 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLossLens: Diagnostics for Machine Learning through Loss Landscape Visual Analytics
Dec 17, 2024



Modern machine learning often relies on optimizing a neural network's parameters using a loss function to learn complex features. Beyond training, examining the loss function with respect to a network's parameters (i.e., as a loss landscape) can reveal insights into the architecture and learning process. While the local structure of the loss landscape surrounding an individual solution can be characterized using a variety of approaches, the global structure of a loss landscape, which includes potentially many local minima corresponding to different solutions, remains far more difficult to conceptualize and visualize. To address this difficulty, we introduce LossLens, a visual analytics framework that explores loss landscapes at multiple scales. LossLens integrates metrics from global and local scales into a comprehensive visual representation, enhancing model diagnostics. We demonstrate LossLens through two case studies: visualizing how residual connections influence a ResNet-20, and visualizing how physical parameters influence a physics-informed neural network (PINN) solving a simple convection problem.
Visualizing Loss Functions as Topological Landscape Profiles
Nov 19, 2024



In machine learning, a loss function measures the difference between model predictions and ground-truth (or target) values. For neural network models, visualizing how this loss changes as model parameters are varied can provide insights into the local structure of the so-called loss landscape (e.g., smoothness) as well as global properties of the underlying model (e.g., generalization performance). While various methods for visualizing the loss landscape have been proposed, many approaches limit sampling to just one or two directions, ignoring potentially relevant information in this extremely high-dimensional space. This paper introduces a new representation based on topological data analysis that enables the visualization of higher-dimensional loss landscapes. After describing this new topological landscape profile representation, we show how the shape of loss landscapes can reveal new details about model performance and learning dynamics, highlighting several use cases, including image segmentation (e.g., UNet) and scientific machine learning (e.g., physics-informed neural networks). Through these examples, we provide new insights into how loss landscapes vary across distinct hyperparameter spaces: we find that the topology of the loss landscape is simpler for better-performing models; and we observe greater variation in the shape of loss landscapes near transitions from low to high model performance.
Case Study: Leveraging GenAI to Build AI-based Surrogates and Regressors for Modeling Radio Frequency Heating in Fusion Energy Science
Sep 10, 2024This work presents a detailed case study on using Generative AI (GenAI) to develop AI surrogates for simulation models in fusion energy research. The scope includes the methodology, implementation, and results of using GenAI to assist in model development and optimization, comparing these results with previous manually developed models.
AutoCT: Automated CT registration, segmentation, and quantification
Oct 26, 2023The processing and analysis of computed tomography (CT) imaging is important for both basic scientific development and clinical applications. In AutoCT, we provide a comprehensive pipeline that integrates an end-to-end automatic preprocessing, registration, segmentation, and quantitative analysis of 3D CT scans. The engineered pipeline enables atlas-based CT segmentation and quantification leveraging diffeomorphic transformations through efficient forward and inverse mappings. The extracted localized features from the deformation field allow for downstream statistical learning that may facilitate medical diagnostics. On a lightweight and portable software platform, AutoCT provides a new toolkit for the CT imaging community to underpin the deployment of artificial intelligence-driven applications.
