 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLandscaper: Understanding Loss Landscapes Through Multi-Dimensional Topological Analysis
Feb 06, 2026Loss landscapes are a powerful tool for understanding neural network optimization and generalization, yet traditional low-dimensional analyses often miss complex topological features. We present Landscaper, an open-source Python package for arbitrary-dimensional loss landscape analysis. Landscaper combines Hessian-based subspace construction with topological data analysis to reveal geometric structures such as basin hierarchy and connectivity. A key component is the Saddle-Minimum Average Distance (SMAD) for quantifying landscape smoothness. We demonstrate Landscaper's effectiveness across various architectures and tasks, including those involving pre-trained language models, showing that SMAD captures training transitions, such as landscape simplification, that conventional metrics miss. We also illustrate Landscaper's performance in challenging chemical property prediction tasks, where SMAD can serve as a metric for out-of-distribution generalization, offering valuable insights for model diagnostics and architecture design in data-scarce scientific machine learning scenarios.
LossLens: Diagnostics for Machine Learning through Loss Landscape Visual Analytics
Dec 17, 2024



Modern machine learning often relies on optimizing a neural network's parameters using a loss function to learn complex features. Beyond training, examining the loss function with respect to a network's parameters (i.e., as a loss landscape) can reveal insights into the architecture and learning process. While the local structure of the loss landscape surrounding an individual solution can be characterized using a variety of approaches, the global structure of a loss landscape, which includes potentially many local minima corresponding to different solutions, remains far more difficult to conceptualize and visualize. To address this difficulty, we introduce LossLens, a visual analytics framework that explores loss landscapes at multiple scales. LossLens integrates metrics from global and local scales into a comprehensive visual representation, enhancing model diagnostics. We demonstrate LossLens through two case studies: visualizing how residual connections influence a ResNet-20, and visualizing how physical parameters influence a physics-informed neural network (PINN) solving a simple convection problem.
Visualizing Loss Functions as Topological Landscape Profiles
Nov 19, 2024



In machine learning, a loss function measures the difference between model predictions and ground-truth (or target) values. For neural network models, visualizing how this loss changes as model parameters are varied can provide insights into the local structure of the so-called loss landscape (e.g., smoothness) as well as global properties of the underlying model (e.g., generalization performance). While various methods for visualizing the loss landscape have been proposed, many approaches limit sampling to just one or two directions, ignoring potentially relevant information in this extremely high-dimensional space. This paper introduces a new representation based on topological data analysis that enables the visualization of higher-dimensional loss landscapes. After describing this new topological landscape profile representation, we show how the shape of loss landscapes can reveal new details about model performance and learning dynamics, highlighting several use cases, including image segmentation (e.g., UNet) and scientific machine learning (e.g., physics-informed neural networks). Through these examples, we provide new insights into how loss landscapes vary across distinct hyperparameter spaces: we find that the topology of the loss landscape is simpler for better-performing models; and we observe greater variation in the shape of loss landscapes near transitions from low to high model performance.
Evaluating Loss Landscapes from a Topology Perspective
Nov 14, 2024



Characterizing the loss of a neural network with respect to model parameters, i.e., the loss landscape, can provide valuable insights into properties of that model. Various methods for visualizing loss landscapes have been proposed, but less emphasis has been placed on quantifying and extracting actionable and reproducible insights from these complex representations. Inspired by powerful tools from topological data analysis (TDA) for summarizing the structure of high-dimensional data, here we characterize the underlying shape (or topology) of loss landscapes, quantifying the topology to reveal new insights about neural networks. To relate our findings to the machine learning (ML) literature, we compute simple performance metrics (e.g., accuracy, error), and we characterize the local structure of loss landscapes using Hessian-based metrics (e.g., largest eigenvalue, trace, eigenvalue spectral density). Following this approach, we study established models from image pattern recognition (e.g., ResNets) and scientific ML (e.g., physics-informed neural networks), and we show how quantifying the shape of loss landscapes can provide new insights into model performance and learning dynamics.
MultiFair: Multi-Group Fairness in Machine Learning
May 24, 2021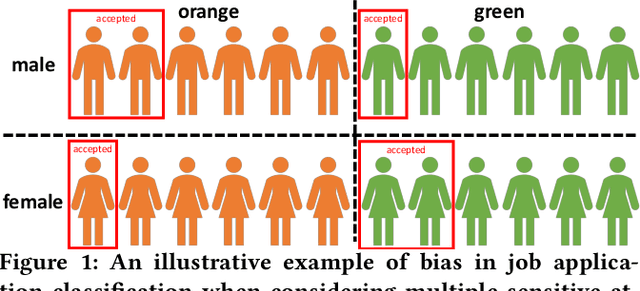

