 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Novel Method for Enforcing Exactly Dirichlet, Neumann and Robin Conditions on Curved Domain Boundaries for Physics Informed Machine Learning
Mar 23, 2026We present a systematic method for exactly enforcing Dirichlet, Neumann, and Robin type conditions on general quadrilateral domains with arbitrary curved boundaries. Our method is built upon exact mappings between general quadrilateral domains and the standard domain, and employs a combination of TFC (theory of functional connections) constrained expressions and transfinite interpolations. When Neumann or Robin boundaries are present, especially when two Neumann (or Robin) boundaries meet at a vertex, it is critical to enforce exactly the induced compatibility constraints at the intersection, in order to enforce exactly the imposed conditions on the joining boundaries. We analyze in detail and present constructions for handling the imposed boundary conditions and the induced compatibility constraints for two types of situations: (i) when Neumann (or Robin) boundary only intersects with Dirichlet boundaries, and (ii) when two Neumann (or Robin) boundaries intersect with each other. We describe a four-step procedure to systematically formulate the general form of functions that exactly satisfy the imposed Dirichlet, Neumann, or Robin conditions on general quadrilateral domains. The method developed herein has been implemented together with the extreme learning machine (ELM) technique we have developed recently for scientific machine learning. Ample numerical experiments are presented with several linear/nonlinear stationary/dynamic problems on a variety of two-dimensional domains with complex boundary geometries. Simulation results demonstrate that the proposed method has enforced the Dirichlet, Neumann, and Robin conditions on curved domain boundaries exactly, with the numerical boundary-condition errors at the machine accuracy.
Error Analysis and Numerical Algorithm for PDE Approximation with Hidden-Layer Concatenated Physics Informed Neural Networks
Jun 10, 2024We present the hidden-layer concatenated physics informed neural network (HLConcPINN) method, which combines hidden-layer concatenated feed-forward neural networks, a modified block time marching strategy, and a physics informed approach for approximating partial differential equations (PDEs). We analyze the convergence properties and establish the error bounds of this method for two types of PDEs: parabolic (exemplified by the heat and Burgers' equations) and hyperbolic (exemplified by the wave and nonlinear Klein-Gordon equations). We show that its approximation error of the solution can be effectively controlled by the training loss for dynamic simulations with long time horizons. The HLConcPINN method in principle allows an arbitrary number of hidden layers not smaller than two and any of the commonly-used smooth activation functions for the hidden layers beyond the first two, with theoretical guarantees. This generalizes several recent neural-network techniques, which have theoretical guarantees but are confined to two hidden layers in the network architecture and the $\tanh$ activation function. Our theoretical analyses subsequently inform the formulation of appropriate training loss functions for these PDEs, leading to physics informed neural network (PINN) type computational algorithms that differ from the standard PINN formulation. Ample numerical experiments are presented based on the proposed algorithm to validate the effectiveness of this method and confirm aspects of the theoretical analyses.
An Extreme Learning Machine-Based Method for Computational PDEs in Higher Dimensions
Sep 13, 2023

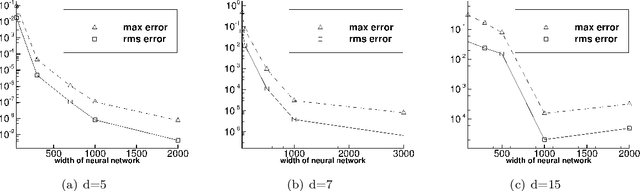
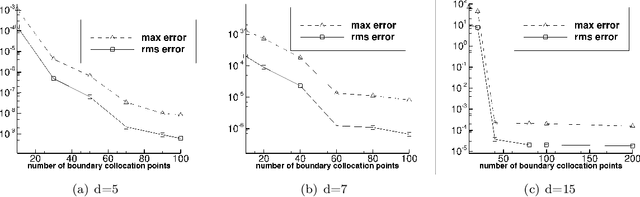
We present two effective methods for solving high-dimensional partial differential equations (PDE) based on randomized neural networks. Motivated by the universal approximation property of this type of networks, both methods extend the extreme learning machine (ELM) approach from low to high dimensions. With the first method the unknown solution field in $d$ dimensions is represented by a randomized feed-forward neural network, in which the hidden-layer parameters are randomly assigned and fixed while the output-layer parameters are trained. The PDE and the boundary/initial conditions, as well as the continuity conditions (for the local variant of the method), are enforced on a set of random interior/boundary collocation points. The resultant linear or nonlinear algebraic system, through its least squares solution, provides the trained values for the network parameters. With the second method the high-dimensional PDE problem is reformulated through a constrained expression based on an Approximate variant of the Theory of Functional Connections (A-TFC), which avoids the exponential growth in the number of terms of TFC as the dimension increases. The free field function in the A-TFC constrained expression is represented by a randomized neural network and is trained by a procedure analogous to the first method. We present ample numerical simulations for a number of high-dimensional linear/nonlinear stationary/dynamic PDEs to demonstrate their performance. These methods can produce accurate solutions to high-dimensional PDEs, in particular with their errors reaching levels not far from the machine accuracy for relatively lower dimensions. Compared with the physics-informed neural network (PINN) method, the current method is both cost-effective and more accurate for high-dimensional PDEs.