A Self-Supervised Approach to Reconstruction in Sparse X-Ray Computed Tomography
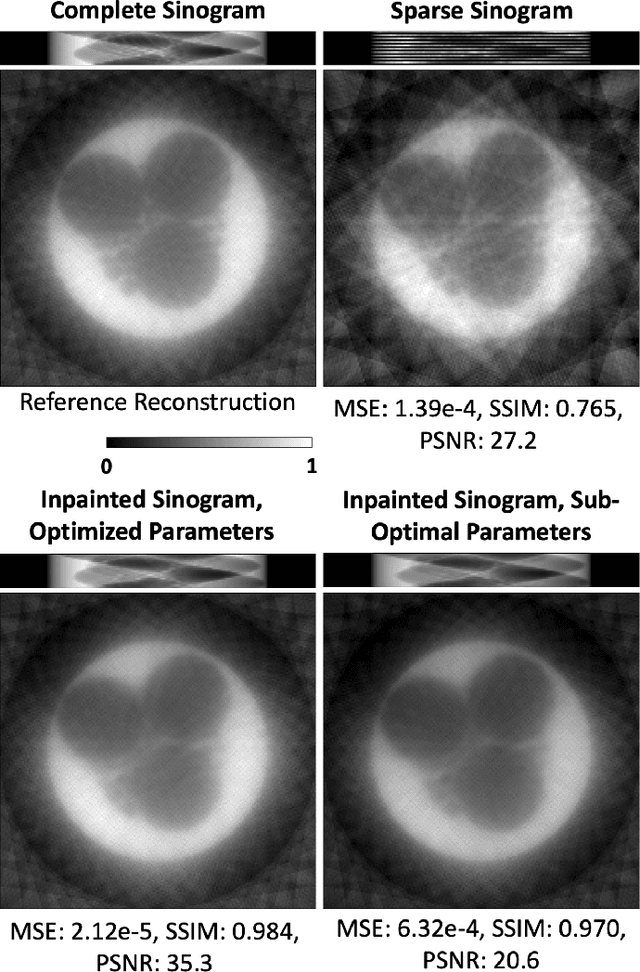
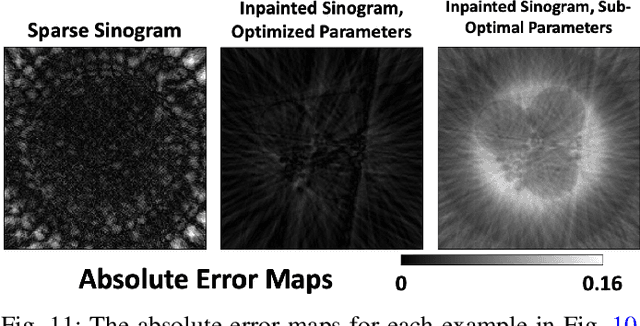
Oct 30, 2022Computed tomography has propelled scientific advances in fields from biology to materials science. This technology allows for the elucidation of 3-dimensional internal structure by the attenuation of x-rays through an object at different rotations relative to the beam. By imaging 2-dimensional projections, a 3-dimensional object can be reconstructed through a computational algorithm. Imaging at a greater number of rotation angles allows for improved reconstruction. However, taking more measurements increases the x-ray dose and may cause sample damage. Deep neural networks have been used to transform sparse 2-D projection measurements to a 3-D reconstruction by training on a dataset of known similar objects. However, obtaining high-quality object reconstructions for the training dataset requires high x-ray dose measurements that can destroy or alter the specimen before imaging is complete. This becomes a chicken-and-egg problem: high-quality reconstructions cannot be generated without deep learning, and the deep neural network cannot be learned without the reconstructions. This work develops and validates a self-supervised probabilistic deep learning technique, the physics-informed variational autoencoder, to solve this problem. A dataset consisting solely of sparse projection measurements from each object is used to jointly reconstruct all objects of the set. This approach has the potential to allow visualization of fragile samples with x-ray computed tomography. We release our code for reproducing our results at: https://github.com/vganapati/CT_PVAE .
Quantum pixel representations and compression for $N$-dimensional images
Oct 14, 2021



We introduce a novel and uniform framework for quantum pixel representations that overarches many of the most popular representations proposed in the recent literature, such as (I)FRQI, (I)NEQR, MCRQI, and (I)NCQI. The proposed QPIXL framework results in more efficient circuit implementations and significantly reduces the gate complexity for all considered quantum pixel representations. Our method only requires a linear number of gates in terms of the number of pixels and does not use ancilla qubits. Furthermore, the circuits only consist of Ry gates and CNOT gates making them practical in the NISQ era. Additionally, we propose a circuit and image compression algorithm that is shown to be highly effective, being able to reduce the necessary gates to prepare an FRQI state for example scientific images by up to 90% without sacrificing image quality. Our algorithms are made publicly available as part of QPIXL++, a Quantum Image Pixel Library.
