 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHow Do Optical Flow and Textual Prompts Collaborate to Assist in Audio-Visual Semantic Segmentation?
Jan 13, 2026Audio-visual semantic segmentation (AVSS) represents an extension of the audio-visual segmentation (AVS) task, necessitating a semantic understanding of audio-visual scenes beyond merely identifying sound-emitting objects at the visual pixel level. Contrary to a previous methodology, by decomposing the AVSS task into two discrete subtasks by initially providing a prompted segmentation mask to facilitate subsequent semantic analysis, our approach innovates on this foundational strategy. We introduce a novel collaborative framework, \textit{S}tepping \textit{S}tone \textit{P}lus (SSP), which integrates optical flow and textual prompts to assist the segmentation process. In scenarios where sound sources frequently coexist with moving objects, our pre-mask technique leverages optical flow to capture motion dynamics, providing essential temporal context for precise segmentation. To address the challenge posed by stationary sound-emitting objects, such as alarm clocks, SSP incorporates two specific textual prompts: one identifies the category of the sound-emitting object, and the other provides a broader description of the scene. Additionally, we implement a visual-textual alignment module (VTA) to facilitate cross-modal integration, delivering more coherent and contextually relevant semantic interpretations. Our training regimen involves a post-mask technique aimed at compelling the model to learn the diagram of the optical flow. Experimental results demonstrate that SSP outperforms existing AVS methods, delivering efficient and precise segmentation results.
VideoGen-of-Thought: Step-by-step generating multi-shot video with minimal manual intervention
Mar 20, 2025Current video generation models excel at short clips but fail to produce cohesive multi-shot narratives due to disjointed visual dynamics and fractured storylines. Existing solutions either rely on extensive manual scripting/editing or prioritize single-shot fidelity over cross-scene continuity, limiting their practicality for movie-like content. We introduce VideoGen-of-Thought (VGoT), a step-by-step framework that automates multi-shot video synthesis from a single sentence by systematically addressing three core challenges: (1) Narrative Fragmentation: Existing methods lack structured storytelling. We propose dynamic storyline modeling, which first converts the user prompt into concise shot descriptions, then elaborates them into detailed, cinematic specifications across five domains (character dynamics, background continuity, relationship evolution, camera movements, HDR lighting), ensuring logical narrative progression with self-validation. (2) Visual Inconsistency: Existing approaches struggle with maintaining visual consistency across shots. Our identity-aware cross-shot propagation generates identity-preserving portrait (IPP) tokens that maintain character fidelity while allowing trait variations (expressions, aging) dictated by the storyline. (3) Transition Artifacts: Abrupt shot changes disrupt immersion. Our adjacent latent transition mechanisms implement boundary-aware reset strategies that process adjacent shots' features at transition points, enabling seamless visual flow while preserving narrative continuity. VGoT generates multi-shot videos that outperform state-of-the-art baselines by 20.4% in within-shot face consistency and 17.4% in style consistency, while achieving over 100% better cross-shot consistency and 10x fewer manual adjustments than alternatives.
VideoGen-of-Thought: A Collaborative Framework for Multi-Shot Video Generation
Dec 03, 2024Current video generation models excel at generating short clips but still struggle with creating multi-shot, movie-like videos. Existing models trained on large-scale data on the back of rich computational resources are unsurprisingly inadequate for maintaining a logical storyline and visual consistency across multiple shots of a cohesive script since they are often trained with a single-shot objective. To this end, we propose VideoGen-of-Thought (VGoT), a collaborative and training-free architecture designed specifically for multi-shot video generation. VGoT is designed with three goals in mind as follows. Multi-Shot Video Generation: We divide the video generation process into a structured, modular sequence, including (1) Script Generation, which translates a curt story into detailed prompts for each shot; (2) Keyframe Generation, responsible for creating visually consistent keyframes faithful to character portrayals; and (3) Shot-Level Video Generation, which transforms information from scripts and keyframes into shots; (4) Smoothing Mechanism that ensures a consistent multi-shot output. Reasonable Narrative Design: Inspired by cinematic scriptwriting, our prompt generation approach spans five key domains, ensuring logical consistency, character development, and narrative flow across the entire video. Cross-Shot Consistency: We ensure temporal and identity consistency by leveraging identity-preserving (IP) embeddings across shots, which are automatically created from the narrative. Additionally, we incorporate a cross-shot smoothing mechanism, which integrates a reset boundary that effectively combines latent features from adjacent shots, resulting in smooth transitions and maintaining visual coherence throughout the video. Our experiments demonstrate that VGoT surpasses existing video generation methods in producing high-quality, coherent, multi-shot videos.