Error Analysis of Physics-Informed Neural Networks for Approximating Dynamic PDEs of Second Order in Time
Mar 22, 2023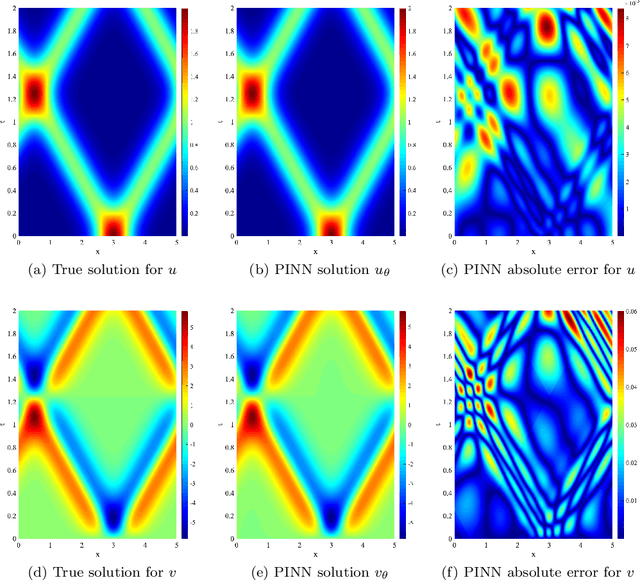
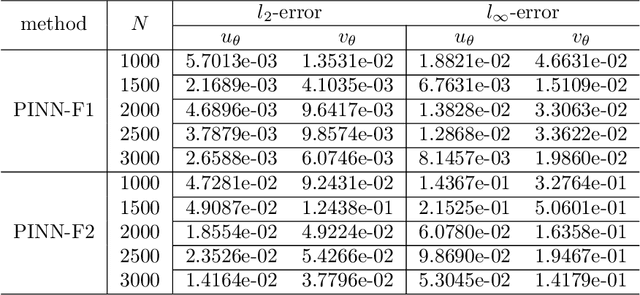
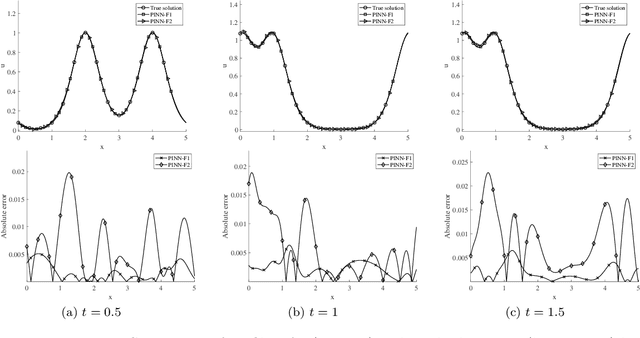
We consider the approximation of a class of dynamic partial differential equations (PDE) of second order in time by the physics-informed neural network (PINN) approach, and provide an error analysis of PINN for the wave equation, the Sine-Gordon equation and the linear elastodynamic equation. Our analyses show that, with feed-forward neural networks having two hidden layers and the $\tanh$ activation function, the PINN approximation errors for the solution field, its time derivative and its gradient field can be effectively bounded by the training loss and the number of training data points (quadrature points). Our analyses further suggest new forms for the training loss function, which contain certain residuals that are crucial to the error estimate but would be absent from the canonical PINN loss formulation. Adopting these new forms for the loss function leads to a variant PINN algorithm. We present ample numerical experiments with the new PINN algorithm for the wave equation, the Sine-Gordon equation and the linear elastodynamic equation, which show that the method can capture the solution well.
