 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOFCnetLLM: Large Language Model for Network Monitoring and Alertness
Jul 30, 2025The rapid evolution of network infrastructure is bringing new challenges and opportunities for efficient network management, optimization, and security. With very large monitoring databases becoming expensive to explore, the use of AI and Generative AI can help reduce costs of managing these datasets. This paper explores the use of Large Language Models (LLMs) to revolutionize network monitoring management by addressing the limitations of query finding and pattern analysis. We leverage LLMs to enhance anomaly detection, automate root-cause analysis, and automate incident analysis to build a well-monitored network management team using AI. Through a real-world example of developing our own OFCNetLLM, based on the open-source LLM model, we demonstrate practical applications of OFCnetLLM in the OFC conference network. Our model is developed as a multi-agent approach and is still evolving, and we present early results here.
Hyperparameter Tuning for Deep Reinforcement Learning Applications
Jan 26, 2022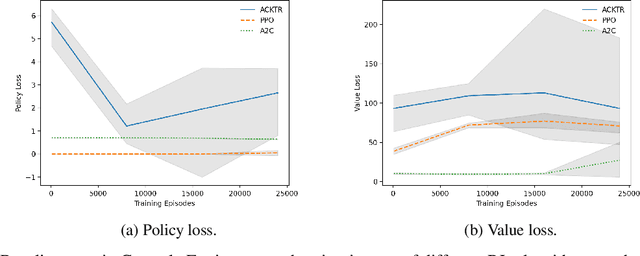
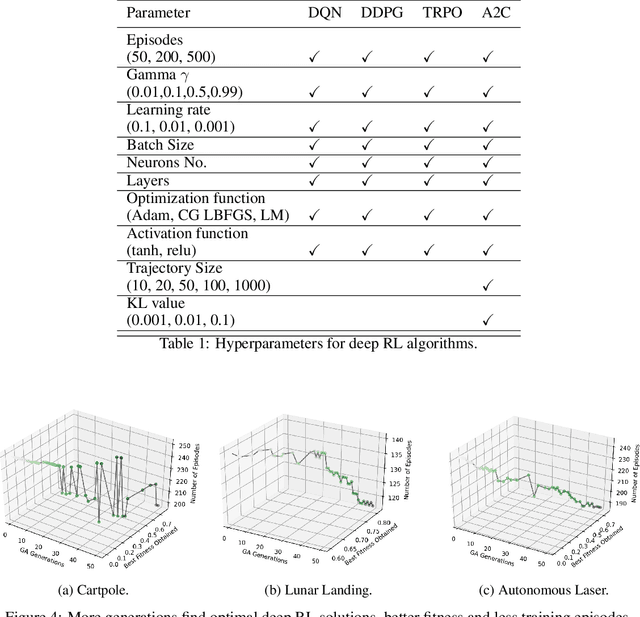
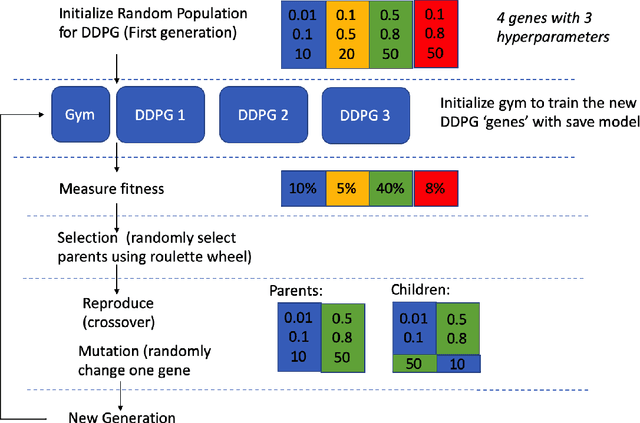

Reinforcement learning (RL) applications, where an agent can simply learn optimal behaviors by interacting with the environment, are quickly gaining tremendous success in a wide variety of applications from controlling simple pendulums to complex data centers. However, setting the right hyperparameters can have a huge impact on the deployed solution performance and reliability in the inference models, produced via RL, used for decision-making. Hyperparameter search itself is a laborious process that requires many iterations and computationally expensive to find the best settings that produce the best neural network architectures. In comparison to other neural network architectures, deep RL has not witnessed much hyperparameter tuning, due to its algorithm complexity and simulation platforms needed. In this paper, we propose a distributed variable-length genetic algorithm framework to systematically tune hyperparameters for various RL applications, improving training time and robustness of the architecture, via evolution. We demonstrate the scalability of our approach on many RL problems (from simple gyms to complex applications) and compared with Bayesian approach. Our results show that with more generations, optimal solutions that require fewer training episodes and are computationally cheap while being more robust for deployment. Our results are imperative to advance deep reinforcement learning controllers for real-world problems.
