 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReALM: Reference Resolution As Language Modeling
Mar 29, 2024
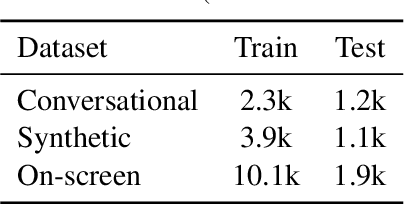
Reference resolution is an important problem, one that is essential to understand and successfully handle context of different kinds. This context includes both previous turns and context that pertains to non-conversational entities, such as entities on the user's screen or those running in the background. While LLMs have been shown to be extremely powerful for a variety of tasks, their use in reference resolution, particularly for non-conversational entities, remains underutilized. This paper demonstrates how LLMs can be used to create an extremely effective system to resolve references of various types, by showing how reference resolution can be converted into a language modeling problem, despite involving forms of entities like those on screen that are not traditionally conducive to being reduced to a text-only modality. We demonstrate large improvements over an existing system with similar functionality across different types of references, with our smallest model obtaining absolute gains of over 5% for on-screen references. We also benchmark against GPT-3.5 and GPT-4, with our smallest model achieving performance comparable to that of GPT-4, and our larger models substantially outperforming it.
MARRS: Multimodal Reference Resolution System
Nov 03, 2023



Successfully handling context is essential for any dialog understanding task. This context maybe be conversational (relying on previous user queries or system responses), visual (relying on what the user sees, for example, on their screen), or background (based on signals such as a ringing alarm or playing music). In this work, we present an overview of MARRS, or Multimodal Reference Resolution System, an on-device framework within a Natural Language Understanding system, responsible for handling conversational, visual and background context. In particular, we present different machine learning models to enable handing contextual queries; specifically, one to enable reference resolution, and one to handle context via query rewriting. We also describe how these models complement each other to form a unified, coherent, lightweight system that can understand context while preserving user privacy.
Hyperparameter Tuning for Deep Reinforcement Learning Applications
Jan 26, 2022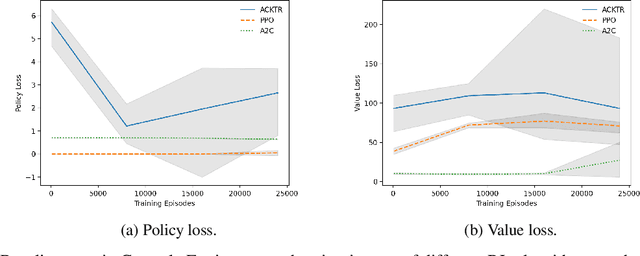
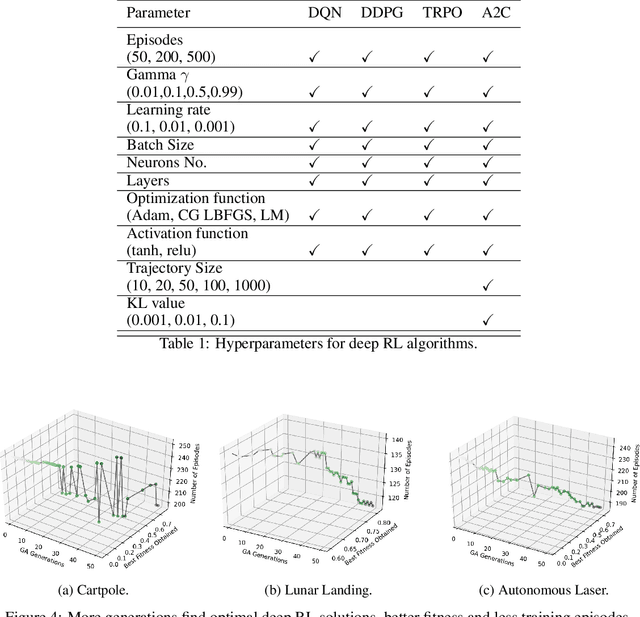
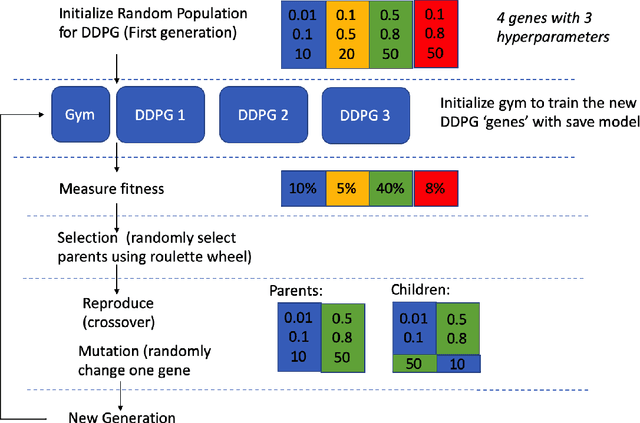

Reinforcement learning (RL) applications, where an agent can simply learn optimal behaviors by interacting with the environment, are quickly gaining tremendous success in a wide variety of applications from controlling simple pendulums to complex data centers. However, setting the right hyperparameters can have a huge impact on the deployed solution performance and reliability in the inference models, produced via RL, used for decision-making. Hyperparameter search itself is a laborious process that requires many iterations and computationally expensive to find the best settings that produce the best neural network architectures. In comparison to other neural network architectures, deep RL has not witnessed much hyperparameter tuning, due to its algorithm complexity and simulation platforms needed. In this paper, we propose a distributed variable-length genetic algorithm framework to systematically tune hyperparameters for various RL applications, improving training time and robustness of the architecture, via evolution. We demonstrate the scalability of our approach on many RL problems (from simple gyms to complex applications) and compared with Bayesian approach. Our results show that with more generations, optimal solutions that require fewer training episodes and are computationally cheap while being more robust for deployment. Our results are imperative to advance deep reinforcement learning controllers for real-world problems.