BitQ: Tailoring Block Floating Point Precision for Improved DNN Efficiency on Resource-Constrained Devices
Sep 25, 2024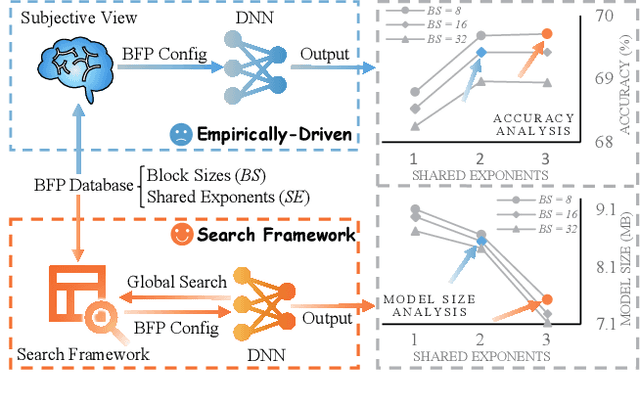
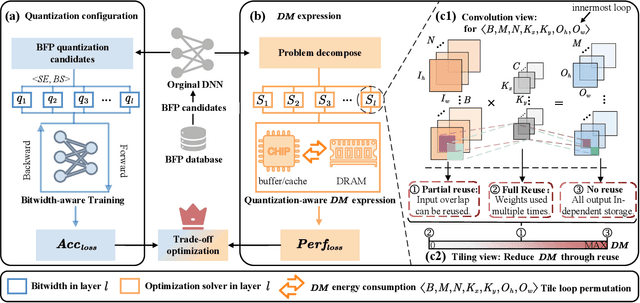

Deep neural networks (DNNs) are powerful for cognitive tasks such as image classification, object detection, and scene segmentation. One drawback however is the significant high computational complexity and memory consumption, which makes them unfeasible to run real-time on embedded platforms because of the limited hardware resources. Block floating point (BFP) quantization is one of the representative compression approaches for reducing the memory and computational burden owing to their capability to effectively capture the broad data distribution of DNN models. Unfortunately, prior works on BFP-based quantization empirically choose the block size and the precision that preserve accuracy. In this paper, we develop a BFP-based bitwidth-aware analytical modeling framework (called ``BitQ'') for the best BFP implementation of DNN inference on embedded platforms. We formulate and resolve an optimization problem to identify the optimal BFP block size and bitwidth distribution by the trade-off of both accuracy and performance loss. Experimental results show that compared with an equal bitwidth setting, the BFP DNNs with optimized bitwidth allocation provide efficient computation, preserving accuracy on famous benchmarks. The source code and data are available at https://github.com/Cheliosoops/BitQ.
ChronoMagic-Bench: A Benchmark for Metamorphic Evaluation of Text-to-Time-lapse Video Generation
Jun 26, 2024



We propose a novel text-to-video (T2V) generation benchmark, ChronoMagic-Bench, to evaluate the temporal and metamorphic capabilities of the T2V models (e.g. Sora and Lumiere) in time-lapse video generation. In contrast to existing benchmarks that focus on the visual quality and textual relevance of generated videos, ChronoMagic-Bench focuses on the model's ability to generate time-lapse videos with significant metamorphic amplitude and temporal coherence. The benchmark probes T2V models for their physics, biology, and chemistry capabilities, in a free-form text query. For these purposes, ChronoMagic-Bench introduces 1,649 prompts and real-world videos as references, categorized into four major types of time-lapse videos: biological, human-created, meteorological, and physical phenomena, which are further divided into 75 subcategories. This categorization comprehensively evaluates the model's capacity to handle diverse and complex transformations. To accurately align human preference with the benchmark, we introduce two new automatic metrics, MTScore and CHScore, to evaluate the videos' metamorphic attributes and temporal coherence. MTScore measures the metamorphic amplitude, reflecting the degree of change over time, while CHScore assesses the temporal coherence, ensuring the generated videos maintain logical progression and continuity. Based on the ChronoMagic-Bench, we conduct comprehensive manual evaluations of ten representative T2V models, revealing their strengths and weaknesses across different categories of prompts, and providing a thorough evaluation framework that addresses current gaps in video generation research. Moreover, we create a large-scale ChronoMagic-Pro dataset, containing 460k high-quality pairs of 720p time-lapse videos and detailed captions ensuring high physical pertinence and large metamorphic amplitude.
