 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFastCode: Fast and Cost-Efficient Code Understanding and Reasoning
Mar 03, 2026Repository-scale code reasoning is a cornerstone of modern AI-assisted software engineering, enabling Large Language Models (LLMs) to handle complex workflows from program comprehension to complex debugging. However, balancing accuracy with context cost remains a significant bottleneck, as existing agentic approaches often waste computational resources through inefficient, iterative full-text exploration. To address this, we introduce FastCode, a framework that decouples repository exploration from content consumption. FastCode utilizes a structural scouting mechanism to navigate a lightweight semantic-structural map of the codebase, allowing the system to trace dependencies and pinpoint relevant targets without the overhead of full-text ingestion. By leveraging structure-aware navigation tools regulated by a cost-aware policy, the framework constructs high-value contexts in a single, optimized step. Extensive evaluations on the SWE-QA, LongCodeQA, LOC-BENCH, and GitTaskBench benchmarks demonstrate that FastCode consistently outperforms state-of-the-art baselines in reasoning accuracy while significantly reducing token consumption, validating the efficiency of scouting-first strategies for large-scale code reasoning. Source code is available at https://github.com/HKUDS/FastCode.
UltraLogic: Enhancing LLM Reasoning through Large-Scale Data Synthesis and Bipolar Float Reward
Jan 06, 2026While Large Language Models (LLMs) have demonstrated significant potential in natural language processing , complex general-purpose reasoning requiring multi-step logic, planning, and verification remains a critical bottleneck. Although Reinforcement Learning with Verifiable Rewards (RLVR) has succeeded in specific domains , the field lacks large-scale, high-quality, and difficulty-calibrated data for general reasoning. To address this, we propose UltraLogic, a framework that decouples the logical core of a problem from its natural language expression through a Code-based Solving methodology to automate high-quality data production. The framework comprises hundreds of unique task types and an automated calibration pipeline across ten difficulty levels. Furthermore, to mitigate binary reward sparsity and the Non-negative Reward Trap, we introduce the Bipolar Float Reward (BFR) mechanism, utilizing graded penalties to effectively distinguish perfect responses from those with logical flaws. Our experiments demonstrate that task diversity is the primary driver for reasoning enhancement , and that BFR, combined with a difficulty matching strategy, significantly improves training efficiency, guiding models toward global logical optima.
DeepCode: Open Agentic Coding
Dec 08, 2025Recent advances in large language models (LLMs) have given rise to powerful coding agents, making it possible for code assistants to evolve into code engineers. However, existing methods still face significant challenges in achieving high-fidelity document-to-codebase synthesis--such as scientific papers to code--primarily due to a fundamental conflict between information overload and the context bottlenecks of LLMs. In this work, we introduce DeepCode, a fully autonomous framework that fundamentally addresses this challenge through principled information-flow management. By treating repository synthesis as a channel optimization problem, DeepCode seamlessly orchestrates four information operations to maximize task-relevant signals under finite context budgets: source compression via blueprint distillation, structured indexing using stateful code memory, conditional knowledge injection via retrieval-augmented generation, and closed-loop error correction. Extensive evaluations on the PaperBench benchmark demonstrate that DeepCode achieves state-of-the-art performance, decisively outperforming leading commercial agents such as Cursor and Claude Code, and crucially, surpassing PhD-level human experts from top institutes on key reproduction metrics. By systematically transforming paper specifications into production-grade implementations comparable to human expert quality, this work establishes new foundations for autonomous scientific reproduction that can accelerate research evaluation and discovery.
Hunyuan-TurboS: Advancing Large Language Models through Mamba-Transformer Synergy and Adaptive Chain-of-Thought
May 21, 2025As Large Language Models (LLMs) rapidly advance, we introduce Hunyuan-TurboS, a novel large hybrid Transformer-Mamba Mixture of Experts (MoE) model. It synergistically combines Mamba's long-sequence processing efficiency with Transformer's superior contextual understanding. Hunyuan-TurboS features an adaptive long-short chain-of-thought (CoT) mechanism, dynamically switching between rapid responses for simple queries and deep "thinking" modes for complex problems, optimizing computational resources. Architecturally, this 56B activated (560B total) parameter model employs 128 layers (Mamba2, Attention, FFN) with an innovative AMF/MF block pattern. Faster Mamba2 ensures linear complexity, Grouped-Query Attention minimizes KV cache, and FFNs use an MoE structure. Pre-trained on 16T high-quality tokens, it supports a 256K context length and is the first industry-deployed large-scale Mamba model. Our comprehensive post-training strategy enhances capabilities via Supervised Fine-Tuning (3M instructions), a novel Adaptive Long-short CoT Fusion method, Multi-round Deliberation Learning for iterative improvement, and a two-stage Large-scale Reinforcement Learning process targeting STEM and general instruction-following. Evaluations show strong performance: overall top 7 rank on LMSYS Chatbot Arena with a score of 1356, outperforming leading models like Gemini-2.0-Flash-001 (1352) and o4-mini-2025-04-16 (1345). TurboS also achieves an average of 77.9% across 23 automated benchmarks. Hunyuan-TurboS balances high performance and efficiency, offering substantial capabilities at lower inference costs than many reasoning models, establishing a new paradigm for efficient large-scale pre-trained models.