A Method for Computing Inverse Parametric PDE Problems with Random-Weight Neural Networks
Oct 09, 2022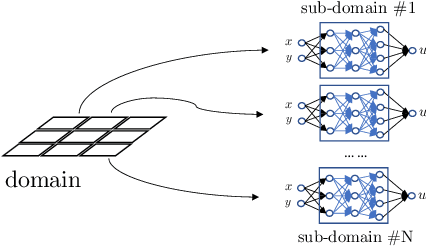
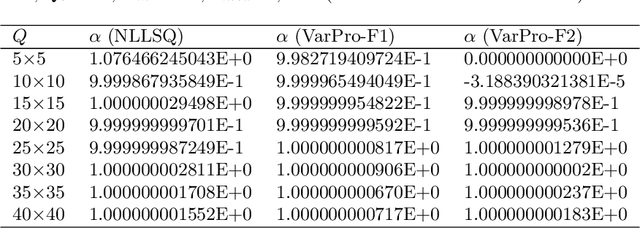
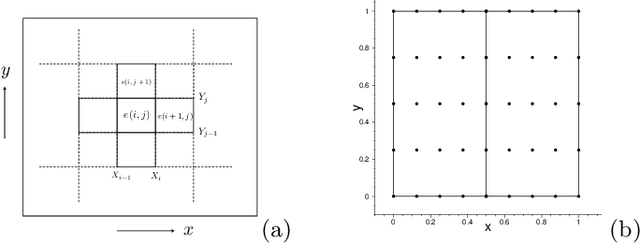
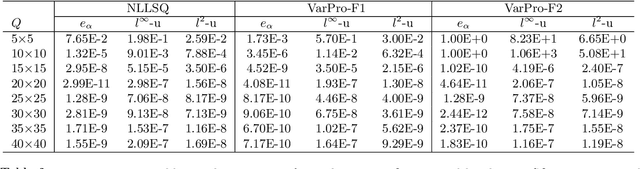
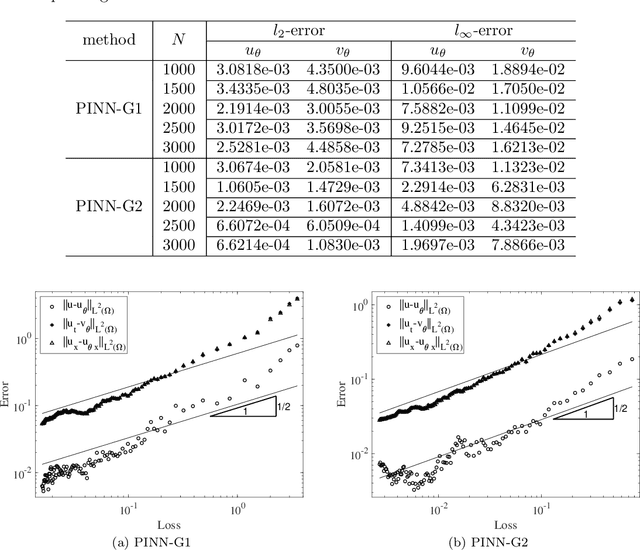
We present a method for computing the inverse parameters and the solution field to inverse parametric PDEs based on randomized neural networks. This extends the local extreme learning machine technique originally developed for forward PDEs to inverse problems. We develop three algorithms for training the neural network to solve the inverse PDE problem. The first algorithm (NLLSQ) determines the inverse parameters and the trainable network parameters all together by the nonlinear least squares method with perturbations (NLLSQ-perturb). The second algorithm (VarPro-F1) eliminates the inverse parameters from the overall problem by variable projection to attain a reduced problem about the trainable network parameters only. It solves the reduced problem first by the NLLSQ-perturb algorithm for the trainable network parameters, and then computes the inverse parameters by the linear least squares method. The third algorithm (VarPro-F2) eliminates the trainable network parameters from the overall problem by variable projection to attain a reduced problem about the inverse parameters only. It solves the reduced problem for the inverse parameters first, and then computes the trainable network parameters afterwards. VarPro-F1 and VarPro-F2 are reciprocal to each other in a sense. The presented method produces accurate results for inverse PDE problems, as shown by the numerical examples herein. For noise-free data, the errors for the inverse parameters and the solution field decrease exponentially as the number of collocation points or the number of trainable network parameters increases, and can reach a level close to the machine accuracy. For noisy data, the accuracy degrades compared with the case of noise-free data, but the method remains quite accurate. The presented method has been compared with the physics-informed neural network method.
