 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLandscaper: Understanding Loss Landscapes Through Multi-Dimensional Topological Analysis
Feb 06, 2026Loss landscapes are a powerful tool for understanding neural network optimization and generalization, yet traditional low-dimensional analyses often miss complex topological features. We present Landscaper, an open-source Python package for arbitrary-dimensional loss landscape analysis. Landscaper combines Hessian-based subspace construction with topological data analysis to reveal geometric structures such as basin hierarchy and connectivity. A key component is the Saddle-Minimum Average Distance (SMAD) for quantifying landscape smoothness. We demonstrate Landscaper's effectiveness across various architectures and tasks, including those involving pre-trained language models, showing that SMAD captures training transitions, such as landscape simplification, that conventional metrics miss. We also illustrate Landscaper's performance in challenging chemical property prediction tasks, where SMAD can serve as a metric for out-of-distribution generalization, offering valuable insights for model diagnostics and architecture design in data-scarce scientific machine learning scenarios.
MapIQ: Benchmarking Multimodal Large Language Models for Map Question Answering
Jul 15, 2025Recent advancements in multimodal large language models (MLLMs) have driven researchers to explore how well these models read data visualizations, e.g., bar charts, scatter plots. More recently, attention has shifted to visual question answering with maps (Map-VQA). However, Map-VQA research has primarily focused on choropleth maps, which cover only a limited range of thematic categories and visual analytical tasks. To address these gaps, we introduce MapIQ, a benchmark dataset comprising 14,706 question-answer pairs across three map types: choropleth maps, cartograms, and proportional symbol maps spanning topics from six distinct themes (e.g., housing, crime). We evaluate multiple MLLMs using six visual analytical tasks, comparing their performance against one another and a human baseline. An additional experiment examining the impact of map design changes (e.g., altered color schemes, modified legend designs, and removal of map elements) provides insights into the robustness and sensitivity of MLLMs, their reliance on internal geographic knowledge, and potential avenues for improving Map-VQA performance.
Learnable Spatial-Temporal Positional Encoding for Link Prediction
Jun 11, 2025Accurate predictions rely on the expressiveness power of graph deep learning frameworks like graph neural networks and graph transformers, where a positional encoding mechanism has become much more indispensable in recent state-of-the-art works to record the canonical position information. However, the current positional encoding is limited in three aspects: (1) most positional encoding methods use pre-defined, and fixed functions, which are inadequate to adapt to the complex attributed graphs; (2) a few pioneering works proposed the learnable positional encoding but are still limited to the structural information, not considering the real-world time-evolving topological and feature information; (3) most positional encoding methods are equipped with transformers' attention mechanism to fully leverage their capabilities, where the dense or relational attention is often unaffordable on large-scale structured data. Hence, we aim to develop Learnable Spatial-Temporal Positional Encoding in an effective and efficient manner and propose a simple temporal link prediction model named L-STEP. Briefly, for L-STEP, we (1) prove the proposed positional learning scheme can preserve the graph property from the spatial-temporal spectral viewpoint, (2) verify that MLPs can fully exploit the expressiveness and reach transformers' performance on that encoding, (3) change different initial positional encoding inputs to show robustness, (4) analyze the theoretical complexity and obtain less empirical running time than SOTA, and (5) demonstrate its temporal link prediction out-performance on 13 classic datasets and with 10 algorithms in both transductive and inductive settings using 3 different sampling strategies. Also, L-STEP obtains the leading performance in the newest large-scale TGB benchmark. Our code is available at https://github.com/kthrn22/L-STEP.
LossLens: Diagnostics for Machine Learning through Loss Landscape Visual Analytics
Dec 17, 2024



Modern machine learning often relies on optimizing a neural network's parameters using a loss function to learn complex features. Beyond training, examining the loss function with respect to a network's parameters (i.e., as a loss landscape) can reveal insights into the architecture and learning process. While the local structure of the loss landscape surrounding an individual solution can be characterized using a variety of approaches, the global structure of a loss landscape, which includes potentially many local minima corresponding to different solutions, remains far more difficult to conceptualize and visualize. To address this difficulty, we introduce LossLens, a visual analytics framework that explores loss landscapes at multiple scales. LossLens integrates metrics from global and local scales into a comprehensive visual representation, enhancing model diagnostics. We demonstrate LossLens through two case studies: visualizing how residual connections influence a ResNet-20, and visualizing how physical parameters influence a physics-informed neural network (PINN) solving a simple convection problem.
Visualizing Loss Functions as Topological Landscape Profiles
Nov 19, 2024



