 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Modified Batch Intrinsic Plasticity Method for Pre-training the Random Coefficients of Extreme Learning Machines
Paper and Code
Mar 14, 2021
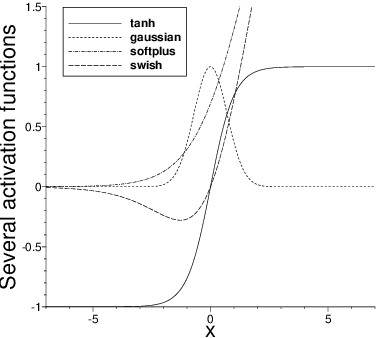
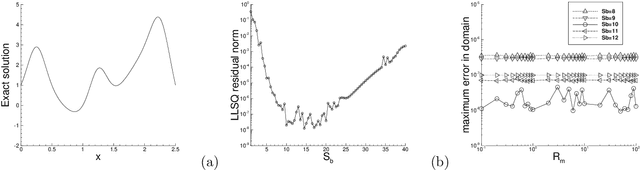
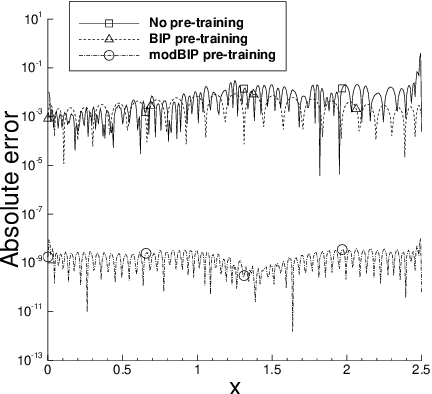
In extreme learning machines (ELM) the hidden-layer coefficients are randomly set and fixed, while the output-layer coefficients of the neural network are computed by a least squares method. The randomly-assigned coefficients in ELM are known to influence its performance and accuracy significantly. In this paper we present a modified batch intrinsic plasticity (modBIP) method for pre-training the random coefficients in the ELM neural networks. The current method is devised based on the same principle as the batch intrinsic plasticity (BIP) method, namely, by enhancing the information transmission in every node of the neural network. It differs from BIP in two prominent aspects. First, modBIP does not involve the activation function in its algorithm, and it can be applied with any activation function in the neural network. In contrast, BIP employs the inverse of the activation function in its construction, and requires the activation function to be invertible (or monotonic). The modBIP method can work with the often-used non-monotonic activation functions (e.g. Gaussian, swish, Gaussian error linear unit, and radial-basis type functions), with which BIP breaks down. Second, modBIP generates target samples on random intervals with a minimum size, which leads to highly accurate computation results when combined with ELM. The combined ELM/modBIP method is markedly more accurate than ELM/BIP in numerical simulations. Ample numerical experiments are presented with shallow and deep neural networks for function approximation and boundary/initial value problems with partial differential equations. They demonstrate that the combined ELM/modBIP method produces highly accurate simulation results, and that its accuracy is insensitive to the random-coefficient initializations in the neural network. This is in sharp contrast with the ELM results without pre-training of the random coefficients.