MAMRL: Exploiting Multi-agent Meta Reinforcement Learning in WAN Traffic Engineering
Nov 30, 2021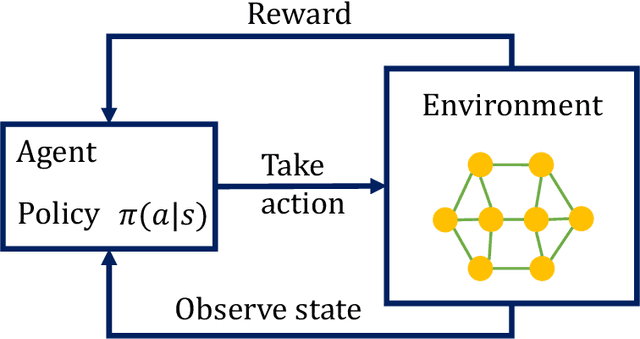


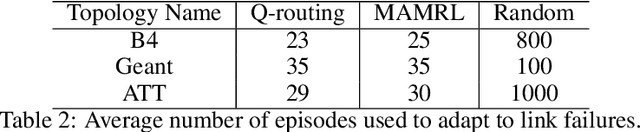
Traffic optimization challenges, such as load balancing, flow scheduling, and improving packet delivery time, are difficult online decision-making problems in wide area networks (WAN). Complex heuristics are needed for instance to find optimal paths that improve packet delivery time and minimize interruptions which may be caused by link failures or congestion. The recent success of reinforcement learning (RL) algorithms can provide useful solutions to build better robust systems that learn from experience in model-free settings. In this work, we consider a path optimization problem, specifically for packet routing, in large complex networks. We develop and evaluate a model-free approach, applying multi-agent meta reinforcement learning (MAMRL) that can determine the next-hop of each packet to get it delivered to its destination with minimum time overall. Specifically, we propose to leverage and compare deep policy optimization RL algorithms for enabling distributed model-free control in communication networks and present a novel meta-learning-based framework, MAMRL, for enabling quick adaptation to topology changes. To evaluate the proposed framework, we simulate with various WAN topologies. Our extensive packet-level simulation results show that compared to classical shortest path and traditional reinforcement learning approaches, MAMRL significantly reduces the average packet delivery time even when network demand increases; and compared to a non-meta deep policy optimization algorithm, our results show the reduction of packet loss in much fewer episodes when link failures occur while offering comparable average packet delivery time.
