 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBiPreManip: Learning Affordance-Based Bimanual Preparatory Manipulation through Anticipatory Collaboration
Mar 23, 2026Many everyday objects are difficult to directly grasp (e.g., a flat iPad) or manipulate functionally (e.g., opening the cap of a pen lying on a desk). Such tasks require sequential, asymmetric coordination between two arms, where one arm performs preparatory manipulation that enables the other's goal-directed action - for instance, pushing the iPad to the table's edge before picking it up, or lifting the pen body to allow the other hand to remove its cap. In this work, we introduce Collaborative Preparatory Manipulation, a class of bimanual manipulation tasks that demand understanding object semantics and geometry, anticipating spatial relationships, and planning long-horizon coordinated actions between the two arms. To tackle this challenge, we propose a visual affordance-based framework that first envisions the final goal-directed action and then guides one arm to perform a sequence of preparatory manipulations that facilitate the other arm's subsequent operation. This affordance-centric representation enables anticipatory inter-arm reasoning and coordination, generalizing effectively across various objects spanning diverse categories. Extensive experiments in both simulation and the real world demonstrate that our approach substantially improves task success rates and generalization compared to competitive baselines.
AnchorVLA4D: an Anchor-Based Spatial-Temporal Vision-Language-Action Model for Robotic Manipulation
Mar 13, 2026Since current Vision-Language-Action (VLA) systems suffer from limited spatial perception and the absence of memory throughout manipulation, we investigate visual anchors as a means to enhance spatial and temporal reasoning within VLA policies for robotic manipulation. Conventional VLAs generate actions by conditioning on a single current frame together with a language instruction. However, since the frame is encoded as a 2D image, it does not contain detailed spatial information, and the VLA similarly lacks any means to incorporate past context. As a result, it frequently forgets objects under occlusion and becomes spatially disoriented during the manipulation process. Thus, we propose AnchorVLA4D, a simple spatial-temporal VLA that augments the visual input with an anchor image to preserve the initial scene context throughout execution, and adds a lightweight spatial encoder that jointly processes the anchor and current frames to expose geometric relationships within an episode. Built on a Qwen2.5-VL backbone with a diffusion-based action head, AnchorVLA4D requires no additional sensing modalities (e.g., depth or point clouds) and introduces negligible inference overhead. Combining anchoring with a frozen pretrained spatial encoder yields further gains, realizing a 13.6% improvement on the Simpler WidowX benchmark and confirming the approach on real-world tasks, where it achieved an average success rate of 80%.
Real2Edit2Real: Generating Robotic Demonstrations via a 3D Control Interface
Dec 22, 2025Recent progress in robot learning has been driven by large-scale datasets and powerful visuomotor policy architectures, yet policy robustness remains limited by the substantial cost of collecting diverse demonstrations, particularly for spatial generalization in manipulation tasks. To reduce repetitive data collection, we present Real2Edit2Real, a framework that generates new demonstrations by bridging 3D editability with 2D visual data through a 3D control interface. Our approach first reconstructs scene geometry from multi-view RGB observations with a metric-scale 3D reconstruction model. Based on the reconstructed geometry, we perform depth-reliable 3D editing on point clouds to generate new manipulation trajectories while geometrically correcting the robot poses to recover physically consistent depth, which serves as a reliable condition for synthesizing new demonstrations. Finally, we propose a multi-conditional video generation model guided by depth as the primary control signal, together with action, edge, and ray maps, to synthesize spatially augmented multi-view manipulation videos. Experiments on four real-world manipulation tasks demonstrate that policies trained on data generated from only 1-5 source demonstrations can match or outperform those trained on 50 real-world demonstrations, improving data efficiency by up to 10-50x. Moreover, experimental results on height and texture editing demonstrate the framework's flexibility and extensibility, indicating its potential to serve as a unified data generation framework.
BEVUDA++: Geometric-aware Unsupervised Domain Adaptation for Multi-View 3D Object Detection
Sep 17, 2025Vision-centric Bird's Eye View (BEV) perception holds considerable promise for autonomous driving. Recent studies have prioritized efficiency or accuracy enhancements, yet the issue of domain shift has been overlooked, leading to substantial performance degradation upon transfer. We identify major domain gaps in real-world cross-domain scenarios and initiate the first effort to address the Domain Adaptation (DA) challenge in multi-view 3D object detection for BEV perception. Given the complexity of BEV perception approaches with their multiple components, domain shift accumulation across multi-geometric spaces (e.g., 2D, 3D Voxel, BEV) poses a significant challenge for BEV domain adaptation. In this paper, we introduce an innovative geometric-aware teacher-student framework, BEVUDA++, to diminish this issue, comprising a Reliable Depth Teacher (RDT) and a Geometric Consistent Student (GCS) model. Specifically, RDT effectively blends target LiDAR with dependable depth predictions to generate depth-aware information based on uncertainty estimation, enhancing the extraction of Voxel and BEV features that are essential for understanding the target domain. To collaboratively reduce the domain shift, GCS maps features from multiple spaces into a unified geometric embedding space, thereby narrowing the gap in data distribution between the two domains. Additionally, we introduce a novel Uncertainty-guided Exponential Moving Average (UEMA) to further reduce error accumulation due to domain shifts informed by previously obtained uncertainty guidance. To demonstrate the superiority of our proposed method, we execute comprehensive experiments in four cross-domain scenarios, securing state-of-the-art performance in BEV 3D object detection tasks, e.g., 12.9\% NDS and 9.5\% mAP enhancement on Day-Night adaptation.