Numerical Computation of Partial Differential Equations by Hidden-Layer Concatenated Extreme Learning Machine
Apr 24, 2022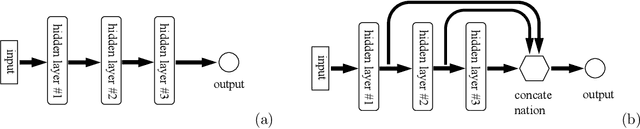
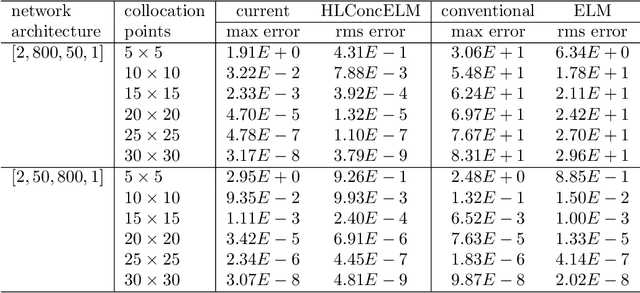
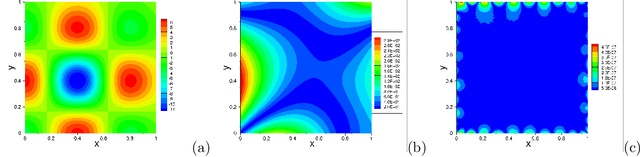
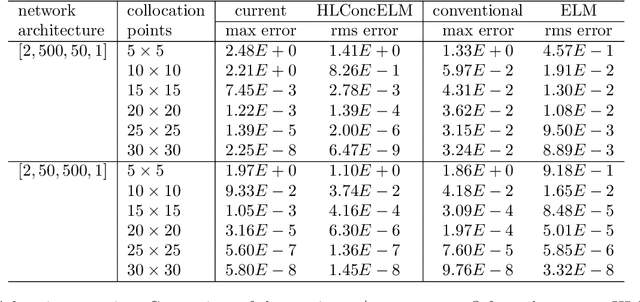
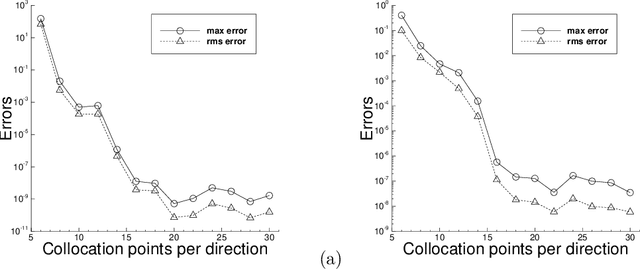
The extreme learning machine (ELM) method can yield highly accurate solutions to linear/nonlinear partial differential equations (PDEs), but requires the last hidden layer of the neural network to be wide to achieve a high accuracy. If the last hidden layer is narrow, the accuracy of the existing ELM method will be poor, irrespective of the rest of the network configuration. In this paper we present a modified ELM method, termed HLConcELM (hidden-layer concatenated ELM), to overcome the above drawback of the conventional ELM method. The HLConcELM method can produce highly accurate solutions to linear/nonlinear PDEs when the last hidden layer of the network is narrow and when it is wide. The new method is based on a type of modified feedforward neural networks (FNN), termed HLConcFNN (hidden-layer concatenated FNN), which incorporates a logical concatenation of the hidden layers in the network and exposes all the hidden nodes to the output-layer nodes. We show that HLConcFNNs have the remarkable property that, given a network architecture, when additional hidden layers are appended to the network or when extra nodes are added to the existing hidden layers, the approximation capacity of the HLConcFNN associated with the new architecture is guaranteed to be not smaller than that of the original network architecture. We present ample benchmark tests with linear/nonlinear PDEs to demonstrate the computational accuracy and performance of the HLConcELM method and the superiority of this method to the conventional ELM from previous works.