Facial Recognition Leveraging Generative Adversarial Networks
May 17, 2025



Face recognition performance based on deep learning heavily relies on large-scale training data, which is often difficult to acquire in practical applications. To address this challenge, this paper proposes a GAN-based data augmentation method with three key contributions: (1) a residual-embedded generator to alleviate gradient vanishing/exploding problems, (2) an Inception ResNet-V1 based FaceNet discriminator for improved adversarial training, and (3) an end-to-end framework that jointly optimizes data generation and recognition performance. Experimental results demonstrate that our approach achieves stable training dynamics and significantly improves face recognition accuracy by 12.7% on the LFW benchmark compared to baseline methods, while maintaining good generalization capability with limited training samples.
SCALM: Detecting Bad Practices in Smart Contracts Through LLMs
Feb 04, 2025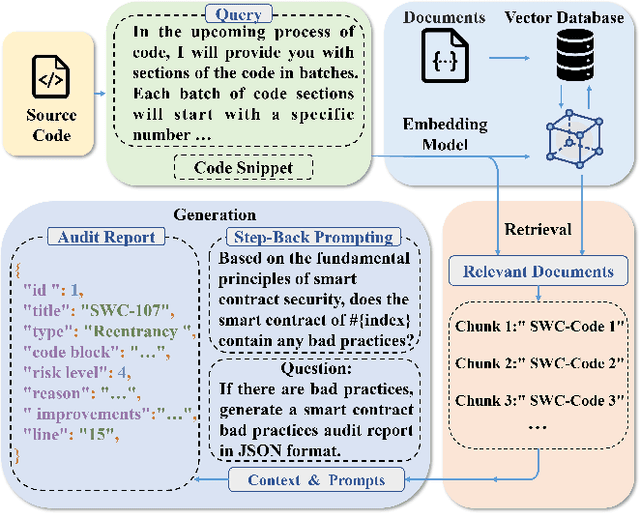

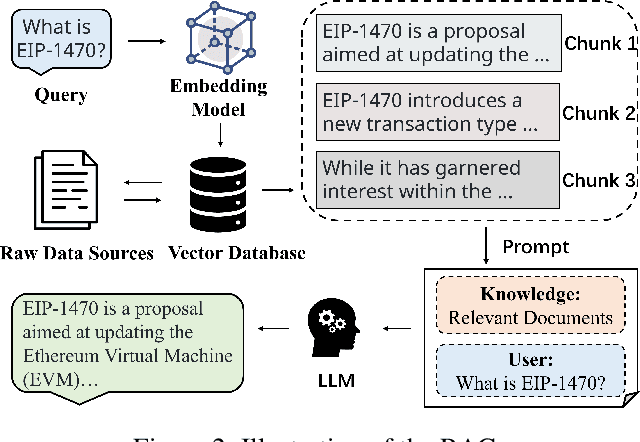
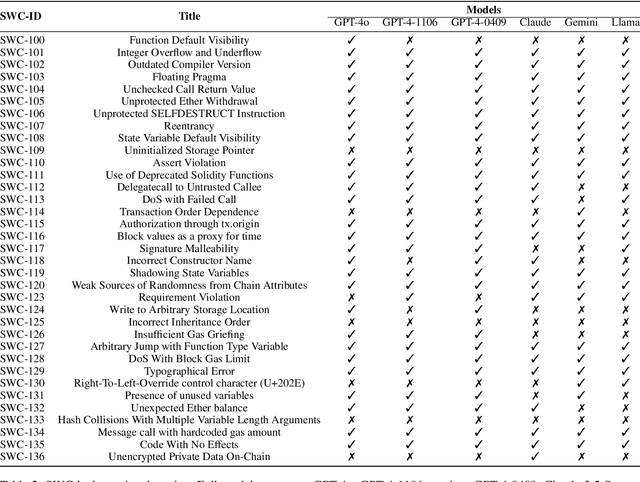
As the Ethereum platform continues to mature and gain widespread usage, it is crucial to maintain high standards of smart contract writing practices. While bad practices in smart contracts may not directly lead to security issues, they do elevate the risk of encountering problems. Therefore, to understand and avoid these bad practices, this paper introduces the first systematic study of bad practices in smart contracts, delving into over 35 specific issues. Specifically, we propose a large language models (LLMs)-based framework, SCALM. It combines Step-Back Prompting and Retrieval-Augmented Generation (RAG) to identify and address various bad practices effectively. Our extensive experiments using multiple LLMs and datasets have shown that SCALM outperforms existing tools in detecting bad practices in smart contracts.