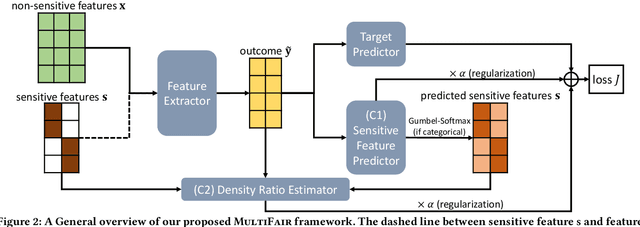
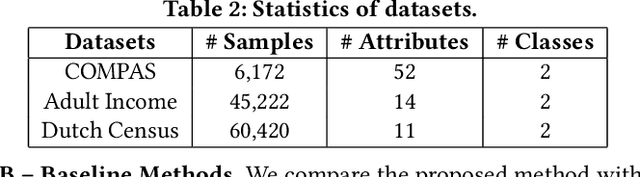
Algorithmic fairness is becoming increasingly important in data mining and machine learning, and one of the most fundamental notions is group fairness. The vast majority of the existing works on group fairness, with a few exceptions, primarily focus on debiasing with respect to a single sensitive attribute, despite the fact that the co-existence of multiple sensitive attributes (e.g., gender, race, marital status, etc.) in the real-world is commonplace. As such, methods that can ensure a fair learning outcome with respect to all sensitive attributes of concern simultaneously need to be developed. In this paper, we study multi-group fairness in machine learning (MultiFair), where statistical parity, a representative group fairness measure, is guaranteed among demographic groups formed by multiple sensitive attributes of interest. We formulate it as a mutual information minimization problem and propose a generic end-to-end algorithmic framework to solve it. The key idea is to leverage a variational representation of mutual information, which considers the variational distribution between learning outcomes and sensitive attributes, as well as the density ratio between the variational and the original distributions. Our proposed framework is generalizable to many different settings, including other statistical notions of fairness, and could handle any type of learning task equipped with a gradient-based optimizer. Empirical evaluations in the fair classification task on three real-world datasets demonstrate that our proposed framework can effectively debias the classification results with minimal impact to the classification accuracy.
Explaining Vulnerabilities to Adversarial Machine Learning through Visual Analytics
Jul 20, 2019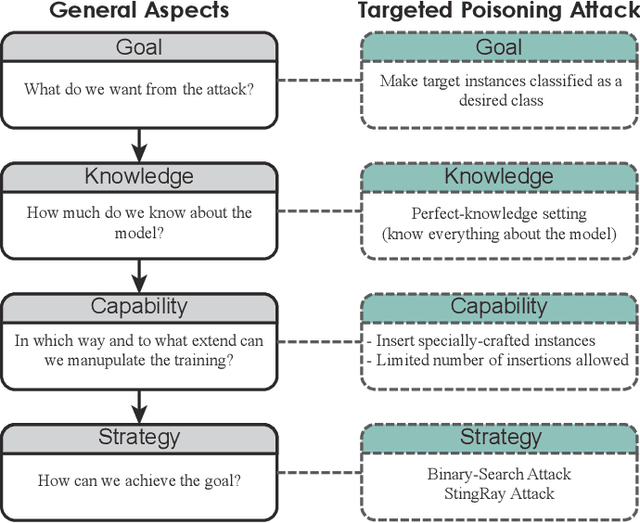
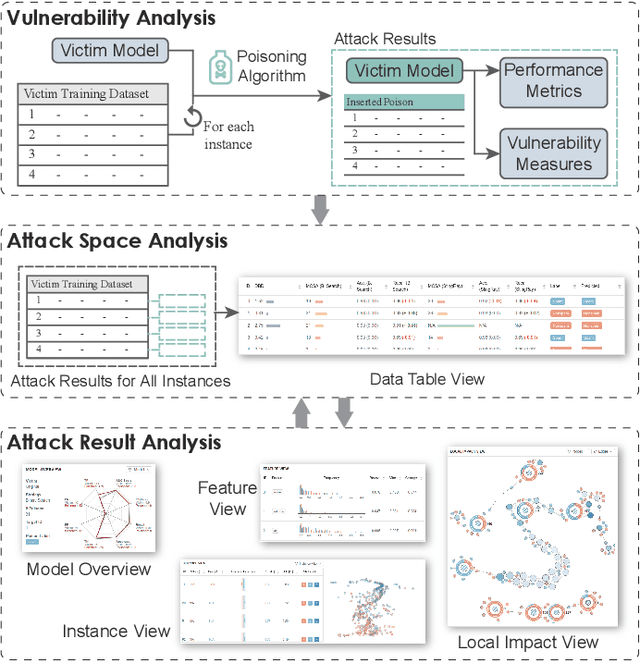
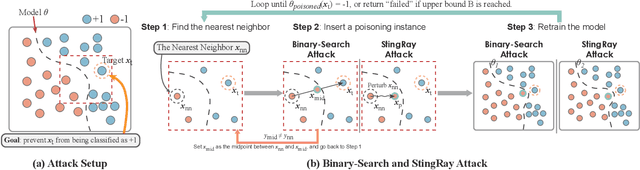
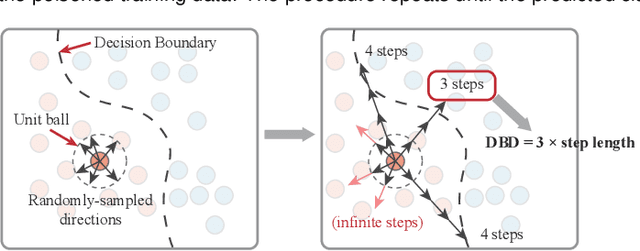
Machine learning models are currently being deployed in a variety of real-world applications where model predictions are used to make decisions about healthcare, bank loans, and numerous other critical tasks. As the deployment of artificial intelligence technologies becomes ubiquitous, it is unsurprising that adversaries have begun developing methods to manipulate machine learning models to their advantage. While the visual analytics community has developed methods for opening the black box of machine learning models, little work has focused on helping the user understand their model vulnerabilities in the context of adversarial attacks. In this paper, we present a visual analytics framework for explaining and exploring model vulnerabilities to adversarial attacks. Our framework employs a multi-faceted visualization scheme designed to support the analysis of data poisoning attacks from the perspective of models, data instances, features, and local structures. We demonstrate our framework through two case studies on binary classifiers and illustrate model vulnerabilities with respect to varying attack strategies.