Numerical Approximation of Partial Differential Equations by a Variable Projection Method with Artificial Neural Networks
Jan 24, 2022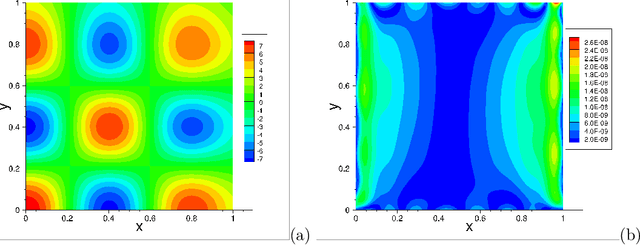

We present a method for solving linear and nonlinear PDEs based on the variable projection (VarPro) framework and artificial neural networks (ANN). For linear PDEs, enforcing the boundary/initial value problem on the collocation points leads to a separable nonlinear least squares problem about the network coefficients. We reformulate this problem by the VarPro approach to eliminate the linear output-layer coefficients, leading to a reduced problem about the hidden-layer coefficients only. The reduced problem is solved first by the nonlinear least squares method to determine the hidden-layer coefficients, and then the output-layer coefficients are computed by the linear least squares method. For nonlinear PDEs, enforcing the boundary/initial value problem on the collocation points leads to a nonlinear least squares problem that is not separable, which precludes the VarPro strategy for such problems. To enable the VarPro approach for nonlinear PDEs, we first linearize the problem with a Newton iteration, using a particular form of linearization. The linearized system is solved by the VarPro framework together with ANNs. Upon convergence of the Newton iteration, the network coefficients provide the representation of the solution field to the original nonlinear problem. We present ample numerical examples with linear and nonlinear PDEs to demonstrate the performance of the method herein. For smooth field solutions, the errors of the current method decrease exponentially as the number of collocation points or the number of output-layer coefficients increases. We compare the current method with the ELM method from a previous work. Under identical conditions and network configurations, the current method exhibits an accuracy significantly superior to the ELM method.
On Computing the Hyperparameter of Extreme Learning Machines: Algorithm and Application to Computational PDEs, and Comparison with Classical and High-Order Finite Elements