In machine learning, a loss function measures the difference between model predictions and ground-truth (or target) values. For neural network models, visualizing how this loss changes as model parameters are varied can provide insights into the local structure of the so-called loss landscape (e.g., smoothness) as well as global properties of the underlying model (e.g., generalization performance). While various methods for visualizing the loss landscape have been proposed, many approaches limit sampling to just one or two directions, ignoring potentially relevant information in this extremely high-dimensional space. This paper introduces a new representation based on topological data analysis that enables the visualization of higher-dimensional loss landscapes. After describing this new topological landscape profile representation, we show how the shape of loss landscapes can reveal new details about model performance and learning dynamics, highlighting several use cases, including image segmentation (e.g., UNet) and scientific machine learning (e.g., physics-informed neural networks). Through these examples, we provide new insights into how loss landscapes vary across distinct hyperparameter spaces: we find that the topology of the loss landscape is simpler for better-performing models; and we observe greater variation in the shape of loss landscapes near transitions from low to high model performance.
Evaluating Loss Landscapes from a Topology Perspective
Nov 14, 2024



Characterizing the loss of a neural network with respect to model parameters, i.e., the loss landscape, can provide valuable insights into properties of that model. Various methods for visualizing loss landscapes have been proposed, but less emphasis has been placed on quantifying and extracting actionable and reproducible insights from these complex representations. Inspired by powerful tools from topological data analysis (TDA) for summarizing the structure of high-dimensional data, here we characterize the underlying shape (or topology) of loss landscapes, quantifying the topology to reveal new insights about neural networks. To relate our findings to the machine learning (ML) literature, we compute simple performance metrics (e.g., accuracy, error), and we characterize the local structure of loss landscapes using Hessian-based metrics (e.g., largest eigenvalue, trace, eigenvalue spectral density). Following this approach, we study established models from image pattern recognition (e.g., ResNets) and scientific ML (e.g., physics-informed neural networks), and we show how quantifying the shape of loss landscapes can provide new insights into model performance and learning dynamics.
IDNet: A Novel Dataset for Identity Document Analysis and Fraud Detection
Aug 03, 2024
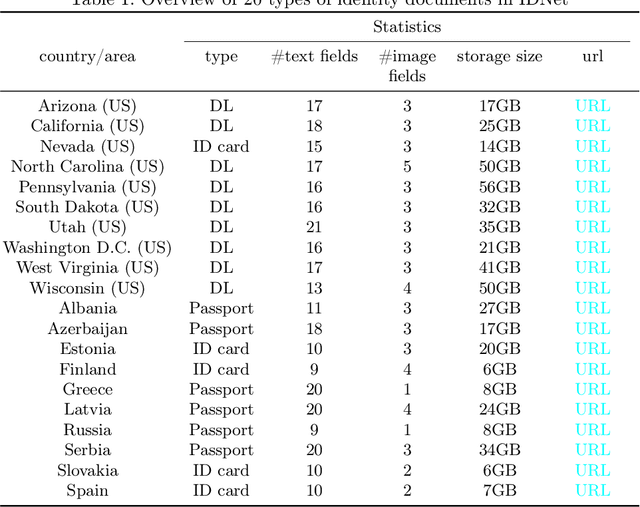