DiffGraph: Heterogeneous Graph Diffusion Model
Jan 04, 2025



Recent advances in Graph Neural Networks (GNNs) have revolutionized graph-structured data modeling, yet traditional GNNs struggle with complex heterogeneous structures prevalent in real-world scenarios. Despite progress in handling heterogeneous interactions, two fundamental challenges persist: noisy data significantly compromising embedding quality and learning performance, and existing methods' inability to capture intricate semantic transitions among heterogeneous relations, which impacts downstream predictions. To address these fundamental issues, we present the Heterogeneous Graph Diffusion Model (DiffGraph), a pioneering framework that introduces an innovative cross-view denoising strategy. This advanced approach transforms auxiliary heterogeneous data into target semantic spaces, enabling precise distillation of task-relevant information. At its core, DiffGraph features a sophisticated latent heterogeneous graph diffusion mechanism, implementing a novel forward and backward diffusion process for superior noise management. This methodology achieves simultaneous heterogeneous graph denoising and cross-type transition, while significantly simplifying graph generation through its latent-space diffusion capabilities. Through rigorous experimental validation on both public and industrial datasets, we demonstrate that DiffGraph consistently surpasses existing methods in link prediction and node classification tasks, establishing new benchmarks for robustness and efficiency in heterogeneous graph processing. The model implementation is publicly available at: https://github.com/HKUDS/DiffGraph.
Hunyuan-Large: An Open-Source MoE Model with 52 Billion Activated Parameters by Tencent
Nov 05, 2024



In this paper, we introduce Hunyuan-Large, which is currently the largest open-source Transformer-based mixture of experts model, with a total of 389 billion parameters and 52 billion activation parameters, capable of handling up to 256K tokens. We conduct a thorough evaluation of Hunyuan-Large's superior performance across various benchmarks including language understanding and generation, logical reasoning, mathematical problem-solving, coding, long-context, and aggregated tasks, where it outperforms LLama3.1-70B and exhibits comparable performance when compared to the significantly larger LLama3.1-405B model. Key practice of Hunyuan-Large include large-scale synthetic data that is orders larger than in previous literature, a mixed expert routing strategy, a key-value cache compression technique, and an expert-specific learning rate strategy. Additionally, we also investigate the scaling laws and learning rate schedule of mixture of experts models, providing valuable insights and guidances for future model development and optimization. The code and checkpoints of Hunyuan-Large are released to facilitate future innovations and applications. Codes: https://github.com/Tencent/Hunyuan-Large Models: https://huggingface.co/tencent/Tencent-Hunyuan-Large
RecDiff: Diffusion Model for Social Recommendation
Jun 01, 2024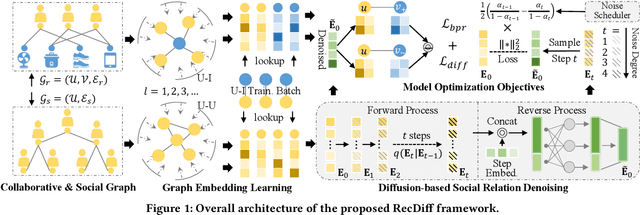



Social recommendation has emerged as a powerful approach to enhance personalized recommendations by leveraging the social connections among users, such as following and friend relations observed in online social platforms. The fundamental assumption of social recommendation is that socially-connected users exhibit homophily in their preference patterns. This means that users connected by social ties tend to have similar tastes in user-item activities, such as rating and purchasing. However, this assumption is not always valid due to the presence of irrelevant and false social ties, which can contaminate user embeddings and adversely affect recommendation accuracy. To address this challenge, we propose a novel diffusion-based social denoising framework for recommendation (RecDiff). Our approach utilizes a simple yet effective hidden-space diffusion paradigm to alleivate the noisy effect in the compressed and dense representation space. By performing multi-step noise diffusion and removal, RecDiff possesses a robust ability to identify and eliminate noise from the encoded user representations, even when the noise levels vary. The diffusion module is optimized in a downstream task-aware manner, thereby maximizing its ability to enhance the recommendation process. We conducted extensive experiments to evaluate the efficacy of our framework, and the results demonstrate its superiority in terms of recommendation accuracy, training efficiency, and denoising effectiveness. The source code for the model implementation is publicly available at: https://github.com/HKUDS/RecDiff.