Oct 27, 2021
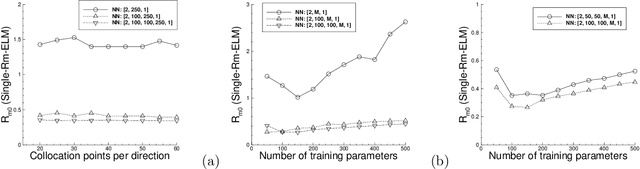
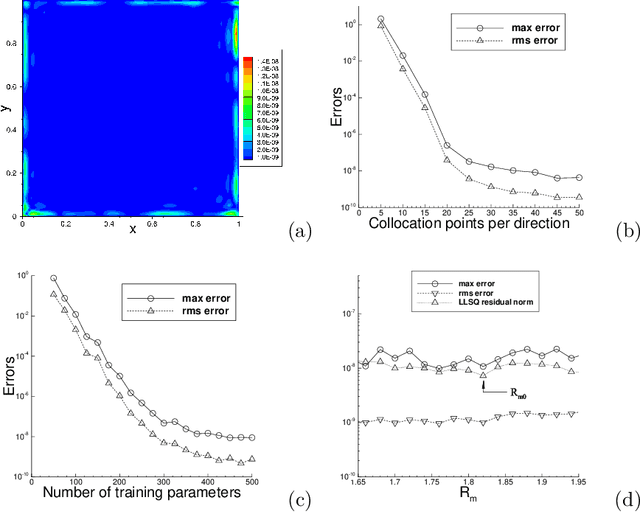
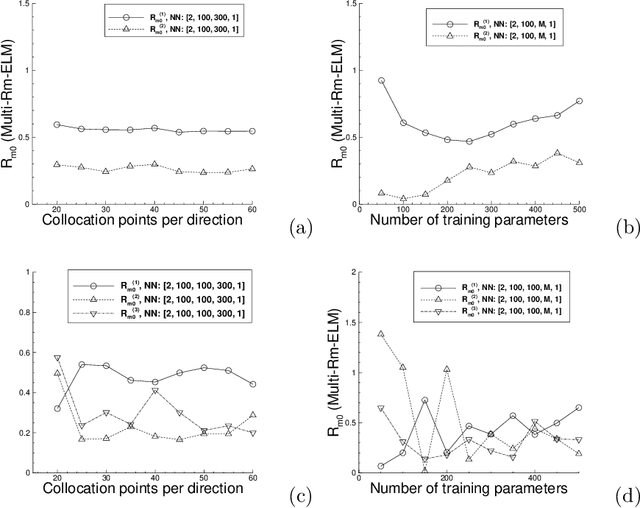
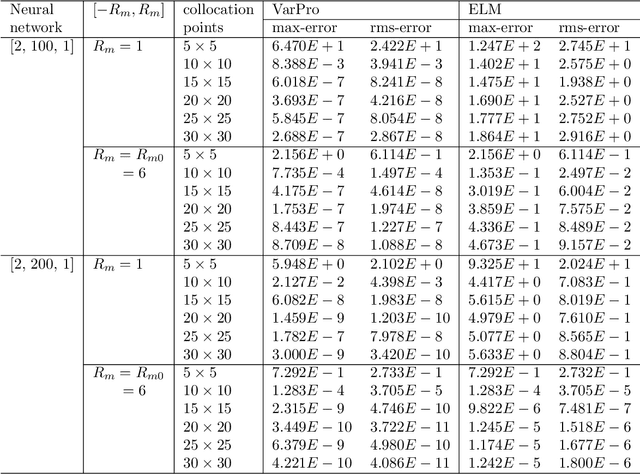
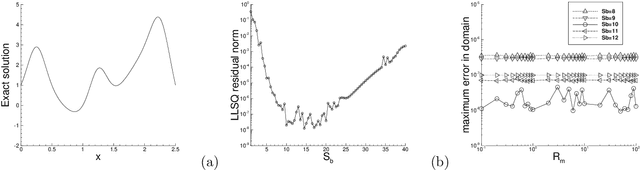
We consider the use of extreme learning machines (ELM) for computational partial differential equations (PDE). In ELM the hidden-layer coefficients in the neural network are assigned to random values generated on $[-R_m,R_m]$ and fixed, where $R_m$ is a user-provided constant, and the output-layer coefficients are trained by a linear or nonlinear least squares computation. We present a method for computing the optimal value of $R_m$ based on the differential evolution algorithm. The presented method enables us to illuminate the characteristics of the optimal $R_m$ for two types of ELM configurations: (i) Single-Rm-ELM, in which a single $R_m$ is used for generating the random coefficients in all the hidden layers, and (ii) Multi-Rm-ELM, in which multiple $R_m$ constants are involved with each used for generating the random coefficients of a different hidden layer. We adopt the optimal $R_m$ from this method and also incorporate other improvements into the ELM implementation. In particular, here we compute all the differential operators involving the output fields of the last hidden layer by a forward-mode auto-differentiation, as opposed to the reverse-mode auto-differentiation in a previous work. These improvements significantly reduce the network training time and enhance the ELM performance. We systematically compare the computational performance of the current improved ELM with that of the finite element method (FEM), both the classical second-order FEM and the high-order FEM with Lagrange elements of higher degrees, for solving a number of linear and nonlinear PDEs. It is shown that the current improved ELM far outperforms the classical FEM. Its computational performance is comparable to that of the high-order FEM for smaller problem sizes, and for larger problem sizes the ELM markedly outperforms the high-order FEM.