Effective fraud detection and analysis of government-issued identity documents, such as passports, driver's licenses, and identity cards, are essential in thwarting identity theft and bolstering security on online platforms. The training of accurate fraud detection and analysis tools depends on the availability of extensive identity document datasets. However, current publicly available benchmark datasets for identity document analysis, including MIDV-500, MIDV-2020, and FMIDV, fall short in several respects: they offer a limited number of samples, cover insufficient varieties of fraud patterns, and seldom include alterations in critical personal identifying fields like portrait images, limiting their utility in training models capable of detecting realistic frauds while preserving privacy. In response to these shortcomings, our research introduces a new benchmark dataset, IDNet, designed to advance privacy-preserving fraud detection efforts. The IDNet dataset comprises 837,060 images of synthetically generated identity documents, totaling approximately 490 gigabytes, categorized into 20 types from $10$ U.S. states and 10 European countries. We evaluate the utility and present use cases of the dataset, illustrating how it can aid in training privacy-preserving fraud detection methods, facilitating the generation of camera and video capturing of identity documents, and testing schema unification and other identity document management functionalities.
Capturing Cancer as Music: Cancer Mechanisms Expressed through Musification
Feb 09, 2024



The development of cancer is difficult to express on a simple and intuitive level due to its complexity. Since cancer is so widespread, raising public awareness about its mechanisms can help those affected cope with its realities, as well as inspire others to make lifestyle adjustments and screen for the disease. Unfortunately, studies have shown that cancer literature is too technical for the general public to understand. We found that musification, the process of turning data into music, remains an unexplored avenue for conveying this information. We explore the pedagogical effectiveness of musification through the use of an algorithm that manipulates a piece of music in a manner analogous to the development of cancer. We conducted two lab studies and found that our approach is marginally more effective at promoting cancer literacy when accompanied by a text-based article than text-based articles alone.
Deceptive Fairness Attacks on Graphs via Meta Learning
Oct 24, 2023We study deceptive fairness attacks on graphs to answer the following question: How can we achieve poisoning attacks on a graph learning model to exacerbate the bias deceptively? We answer this question via a bi-level optimization problem and propose a meta learning-based framework named FATE. FATE is broadly applicable with respect to various fairness definitions and graph learning models, as well as arbitrary choices of manipulation operations. We further instantiate FATE to attack statistical parity and individual fairness on graph neural networks. We conduct extensive experimental evaluations on real-world datasets in the task of semi-supervised node classification. The experimental results demonstrate that FATE could amplify the bias of graph neural networks with or without fairness consideration while maintaining the utility on the downstream task. We hope this paper provides insights into the adversarial robustness of fair graph learning and can shed light on designing robust and fair graph learning in future studies.
GeoExplainer: A Visual Analytics Framework for Spatial Modeling Contextualization and Report Generation
Aug 25, 2023
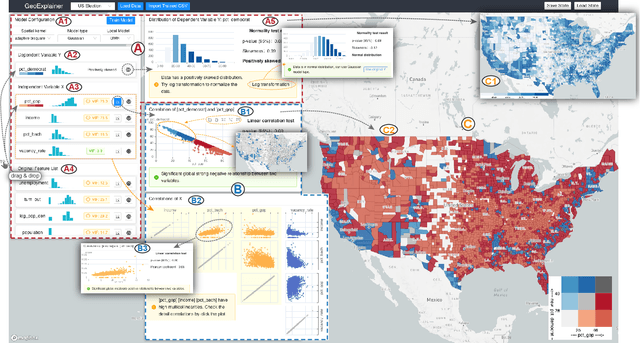


Geographic regression models of various descriptions are often applied to identify patterns and anomalies in the determinants of spatially distributed observations. These types of analyses focus on answering why questions about underlying spatial phenomena, e.g., why is crime higher in this locale, why do children in one school district outperform those in another, etc.? Answers to these questions require explanations of the model structure, the choice of parameters, and contextualization of the findings with respect to their geographic context. This is particularly true for local forms of regression models which are focused on the role of locational context in determining human behavior. In this paper, we present GeoExplainer, a visual analytics framework designed to support analysts in creating explanative documentation that summarizes and contextualizes their spatial analyses. As analysts create their spatial models, our framework flags potential issues with model parameter selections, utilizes template-based text generation to summarize model outputs, and links with external knowledge repositories to provide annotations that help to explain the model results. As analysts explore the model results, all visualizations and annotations can be captured in an interactive report generation widget. We demonstrate our framework using a case study modeling the determinants of voting in the 2016 US Presidential Election.