 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvent-Aided Sharp Radiance Field Reconstruction for Fast-Flying Drones
Feb 26, 2026Fast-flying aerial robots promise rapid inspection under limited battery constraints, with direct applications in infrastructure inspection, terrain exploration, and search and rescue. However, high speeds lead to severe motion blur in images and induce significant drift and noise in pose estimates, making dense 3D reconstruction with Neural Radiance Fields (NeRFs) particularly challenging due to their high sensitivity to such degradations. In this work, we present a unified framework that leverages asynchronous event streams alongside motion-blurred frames to reconstruct high-fidelity radiance fields from agile drone flights. By embedding event-image fusion into NeRF optimization and jointly refining event-based visual-inertial odometry priors using both event and frame modalities, our method recovers sharp radiance fields and accurate camera trajectories without ground-truth supervision. We validate our approach on both synthetic data and real-world sequences captured by a fast-flying drone. Despite highly dynamic drone flights, where RGB frames are severely degraded by motion blur and pose priors become unreliable, our method reconstructs high-fidelity radiance fields and preserves fine scene details, delivering a performance gain of over 50% on real-world data compared to state-of-the-art methods.
Retrieval Robust to Object Motion Blur
Apr 27, 2024
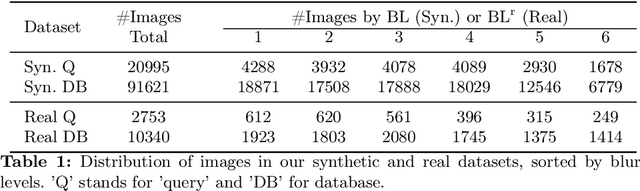

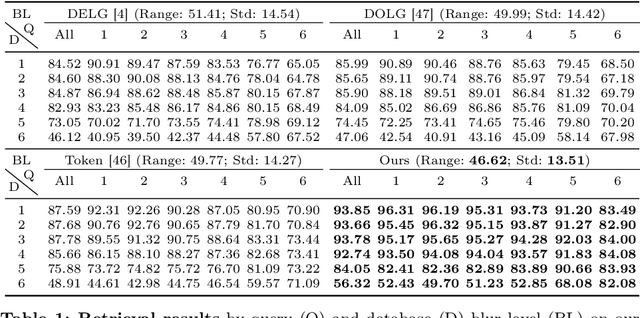
Moving objects are frequently seen in daily life and usually appear blurred in images due to their motion. While general object retrieval is a widely explored area in computer vision, it primarily focuses on sharp and static objects, and retrieval of motion-blurred objects in large image collections remains unexplored. We propose a method for object retrieval in images that are affected by motion blur. The proposed method learns a robust representation capable of matching blurred objects to their deblurred versions and vice versa. To evaluate our approach, we present the first large-scale datasets for blurred object retrieval, featuring images with objects exhibiting varying degrees of blur in various poses and scales. We conducted extensive experiments, showing that our method outperforms state-of-the-art retrieval methods on the new blur-retrieval datasets, which validates the effectiveness of the proposed approach.
LSROM: Learning Self-Refined Organizing Map for Fast Imbalanced Streaming Data Clustering
Apr 14, 2024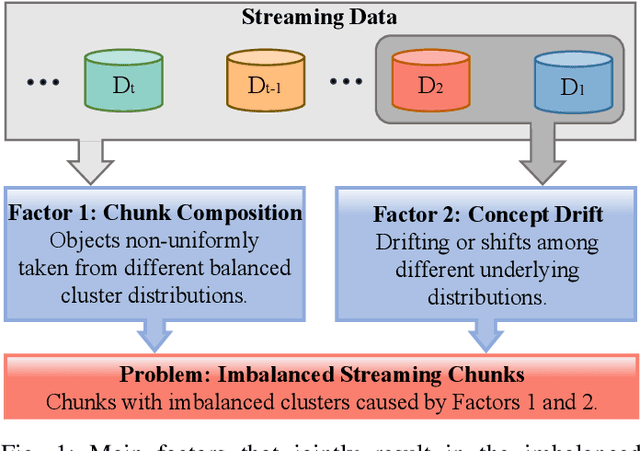
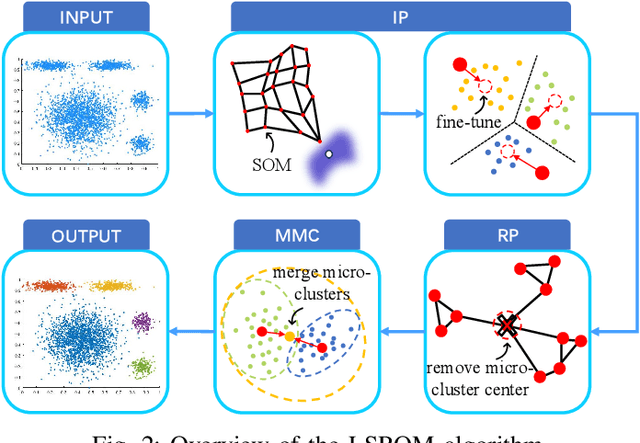