HYPPO: A Surrogate-Based Multi-Level Parallelism Tool for Hyperparameter Optimization
Oct 04, 2021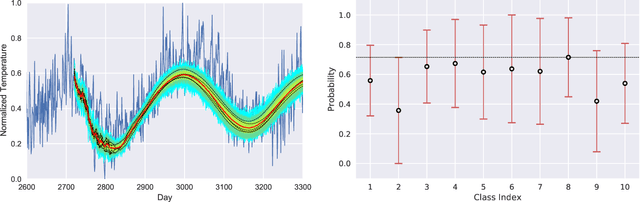
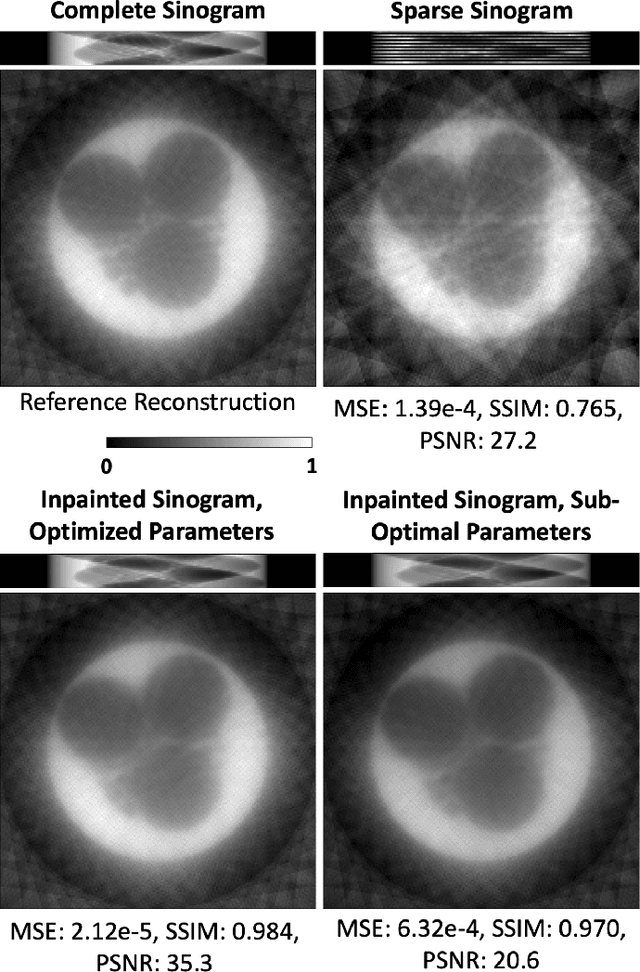
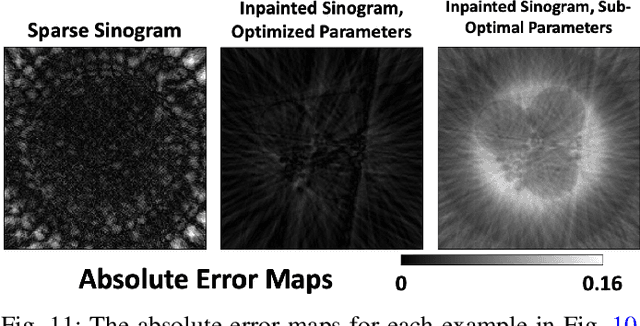
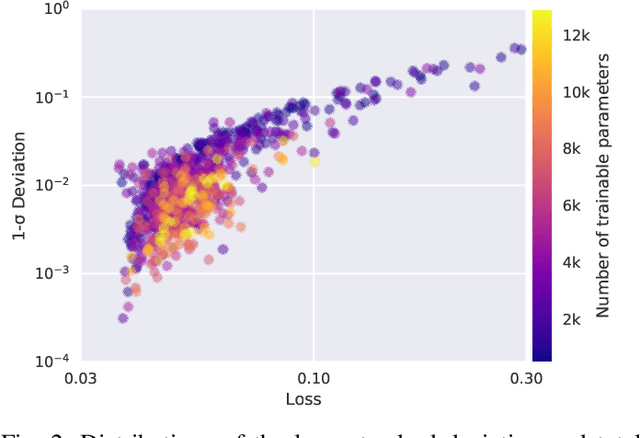
We present a new software, HYPPO, that enables the automatic tuning of hyperparameters of various deep learning (DL) models. Unlike other hyperparameter optimization (HPO) methods, HYPPO uses adaptive surrogate models and directly accounts for uncertainty in model predictions to find accurate and reliable models that make robust predictions. Using asynchronous nested parallelism, we are able to significantly alleviate the computational burden of training complex architectures and quantifying the uncertainty. HYPPO is implemented in Python and can be used with both TensorFlow and PyTorch libraries. We demonstrate various software features on time-series prediction and image classification problems as well as a scientific application in computed tomography image reconstruction. Finally, we show that (1) we can reduce by an order of magnitude the number of evaluations necessary to find the most optimal region in the hyperparameter space and (2) we can reduce by two orders of magnitude the throughput for such HPO process to complete.
