 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeE-4DGS: High-Fidelity Dynamic Reconstruction from the Multi-view Event Cameras
Aug 13, 2025Novel view synthesis and 4D reconstruction techniques predominantly rely on RGB cameras, thereby inheriting inherent limitations such as the dependence on adequate lighting, susceptibility to motion blur, and a limited dynamic range. Event cameras, offering advantages of low power, high temporal resolution and high dynamic range, have brought a new perspective to addressing the scene reconstruction challenges in high-speed motion and low-light scenes. To this end, we propose E-4DGS, the first event-driven dynamic Gaussian Splatting approach, for novel view synthesis from multi-view event streams with fast-moving cameras. Specifically, we introduce an event-based initialization scheme to ensure stable training and propose event-adaptive slicing splatting for time-aware reconstruction. Additionally, we employ intensity importance pruning to eliminate floating artifacts and enhance 3D consistency, while incorporating an adaptive contrast threshold for more precise optimization. We design a synthetic multi-view camera setup with six moving event cameras surrounding the object in a 360-degree configuration and provide a benchmark multi-view event stream dataset that captures challenging motion scenarios. Our approach outperforms both event-only and event-RGB fusion baselines and paves the way for the exploration of multi-view event-based reconstruction as a novel approach for rapid scene capture.
VideoGen-of-Thought: Step-by-step generating multi-shot video with minimal manual intervention
Mar 20, 2025Current video generation models excel at short clips but fail to produce cohesive multi-shot narratives due to disjointed visual dynamics and fractured storylines. Existing solutions either rely on extensive manual scripting/editing or prioritize single-shot fidelity over cross-scene continuity, limiting their practicality for movie-like content. We introduce VideoGen-of-Thought (VGoT), a step-by-step framework that automates multi-shot video synthesis from a single sentence by systematically addressing three core challenges: (1) Narrative Fragmentation: Existing methods lack structured storytelling. We propose dynamic storyline modeling, which first converts the user prompt into concise shot descriptions, then elaborates them into detailed, cinematic specifications across five domains (character dynamics, background continuity, relationship evolution, camera movements, HDR lighting), ensuring logical narrative progression with self-validation. (2) Visual Inconsistency: Existing approaches struggle with maintaining visual consistency across shots. Our identity-aware cross-shot propagation generates identity-preserving portrait (IPP) tokens that maintain character fidelity while allowing trait variations (expressions, aging) dictated by the storyline. (3) Transition Artifacts: Abrupt shot changes disrupt immersion. Our adjacent latent transition mechanisms implement boundary-aware reset strategies that process adjacent shots' features at transition points, enabling seamless visual flow while preserving narrative continuity. VGoT generates multi-shot videos that outperform state-of-the-art baselines by 20.4% in within-shot face consistency and 17.4% in style consistency, while achieving over 100% better cross-shot consistency and 10x fewer manual adjustments than alternatives.