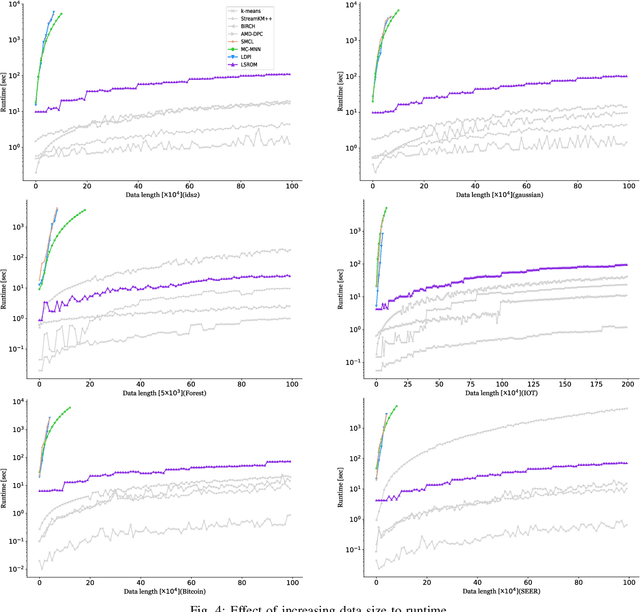
Streaming data clustering is a popular research topic in the fields of data mining and machine learning. Compared to static data, streaming data, which is usually analyzed in data chunks, is more susceptible to encountering the dynamic cluster imbalanced issue. That is, the imbalanced degree of clusters varies in different streaming data chunks, leading to corruption in either the accuracy or the efficiency of streaming data analysis based on existing clustering methods. Therefore, we propose an efficient approach called Learning Self-Refined Organizing Map (LSROM) to handle the imbalanced streaming data clustering problem, where we propose an advanced SOM for representing the global data distribution. The constructed SOM is first refined for guiding the partition of the dataset to form many micro-clusters to avoid the missing small clusters in imbalanced data. Then an efficient merging of the micro-clusters is conducted through quick retrieval based on the SOM, which can automatically yield a true number of imbalanced clusters. In comparison to existing imbalanced data clustering approaches, LSROM is with a lower time complexity $O(n\log n)$, while achieving very competitive clustering accuracy. Moreover, LSROM is interpretable and insensitive to hyper-parameters. Extensive experiments have verified its efficacy.
MARRS: Multimodal Reference Resolution System
Nov 03, 2023



Successfully handling context is essential for any dialog understanding task. This context maybe be conversational (relying on previous user queries or system responses), visual (relying on what the user sees, for example, on their screen), or background (based on signals such as a ringing alarm or playing music). In this work, we present an overview of MARRS, or Multimodal Reference Resolution System, an on-device framework within a Natural Language Understanding system, responsible for handling conversational, visual and background context. In particular, we present different machine learning models to enable handing contextual queries; specifically, one to enable reference resolution, and one to handle context via query rewriting. We also describe how these models complement each other to form a unified, coherent, lightweight system that can understand context while preserving user privacy.
Seeing Behind Dynamic Occlusions with Event Cameras
Aug 01, 2023
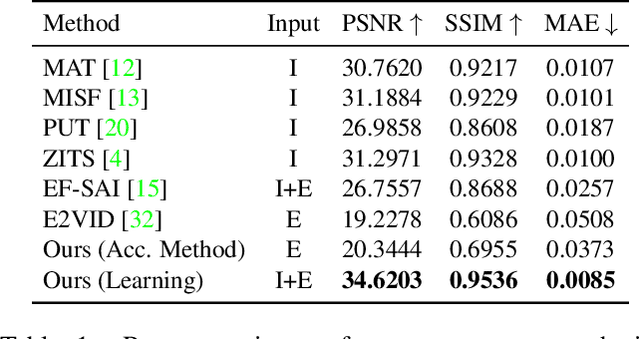
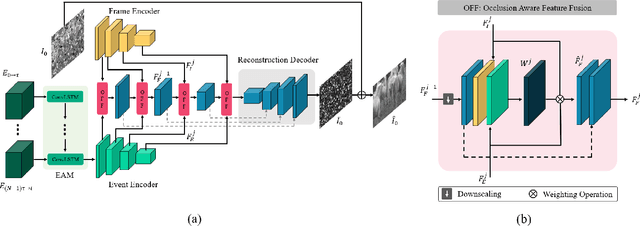
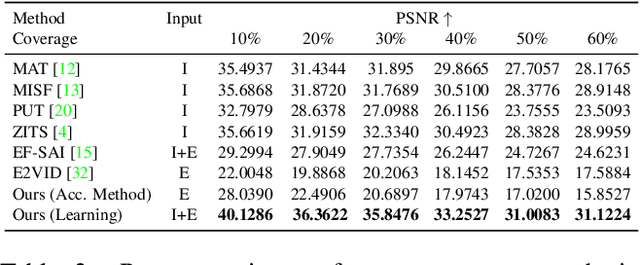
Unwanted camera occlusions, such as debris, dust, rain-drops, and snow, can severely degrade the performance of computer-vision systems. Dynamic occlusions are particularly challenging because of the continuously changing pattern. Existing occlusion-removal methods currently use synthetic aperture imaging or image inpainting. However, they face issues with dynamic occlusions as these require multiple viewpoints or user-generated masks to hallucinate the background intensity. We propose a novel approach to reconstruct the background from a single viewpoint in the presence of dynamic occlusions. Our solution relies for the first time on the combination of a traditional camera with an event camera. When an occlusion moves across a background image, it causes intensity changes that trigger events. These events provide additional information on the relative intensity changes between foreground and background at a high temporal resolution, enabling a truer reconstruction of the background content. We present the first large-scale dataset consisting of synchronized images and event sequences to evaluate our approach. We show that our method outperforms image inpainting methods by 3dB in terms of PSNR on our dataset.