A Modified Batch Intrinsic Plasticity Method for Pre-training the Random Coefficients of Extreme Learning Machines
Mar 14, 2021
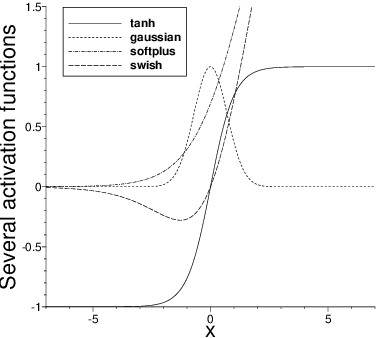
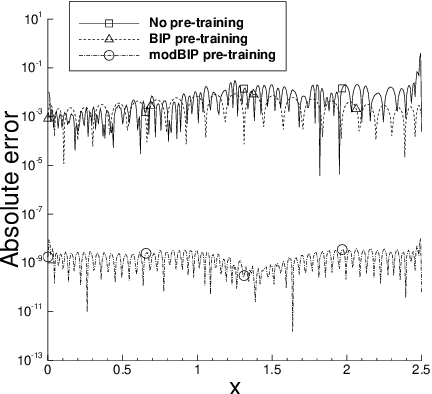
In extreme learning machines (ELM) the hidden-layer coefficients are randomly set and fixed, while the output-layer coefficients of the neural network are computed by a least squares method. The randomly-assigned coefficients in ELM are known to influence its performance and accuracy significantly. In this paper we present a modified batch intrinsic plasticity (modBIP) method for pre-training the random coefficients in the ELM neural networks. The current method is devised based on the same principle as the batch intrinsic plasticity (BIP) method, namely, by enhancing the information transmission in every node of the neural network. It differs from BIP in two prominent aspects. First, modBIP does not involve the activation function in its algorithm, and it can be applied with any activation function in the neural network. In contrast, BIP employs the inverse of the activation function in its construction, and requires the activation function to be invertible (or monotonic). The modBIP method can work with the often-used non-monotonic activation functions (e.g. Gaussian, swish, Gaussian error linear unit, and radial-basis type functions), with which BIP breaks down. Second, modBIP generates target samples on random intervals with a minimum size, which leads to highly accurate computation results when combined with ELM. The combined ELM/modBIP method is markedly more accurate than ELM/BIP in numerical simulations. Ample numerical experiments are presented with shallow and deep neural networks for function approximation and boundary/initial value problems with partial differential equations. They demonstrate that the combined ELM/modBIP method produces highly accurate simulation results, and that its accuracy is insensitive to the random-coefficient initializations in the neural network. This is in sharp contrast with the ELM results without pre-training of the random coefficients.
Local Extreme Learning Machines and Domain Decomposition for Solving Linear and Nonlinear Partial Differential Equations
Dec 04, 2020

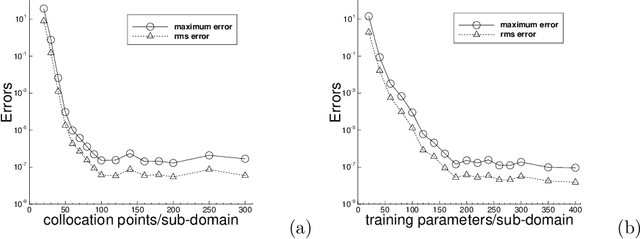
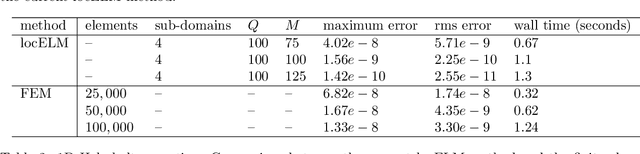
We present a neural network-based method for solving linear and nonlinear partial differential equations, by combining the ideas of extreme learning machines (ELM), domain decomposition and local neural networks. The field solution on each sub-domain is represented by a local feed-forward neural network, and $C^k$ continuity is imposed on the sub-domain boundaries. Each local neural network consists of a small number of hidden layers, while its last hidden layer can be wide. The weight/bias coefficients in all hidden layers of the local neural networks are pre-set to random values and are fixed, and only the weight coefficients in the output layers are training parameters. The overall neural network is trained by a linear or nonlinear least squares computation, not by the back-propagation type algorithms. We introduce a block time-marching scheme together with the presented method for long-time dynamic simulations. The current method exhibits a clear sense of convergence with respect to the degrees of freedom in the neural network. Its numerical errors typically decrease exponentially or nearly exponentially as the number of degrees of freedom increases. Extensive numerical experiments have been performed to demonstrate the computational performance of the presented method. We compare the current method with the deep Galerkin method (DGM) and the physics-informed neural network (PINN) in terms of the accuracy and computational cost. The current method exhibits a clear superiority, with its numerical errors and network training time considerably smaller (typically by orders of magnitude) than those of DGM and PINN. We also compare the current method with the classical finite element method (FEM). The computational performance of the current method is on par with, and oftentimes exceeds, the FEM performance.