SwapAnyone: Consistent and Realistic Video Synthesis for Swapping Any Person into Any Video
Mar 12, 2025
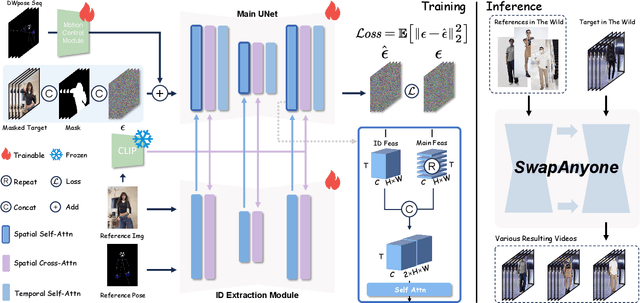
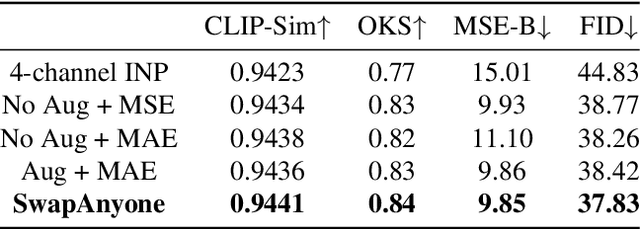

Video body-swapping aims to replace the body in an existing video with a new body from arbitrary sources, which has garnered more attention in recent years. Existing methods treat video body-swapping as a composite of multiple tasks instead of an independent task and typically rely on various models to achieve video body-swapping sequentially. However, these methods fail to achieve end-to-end optimization for the video body-swapping which causes issues such as variations in luminance among frames, disorganized occlusion relationships, and the noticeable separation between bodies and background. In this work, we define video body-swapping as an independent task and propose three critical consistencies: identity consistency, motion consistency, and environment consistency. We introduce an end-to-end model named SwapAnyone, treating video body-swapping as a video inpainting task with reference fidelity and motion control. To improve the ability to maintain environmental harmony, particularly luminance harmony in the resulting video, we introduce a novel EnvHarmony strategy for training our model progressively. Additionally, we provide a dataset named HumanAction-32K covering various videos about human actions. Extensive experiments demonstrate that our method achieves State-Of-The-Art (SOTA) performance among open-source methods while approaching or surpassing closed-source models across multiple dimensions. All code, model weights, and the HumanAction-32K dataset will be open-sourced at https://github.com/PKU-YuanGroup/SwapAnyone.
Next Patch Prediction for Autoregressive Visual Generation
Dec 19, 2024Autoregressive models, built based on the Next Token Prediction (NTP) paradigm, show great potential in developing a unified framework that integrates both language and vision tasks. In this work, we rethink the NTP for autoregressive image generation and propose a novel Next Patch Prediction (NPP) paradigm. Our key idea is to group and aggregate image tokens into patch tokens containing high information density. With patch tokens as a shorter input sequence, the autoregressive model is trained to predict the next patch, thereby significantly reducing the computational cost. We further propose a multi-scale coarse-to-fine patch grouping strategy that exploits the natural hierarchical property of image data. Experiments on a diverse range of models (100M-1.4B parameters) demonstrate that the next patch prediction paradigm could reduce the training cost to around 0.6 times while improving image generation quality by up to 1.0 FID score on the ImageNet benchmark. We highlight that our method retains the original autoregressive model architecture without introducing additional trainable parameters or specifically designing a custom image tokenizer, thus ensuring flexibility and seamless adaptation to various autoregressive models for visual generation.
VideoGen-of-Thought: A Collaborative Framework for Multi-Shot Video Generation
Dec 03, 2024Current video generation models excel at generating short clips but still struggle with creating multi-shot, movie-like videos. Existing models trained on large-scale data on the back of rich computational resources are unsurprisingly inadequate for maintaining a logical storyline and visual consistency across multiple shots of a cohesive script since they are often trained with a single-shot objective. To this end, we propose VideoGen-of-Thought (VGoT), a collaborative and training-free architecture designed specifically for multi-shot video generation. VGoT is designed with three goals in mind as follows. Multi-Shot Video Generation: We divide the video generation process into a structured, modular sequence, including (1) Script Generation, which translates a curt story into detailed prompts for each shot; (2) Keyframe Generation, responsible for creating visually consistent keyframes faithful to character portrayals; and (3) Shot-Level Video Generation, which transforms information from scripts and keyframes into shots; (4) Smoothing Mechanism that ensures a consistent multi-shot output. Reasonable Narrative Design: Inspired by cinematic scriptwriting, our prompt generation approach spans five key domains, ensuring logical consistency, character development, and narrative flow across the entire video. Cross-Shot Consistency: We ensure temporal and identity consistency by leveraging identity-preserving (IP) embeddings across shots, which are automatically created from the narrative. Additionally, we incorporate a cross-shot smoothing mechanism, which integrates a reset boundary that effectively combines latent features from adjacent shots, resulting in smooth transitions and maintaining visual coherence throughout the video. Our experiments demonstrate that VGoT surpasses existing video generation methods in producing high-quality, coherent, multi-shot videos.