BiAssemble: Learning Collaborative Affordance for Bimanual Geometric Assembly
Jun 06, 2025Shape assembly, the process of combining parts into a complete whole, is a crucial robotic skill with broad real-world applications. Among various assembly tasks, geometric assembly--where broken parts are reassembled into their original form (e.g., reconstructing a shattered bowl)--is particularly challenging. This requires the robot to recognize geometric cues for grasping, assembly, and subsequent bimanual collaborative manipulation on varied fragments. In this paper, we exploit the geometric generalization of point-level affordance, learning affordance aware of bimanual collaboration in geometric assembly with long-horizon action sequences. To address the evaluation ambiguity caused by geometry diversity of broken parts, we introduce a real-world benchmark featuring geometric variety and global reproducibility. Extensive experiments demonstrate the superiority of our approach over both previous affordance-based and imitation-based methods. Project page: https://sites.google.com/view/biassembly/.
SR3D: Unleashing Single-view 3D Reconstruction for Transparent and Specular Object Grasping
May 30, 2025Recent advancements in 3D robotic manipulation have improved grasping of everyday objects, but transparent and specular materials remain challenging due to depth sensing limitations. While several 3D reconstruction and depth completion approaches address these challenges, they suffer from setup complexity or limited observation information utilization. To address this, leveraging the power of single view 3D object reconstruction approaches, we propose a training free framework SR3D that enables robotic grasping of transparent and specular objects from a single view observation. Specifically, given single view RGB and depth images, SR3D first uses the external visual models to generate 3D reconstructed object mesh based on RGB image. Then, the key idea is to determine the 3D object's pose and scale to accurately localize the reconstructed object back into its original depth corrupted 3D scene. Therefore, we propose view matching and keypoint matching mechanisms,which leverage both the 2D and 3D's inherent semantic and geometric information in the observation to determine the object's 3D state within the scene, thereby reconstructing an accurate 3D depth map for effective grasp detection. Experiments in both simulation and real world show the reconstruction effectiveness of SR3D.
Facial Recognition Leveraging Generative Adversarial Networks
May 17, 2025



Face recognition performance based on deep learning heavily relies on large-scale training data, which is often difficult to acquire in practical applications. To address this challenge, this paper proposes a GAN-based data augmentation method with three key contributions: (1) a residual-embedded generator to alleviate gradient vanishing/exploding problems, (2) an Inception ResNet-V1 based FaceNet discriminator for improved adversarial training, and (3) an end-to-end framework that jointly optimizes data generation and recognition performance. Experimental results demonstrate that our approach achieves stable training dynamics and significantly improves face recognition accuracy by 12.7% on the LFW benchmark compared to baseline methods, while maintaining good generalization capability with limited training samples.