Dynamic Graph Neural Network for Traffic Forecasting in Wide Area Networks
Aug 28, 2020

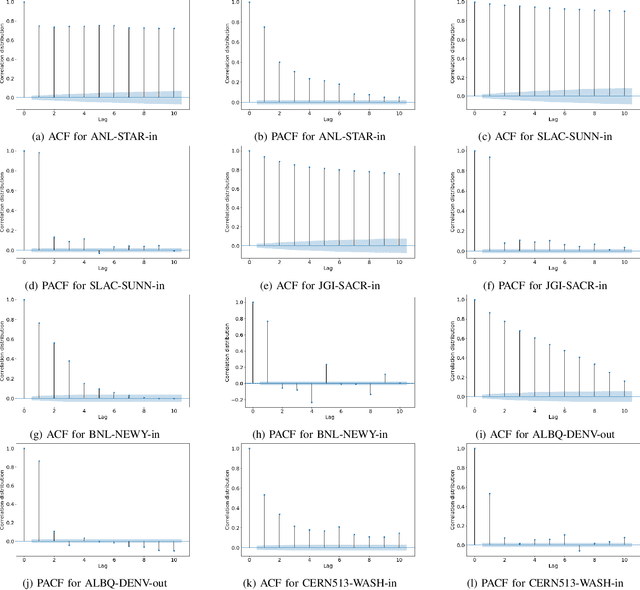

Wide area networking infrastructures (WANs), particularly science and research WANs, are the backbone for moving large volumes of scientific data between experimental facilities and data centers. With demands growing at exponential rates, these networks are struggling to cope with large data volumes, real-time responses, and overall network performance. Network operators are increasingly looking for innovative ways to manage the limited underlying network resources. Forecasting network traffic is a critical capability for proactive resource management, congestion mitigation, and dedicated transfer provisioning. To this end, we propose a nonautoregressive graph-based neural network for multistep network traffic forecasting. Specifically, we develop a dynamic variant of diffusion convolutional recurrent neural networks to forecast traffic in research WANs. We evaluate the efficacy of our approach on real traffic from ESnet, the U.S. Department of Energy's dedicated science network. Our results show that compared to classical forecasting methods, our approach explicitly learns the dynamic nature of spatiotemporal traffic patterns, showing significant improvements in forecasting accuracy. Our technique can surpass existing statistical and deep learning approaches by achieving approximately 20% mean absolute percentage error for multiple hours of forecasts despite dynamic network traffic settings.
Do optimization methods in deep learning applications matter?
Feb 28, 2020



With advances in deep learning, exponential data growth and increasing model complexity, developing efficient optimization methods are attracting much research attention. Several implementations favor the use of Conjugate Gradient (CG) and Stochastic Gradient Descent (SGD) as being practical and elegant solutions to achieve quick convergence, however, these optimization processes also present many limitations in learning across deep learning applications. Recent research is exploring higher-order optimization functions as better approaches, but these present very complex computational challenges for practical use. Comparing first and higher-order optimization functions, in this paper, our experiments reveal that Levemberg-Marquardt (LM) significantly supersedes optimal convergence but suffers from very large processing time increasing the training complexity of both, classification and reinforcement learning problems. Our experiments compare off-the-shelf optimization functions(CG, SGD, LM and L-BFGS) in standard CIFAR, MNIST, CartPole and FlappyBird experiments.The paper presents arguments on which optimization functions to use and further, which functions would benefit from parallelization efforts to improve pretraining time and learning rate convergence.