DreamDance: Animating Human Images by Enriching 3D Geometry Cues from 2D Poses
Nov 30, 2024In this work, we present DreamDance, a novel method for animating human images using only skeleton pose sequences as conditional inputs. Existing approaches struggle with generating coherent, high-quality content in an efficient and user-friendly manner. Concretely, baseline methods relying on only 2D pose guidance lack the cues of 3D information, leading to suboptimal results, while methods using 3D representation as guidance achieve higher quality but involve a cumbersome and time-intensive process. To address these limitations, DreamDance enriches 3D geometry cues from 2D poses by introducing an efficient diffusion model, enabling high-quality human image animation with various guidance. Our key insight is that human images naturally exhibit multiple levels of correlation, progressing from coarse skeleton poses to fine-grained geometry cues, and further from these geometry cues to explicit appearance details. Capturing such correlations could enrich the guidance signals, facilitating intra-frame coherency and inter-frame consistency. Specifically, we construct the TikTok-Dance5K dataset, comprising 5K high-quality dance videos with detailed frame annotations, including human pose, depth, and normal maps. Next, we introduce a Mutually Aligned Geometry Diffusion Model to generate fine-grained depth and normal maps for enriched guidance. Finally, a Cross-domain Controller incorporates multi-level guidance to animate human images effectively with a video diffusion model. Extensive experiments demonstrate that our method achieves state-of-the-art performance in animating human images.
Open-Sora Plan: Open-Source Large Video Generation Model
Nov 28, 2024



We introduce Open-Sora Plan, an open-source project that aims to contribute a large generation model for generating desired high-resolution videos with long durations based on various user inputs. Our project comprises multiple components for the entire video generation process, including a Wavelet-Flow Variational Autoencoder, a Joint Image-Video Skiparse Denoiser, and various condition controllers. Moreover, many assistant strategies for efficient training and inference are designed, and a multi-dimensional data curation pipeline is proposed for obtaining desired high-quality data. Benefiting from efficient thoughts, our Open-Sora Plan achieves impressive video generation results in both qualitative and quantitative evaluations. We hope our careful design and practical experience can inspire the video generation research community. All our codes and model weights are publicly available at \url{https://github.com/PKU-YuanGroup/Open-Sora-Plan}.
Cycle3D: High-quality and Consistent Image-to-3D Generation via Generation-Reconstruction Cycle
Jul 28, 2024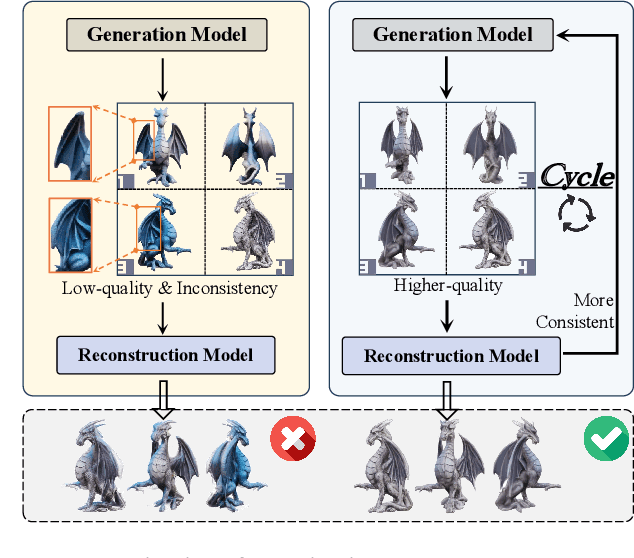
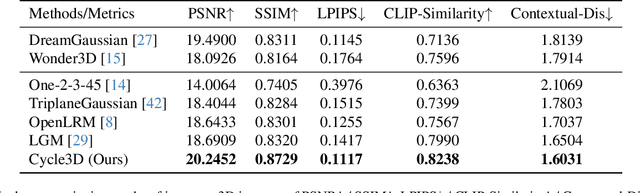
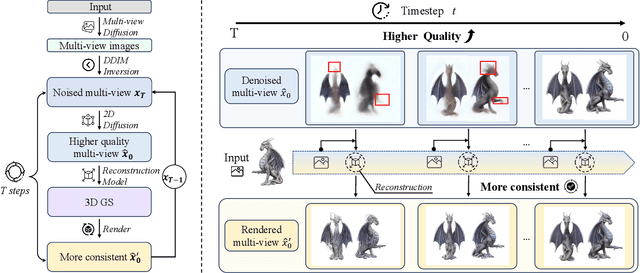
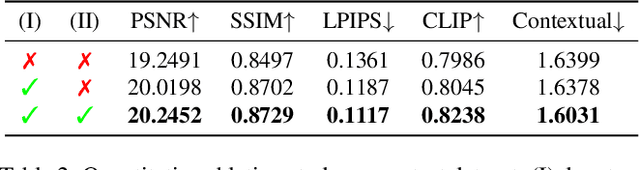
