 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExplaining Vulnerabilities to Adversarial Machine Learning through Visual Analytics
Paper and Code
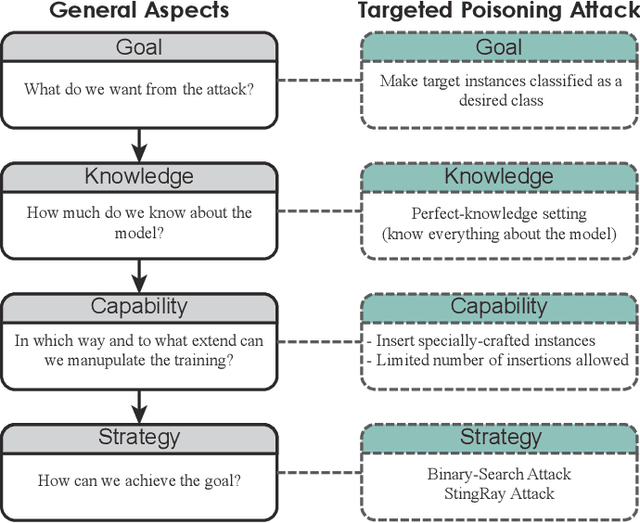
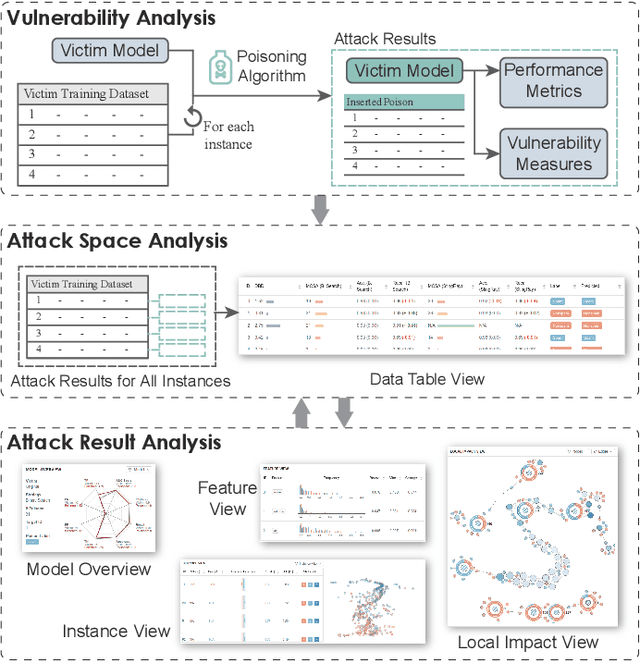
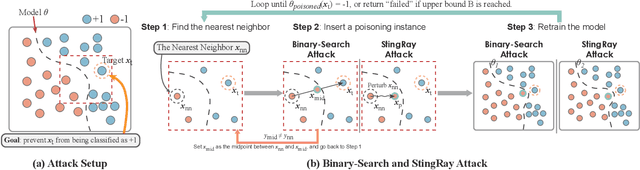
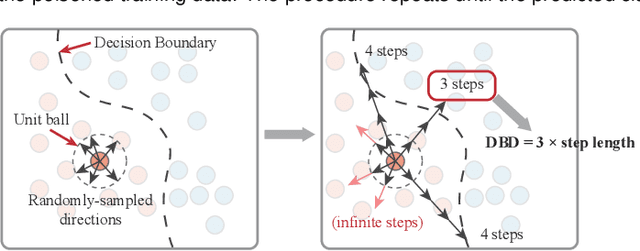
Machine learning models are currently being deployed in a variety of real-world applications where model predictions are used to make decisions about healthcare, bank loans, and numerous other critical tasks. As the deployment of artificial intelligence technologies becomes ubiquitous, it is unsurprising that adversaries have begun developing methods to manipulate machine learning models to their advantage. While the visual analytics community has developed methods for opening the black box of machine learning models, little work has focused on helping the user understand their model vulnerabilities in the context of adversarial attacks. In this paper, we present a visual analytics framework for explaining and exploring model vulnerabilities to adversarial attacks. Our framework employs a multi-faceted visualization scheme designed to support the analysis of data poisoning attacks from the perspective of models, data instances, features, and local structures. We demonstrate our framework through two case studies on binary classifiers and illustrate model vulnerabilities with respect to varying attack strategies.