Towards Understanding Deep Learning Model in Image Recognition via Coverage Test
May 12, 2025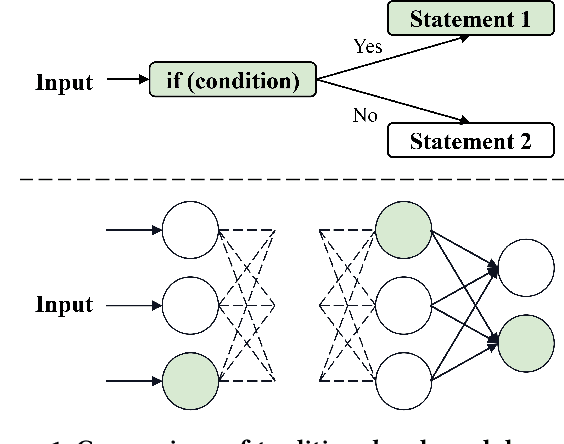
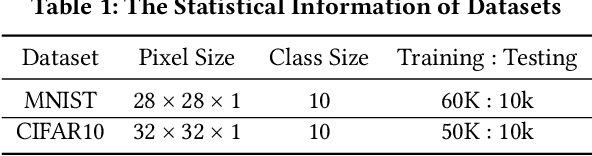
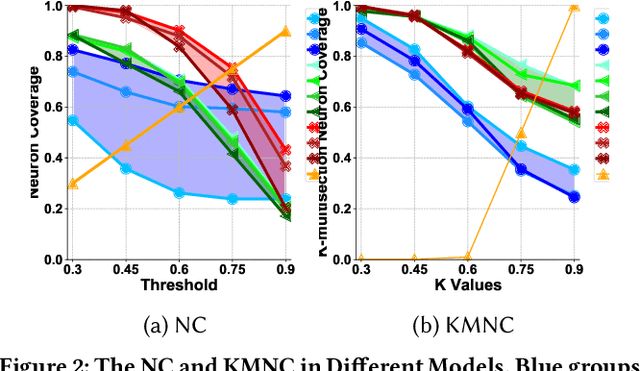
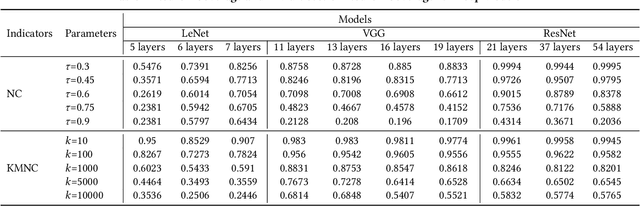
Deep neural networks (DNNs) play a crucial role in the field of artificial intelligence, and their security-related testing has been a prominent research focus. By inputting test cases, the behavior of models is examined for anomalies, and coverage metrics are utilized to determine the extent of neurons covered by these test cases. With the widespread application and advancement of DNNs, different types of neural behaviors have garnered attention, leading to the emergence of various coverage metrics for neural networks. However, there is currently a lack of empirical research on these coverage metrics, specifically in analyzing the relationships and patterns between model depth, configuration information, and neural network coverage. This paper aims to investigate the relationships and patterns of four coverage metrics: primary functionality, boundary, hierarchy, and structural coverage. A series of empirical experiments were conducted, selecting LeNet, VGG, and ResNet as different DNN architectures, along with 10 models of varying depths ranging from 5 to 54 layers, to compare and study the relationships between different depths, configuration information, and various neural network coverage metrics. Additionally, an investigation was carried out on the relationships between modified decision/condition coverage and dataset size. Finally, three potential future directions are proposed to further contribute to the security testing of DNN Models.
CrayonRobo: Object-Centric Prompt-Driven Vision-Language-Action Model for Robotic Manipulation
May 04, 2025In robotic, task goals can be conveyed through various modalities, such as language, goal images, and goal videos. However, natural language can be ambiguous, while images or videos may offer overly detailed specifications. To tackle these challenges, we introduce CrayonRobo that leverages comprehensive multi-modal prompts that explicitly convey both low-level actions and high-level planning in a simple manner. Specifically, for each key-frame in the task sequence, our method allows for manual or automatic generation of simple and expressive 2D visual prompts overlaid on RGB images. These prompts represent the required task goals, such as the end-effector pose and the desired movement direction after contact. We develop a training strategy that enables the model to interpret these visual-language prompts and predict the corresponding contact poses and movement directions in SE(3) space. Furthermore, by sequentially executing all key-frame steps, the model can complete long-horizon tasks. This approach not only helps the model explicitly understand the task objectives but also enhances its robustness on unseen tasks by providing easily interpretable prompts. We evaluate our method in both simulated and real-world environments, demonstrating its robust manipulation capabilities.
3DWG: 3D Weakly Supervised Visual Grounding via Category and Instance-Level Alignment
May 03, 2025The 3D weakly-supervised visual grounding task aims to localize oriented 3D boxes in point clouds based on natural language descriptions without requiring annotations to guide model learning. This setting presents two primary challenges: category-level ambiguity and instance-level complexity. Category-level ambiguity arises from representing objects of fine-grained categories in a highly sparse point cloud format, making category distinction challenging. Instance-level complexity stems from multiple instances of the same category coexisting in a scene, leading to distractions during grounding. To address these challenges, we propose a novel weakly-supervised grounding approach that explicitly differentiates between categories and instances. In the category-level branch, we utilize extensive category knowledge from a pre-trained external detector to align object proposal features with sentence-level category features, thereby enhancing category awareness. In the instance-level branch, we utilize spatial relationship descriptions from language queries to refine object proposal features, ensuring clear differentiation among objects. These designs enable our model to accurately identify target-category objects while distinguishing instances within the same category. Compared to previous methods, our approach achieves state-of-the-art performance on three widely used benchmarks: Nr3D, Sr3D, and ScanRef.