LSROM: Learning Self-Refined Organizing Map for Fast Imbalanced Streaming Data Clustering
Apr 14, 2024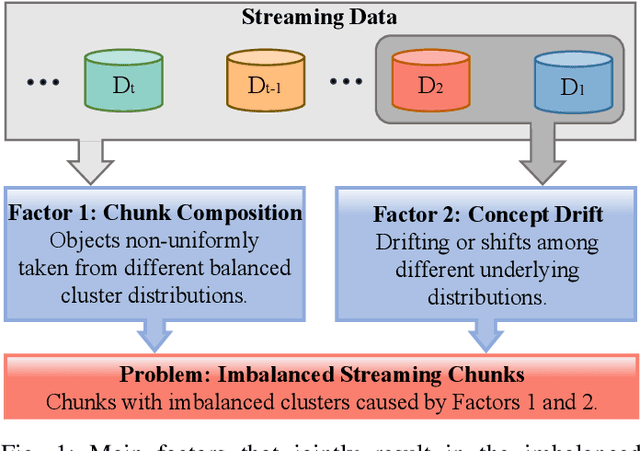
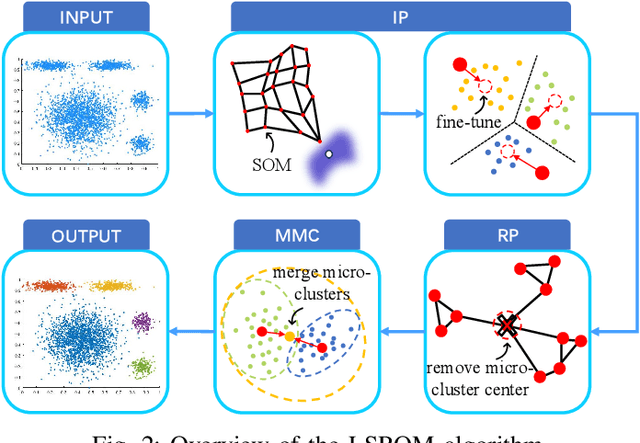

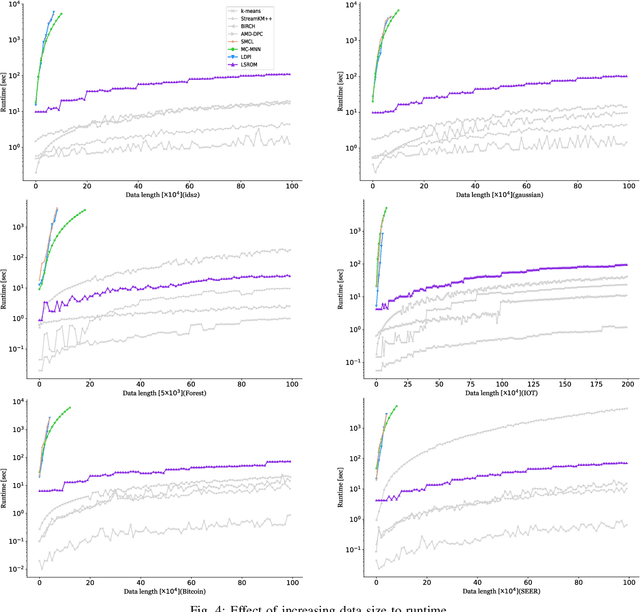
Streaming data clustering is a popular research topic in the fields of data mining and machine learning. Compared to static data, streaming data, which is usually analyzed in data chunks, is more susceptible to encountering the dynamic cluster imbalanced issue. That is, the imbalanced degree of clusters varies in different streaming data chunks, leading to corruption in either the accuracy or the efficiency of streaming data analysis based on existing clustering methods. Therefore, we propose an efficient approach called Learning Self-Refined Organizing Map (LSROM) to handle the imbalanced streaming data clustering problem, where we propose an advanced SOM for representing the global data distribution. The constructed SOM is first refined for guiding the partition of the dataset to form many micro-clusters to avoid the missing small clusters in imbalanced data. Then an efficient merging of the micro-clusters is conducted through quick retrieval based on the SOM, which can automatically yield a true number of imbalanced clusters. In comparison to existing imbalanced data clustering approaches, LSROM is with a lower time complexity $O(n\log n)$, while achieving very competitive clustering accuracy. Moreover, LSROM is interpretable and insensitive to hyper-parameters. Extensive experiments have verified its efficacy.
MagicTime: Time-lapse Video Generation Models as Metamorphic Simulators
Apr 07, 2024



Recent advances in Text-to-Video generation (T2V) have achieved remarkable success in synthesizing high-quality general videos from textual descriptions. A largely overlooked problem in T2V is that existing models have not adequately encoded physical knowledge of the real world, thus generated videos tend to have limited motion and poor variations. In this paper, we propose \textbf{MagicTime}, a metamorphic time-lapse video generation model, which learns real-world physics knowledge from time-lapse videos and implements metamorphic generation. First, we design a MagicAdapter scheme to decouple spatial and temporal training, encode more physical knowledge from metamorphic videos, and transform pre-trained T2V models to generate metamorphic videos. Second, we introduce a Dynamic Frames Extraction strategy to adapt to metamorphic time-lapse videos, which have a wider variation range and cover dramatic object metamorphic processes, thus embodying more physical knowledge than general videos. Finally, we introduce a Magic Text-Encoder to improve the understanding of metamorphic video prompts. Furthermore, we create a time-lapse video-text dataset called \textbf{ChronoMagic}, specifically curated to unlock the metamorphic video generation ability. Extensive experiments demonstrate the superiority and effectiveness of MagicTime for generating high-quality and dynamic metamorphic videos, suggesting time-lapse video generation is a promising path toward building metamorphic simulators of the physical world.