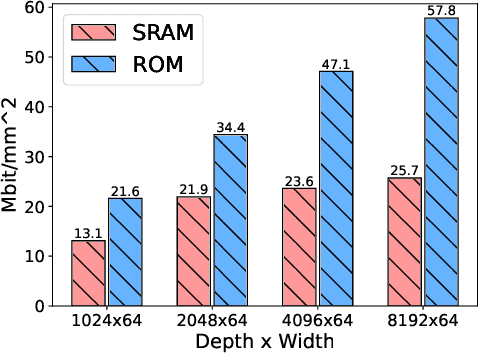
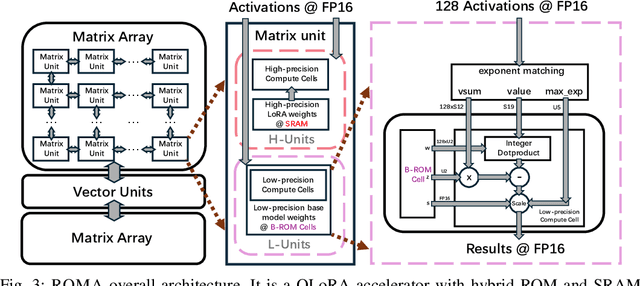
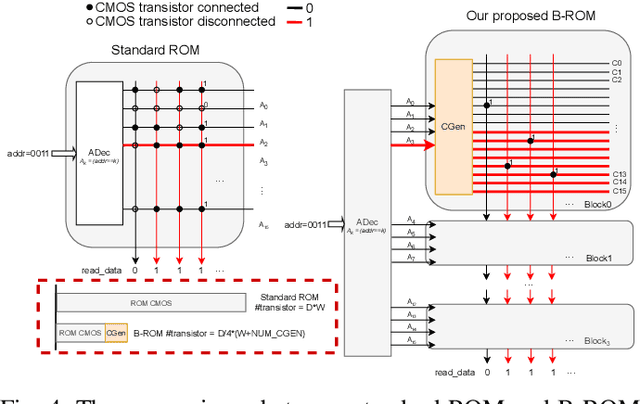
As large language models (LLMs) demonstrate powerful capabilities, deploying them on edge devices has become increasingly crucial, offering advantages in privacy and real-time interaction. QLoRA has emerged as the standard approach for on-device LLMs, leveraging quantized models to reduce memory and computational costs while utilizing LoRA for task-specific adaptability. In this work, we propose ROMA, a QLoRA accelerator with a hybrid storage architecture that uses ROM for quantized base models and SRAM for LoRA weights and KV cache. Our insight is that the quantized base model is stable and converged, making it well-suited for ROM storage. Meanwhile, LoRA modules offer the flexibility to adapt to new data without requiring updates to the base model. To further reduce the area cost of ROM, we introduce a novel B-ROM design and integrate it with the compute unit to form a fused cell for efficient use of chip resources. ROMA can effectively store both a 4-bit 3B and a 2-bit 8B LLaMA model entirely on-chip, achieving a notable generation speed exceeding 20,000 tokens/s without requiring external memory.
Integer or Floating Point? New Outlooks for Low-Bit Quantization on Large Language Models
May 21, 2023



Efficient deployment of large language models (LLMs) necessitates low-bit quantization to minimize model size and inference cost. While low-bit integer formats (e.g., INT8/INT4) have been the conventional choice, emerging low-bit floating-point formats (e.g., FP8/FP4) offer a compelling alternative and are gaining support from cutting-edge hardware, such as NVIDIA's H100 GPU. However, the superiority of low-bit INT versus FP formats for quantization on LLMs remains unclear. In this study, we conduct a comparative analysis of INT and FP quantization with the same bit-width, revealing that the optimal quantization format varies across different layers due to the complexity and diversity of tensor distribution. Consequently, we advocate the Mixture of Formats Quantization (MoFQ), which selects the optimal format on a layer-wise basis. This simple yet effective approach achieves state-of-the-art results in both weight-only (W-only) and weight-activation (WA) post-training quantization scenarios when tested on LLaMA across various tasks. In 4-bit W-only quantization, MoFQ surpasses GPTQ without complex hyperparameter tuning and with an order of magnitude faster quantization speed. While in 8-bit WA quantization, MoFQ significantly outperforms INT/FP-only methods, achieving performance close to the full precision model. Notably, MoFQ incurs no hardware overhead compared to INT/FP-only quantization, as the bit-width remains unchanged.