Recent 3D large reconstruction models typically employ a two-stage process, including first generate multi-view images by a multi-view diffusion model, and then utilize a feed-forward model to reconstruct images to 3D content.However, multi-view diffusion models often produce low-quality and inconsistent images, adversely affecting the quality of the final 3D reconstruction. To address this issue, we propose a unified 3D generation framework called Cycle3D, which cyclically utilizes a 2D diffusion-based generation module and a feed-forward 3D reconstruction module during the multi-step diffusion process. Concretely, 2D diffusion model is applied for generating high-quality texture, and the reconstruction model guarantees multi-view consistency.Moreover, 2D diffusion model can further control the generated content and inject reference-view information for unseen views, thereby enhancing the diversity and texture consistency of 3D generation during the denoising process. Extensive experiments demonstrate the superior ability of our method to create 3D content with high-quality and consistency compared with state-of-the-art baselines.
Envision3D: One Image to 3D with Anchor Views Interpolation
Mar 13, 2024



We present Envision3D, a novel method for efficiently generating high-quality 3D content from a single image. Recent methods that extract 3D content from multi-view images generated by diffusion models show great potential. However, it is still challenging for diffusion models to generate dense multi-view consistent images, which is crucial for the quality of 3D content extraction. To address this issue, we propose a novel cascade diffusion framework, which decomposes the challenging dense views generation task into two tractable stages, namely anchor views generation and anchor views interpolation. In the first stage, we train the image diffusion model to generate global consistent anchor views conditioning on image-normal pairs. Subsequently, leveraging our video diffusion model fine-tuned on consecutive multi-view images, we conduct interpolation on the previous anchor views to generate extra dense views. This framework yields dense, multi-view consistent images, providing comprehensive 3D information. To further enhance the overall generation quality, we introduce a coarse-to-fine sampling strategy for the reconstruction algorithm to robustly extract textured meshes from the generated dense images. Extensive experiments demonstrate that our method is capable of generating high-quality 3D content in terms of texture and geometry, surpassing previous image-to-3D baseline methods.
Repaint123: Fast and High-quality One Image to 3D Generation with Progressive Controllable 2D Repainting
Dec 27, 2023



Recent one image to 3D generation methods commonly adopt Score Distillation Sampling (SDS). Despite the impressive results, there are multiple deficiencies including multi-view inconsistency, over-saturated and over-smoothed textures, as well as the slow generation speed. To address these deficiencies, we present Repaint123 to alleviate multi-view bias as well as texture degradation and speed up the generation process. The core idea is to combine the powerful image generation capability of the 2D diffusion model and the texture alignment ability of the repainting strategy for generating high-quality multi-view images with consistency. We further propose visibility-aware adaptive repainting strength for overlap regions to enhance the generated image quality in the repainting process. The generated high-quality and multi-view consistent images enable the use of simple Mean Square Error (MSE) loss for fast 3D content generation. We conduct extensive experiments and show that our method has a superior ability to generate high-quality 3D content with multi-view consistency and fine textures in 2 minutes from scratch. Our project page is available at https://pku-yuangroup.github.io/repaint123/.