LanguageBind: Extending Video-Language Pretraining to N-modality by Language-based Semantic Alignment
Oct 14, 2023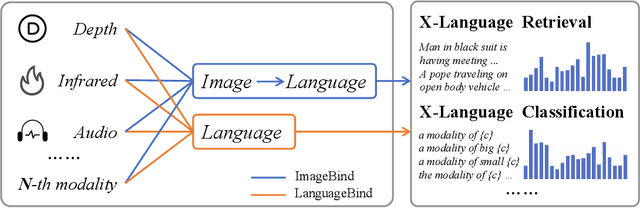
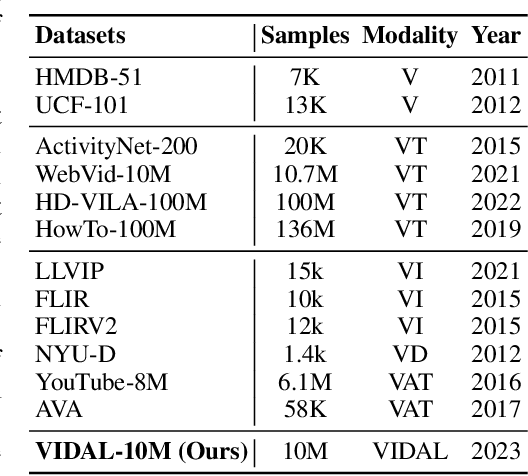
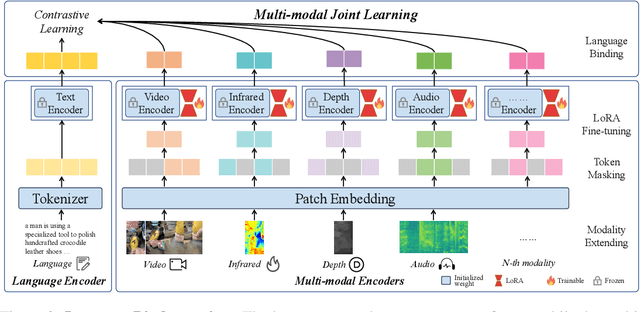
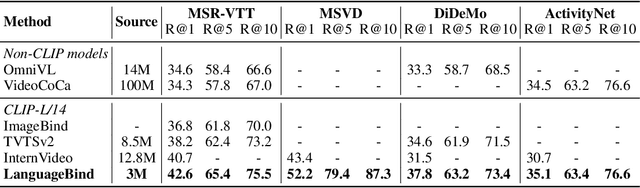
The video-language (VL) pretraining has achieved remarkable improvement in multiple downstream tasks. However, the current VL pretraining framework is hard to extend to multiple modalities (N modalities, N>=3) beyond vision and language. We thus propose LanguageBind, taking the language as the bind across different modalities because the language modality is well-explored and contains rich semantics. Specifically, we freeze the language encoder acquired by VL pretraining, then train encoders for other modalities with contrastive learning. As a result, all modalities are mapped to a shared feature space, implementing multi-modal semantic alignment. While LanguageBind ensures that we can extend VL modalities to N modalities, we also need a high-quality dataset with alignment data pairs centered on language. We thus propose VIDAL-10M with Video, Infrared, Depth, Audio and their corresponding Language, naming as VIDAL-10M. In our VIDAL-10M, all videos are from short video platforms with complete semantics rather than truncated segments from long videos, and all the video, depth, infrared, and audio modalities are aligned to their textual descriptions. After pretraining on VIDAL-10M, we outperform ImageBind by 5.8% R@1 on the MSR-VTT dataset with only 15% of the parameters in the zero-shot video-text retrieval task. Beyond this, our LanguageBind has greatly improved in the zero-shot video, audio, depth, and infrared understanding tasks. For instance, LanguageBind surpassing InterVideo by 1.9% on MSR-VTT, 8.8% on MSVD, 6.3% on DiDeMo, and 4.4% on ActivityNet. On the LLVIP and NYU-D datasets, LanguageBind outperforms ImageBind with 23.8% and 11.1% top-1 accuracy. Code address: https://github.com/PKU-YuanGroup/LanguageBind.