Accelerate Three-Dimensional Generative Adversarial Networks Using Fast Algorithm
Oct 18, 2022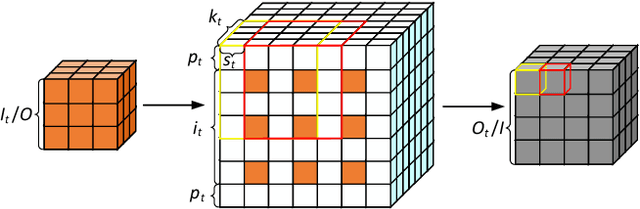
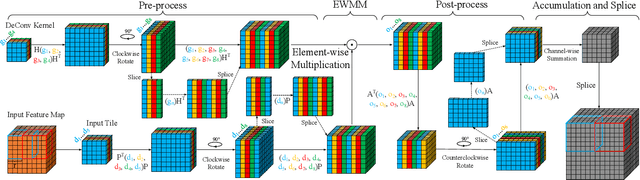
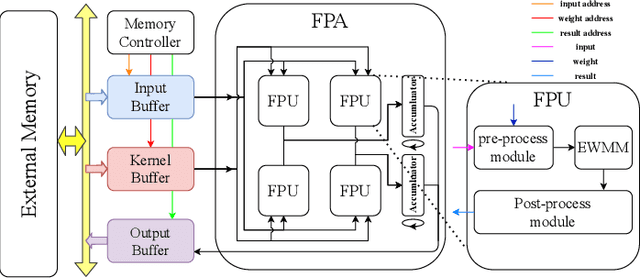
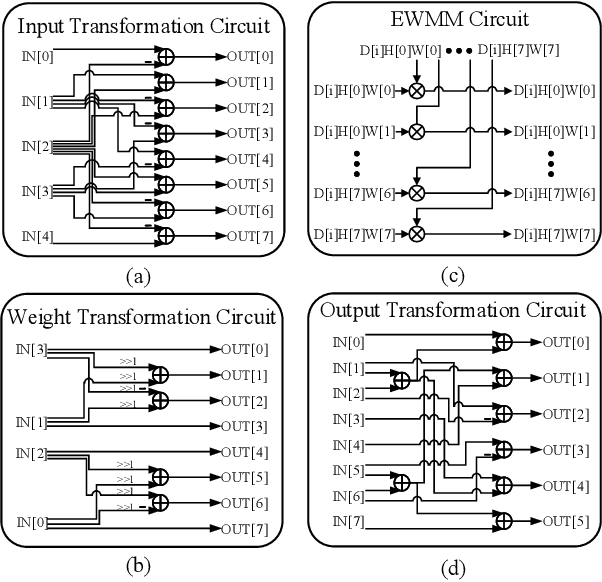
Three-dimensional generative adversarial networks (3D-GAN) have attracted widespread attention in three-dimension (3D) visual tasks. 3D deconvolution (DeConv), as an important computation of 3D-GAN, significantly increases computational complexity compared with 2D DeConv. 3D DeConv has become a bottleneck for the acceleration of 3D-GAN. Previous accelerators suffer from several problems, such as large memory requirements and resource underutilization. To handle the above issues, a fast algorithm for 3D DeConv (F3DC) is proposed in this paper. F3DC applies a fast algorithm to reduce the number of multiplications and achieves a significant algorithmic strength reduction. Besides, F3DC removes the extra memory requirement for overlapped partial sums and avoids computational imbalance to fully utilize resources. Moreover, we design an F3DC-based hardware architecture, which consists of four fast processing units (FPUs). Each FPU includes a pre-process module, a EWMM module and a post-process module for F3DC transformation. By implementing our design on the Xilinx VC709 platform for 3D-GAN, we achieve a throughput up to 1700 GOPS and 4$\times$ computational efficiency improvement compared with prior works.