HYPPO: A Surrogate-Based Multi-Level Parallelism Tool for Hyperparameter Optimization
Oct 04, 2021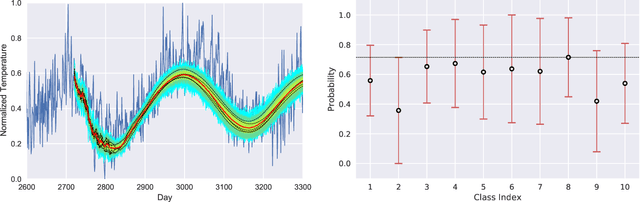
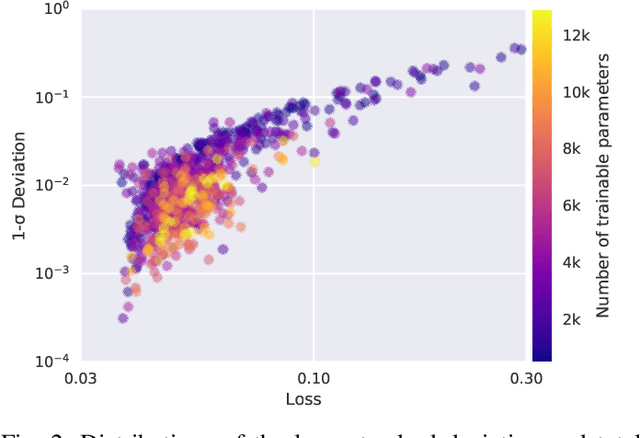
We present a new software, HYPPO, that enables the automatic tuning of hyperparameters of various deep learning (DL) models. Unlike other hyperparameter optimization (HPO) methods, HYPPO uses adaptive surrogate models and directly accounts for uncertainty in model predictions to find accurate and reliable models that make robust predictions. Using asynchronous nested parallelism, we are able to significantly alleviate the computational burden of training complex architectures and quantifying the uncertainty. HYPPO is implemented in Python and can be used with both TensorFlow and PyTorch libraries. We demonstrate various software features on time-series prediction and image classification problems as well as a scientific application in computed tomography image reconstruction. Finally, we show that (1) we can reduce by an order of magnitude the number of evaluations necessary to find the most optimal region in the hyperparameter space and (2) we can reduce by two orders of magnitude the throughput for such HPO process to complete.
Deconvolution of vibroacoustic images using a simulation model based on a three dimensional point spread function
Jul 13, 2012



Vibro-acoustography (VA) is a medical imaging method based on the difference-frequency generation produced by the mixture of two focused ultrasound beams. VA has been applied to different problems in medical imaging such as imaging bones, microcalcifications in the breast, mass lesions, and calcified arteries. The obtained images may have a resolution of 0.7--0.8 mm. Current VA systems based on confocal or linear array transducers generate C-scan images at the beam focal plane. Images on the axial plane are also possible, however the system resolution along depth worsens when compared to the lateral one. Typical axial resolution is about 1.0 cm. Furthermore, the elevation resolution of linear array systems is larger than that in lateral direction. This asymmetry degrades C-scan images obtained using linear arrays. The purpose of this article is to study VA image restoration based on a 3D point spread function (PSF) using classical deconvolution algorithms: Wiener, constrained least-squares (CLSs), and geometric mean filters. To assess the filters' performance, we use an image quality index that accounts for correlation loss, luminance and contrast distortion. Results for simulated VA images show that the quality index achieved with the Wiener filter is 0.9 (1 indicates perfect restoration). This filter yielded the best result in comparison with the other ones. Moreover, the deconvolution algorithms were applied to an experimental VA image of a phantom composed of three stretched 0.5 mm wires. Experiments were performed using transducer driven at two frequencies, 3075 kHz and 3125 kHz, which resulted in the difference-frequency of 50 kHz. Restorations with the theoretical line spread function (LSF) did not recover sufficient information to identify the wires in the images. However, using an estimated LSF the obtained results displayed enough information to spot the wires in the images.