 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvaluating Evaluation Metrics -- The Mirage of Hallucination Detection
Apr 25, 2025Hallucinations pose a significant obstacle to the reliability and widespread adoption of language models, yet their accurate measurement remains a persistent challenge. While many task- and domain-specific metrics have been proposed to assess faithfulness and factuality concerns, the robustness and generalization of these metrics are still untested. In this paper, we conduct a large-scale empirical evaluation of 6 diverse sets of hallucination detection metrics across 4 datasets, 37 language models from 5 families, and 5 decoding methods. Our extensive investigation reveals concerning gaps in current hallucination evaluation: metrics often fail to align with human judgments, take an overtly myopic view of the problem, and show inconsistent gains with parameter scaling. Encouragingly, LLM-based evaluation, particularly with GPT-4, yields the best overall results, and mode-seeking decoding methods seem to reduce hallucinations, especially in knowledge-grounded settings. These findings underscore the need for more robust metrics to understand and quantify hallucinations, and better strategies to mitigate them.
Crowdsource, Crawl, or Generate? Creating SEA-VL, a Multicultural Vision-Language Dataset for Southeast Asia
Mar 10, 2025



Southeast Asia (SEA) is a region of extraordinary linguistic and cultural diversity, yet it remains significantly underrepresented in vision-language (VL) research. This often results in artificial intelligence (AI) models that fail to capture SEA cultural nuances. To fill this gap, we present SEA-VL, an open-source initiative dedicated to developing high-quality, culturally relevant data for SEA languages. By involving contributors from SEA countries, SEA-VL aims to ensure better cultural relevance and diversity, fostering greater inclusivity of underrepresented languages in VL research. Beyond crowdsourcing, our initiative goes one step further in the exploration of the automatic collection of culturally relevant images through crawling and image generation. First, we find that image crawling achieves approximately ~85% cultural relevance while being more cost- and time-efficient than crowdsourcing. Second, despite the substantial progress in generative vision models, synthetic images remain unreliable in accurately reflecting SEA cultures. The generated images often fail to reflect the nuanced traditions and cultural contexts of the region. Collectively, we gather 1.28M SEA culturally-relevant images, more than 50 times larger than other existing datasets. Through SEA-VL, we aim to bridge the representation gap in SEA, fostering the development of more inclusive AI systems that authentically represent diverse cultures across SEA.
SEACrowd: A Multilingual Multimodal Data Hub and Benchmark Suite for Southeast Asian Languages
Jun 14, 2024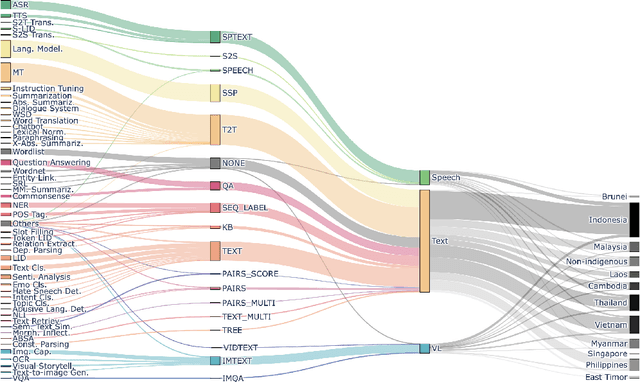
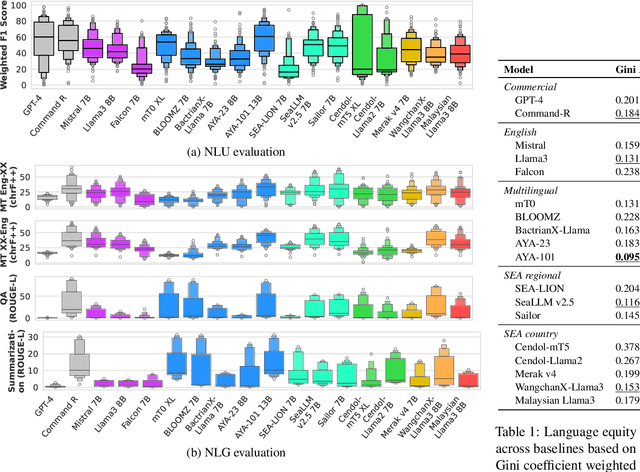
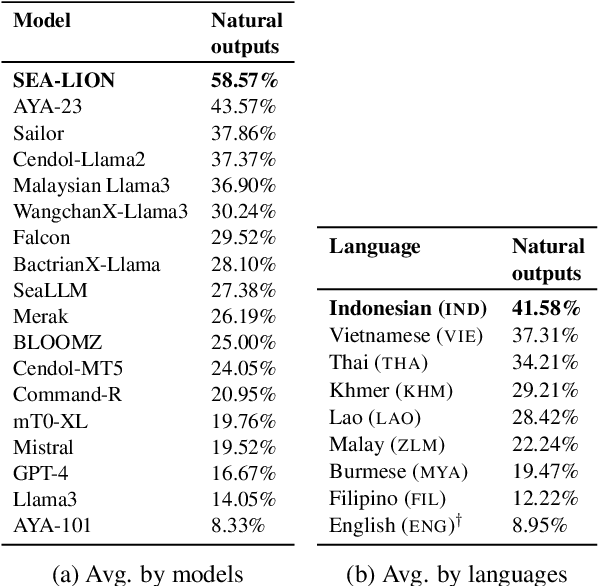
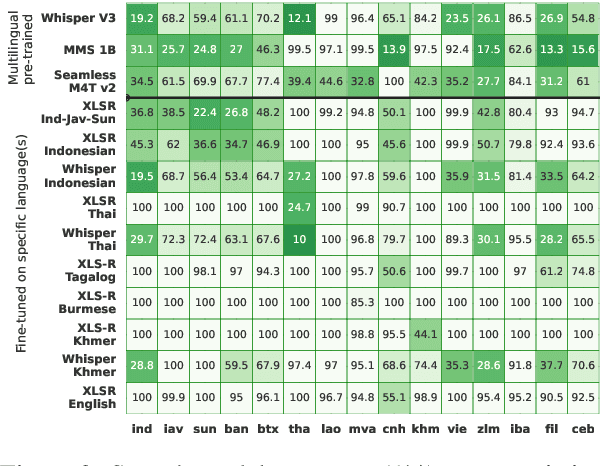
Southeast Asia (SEA) is a region rich in linguistic diversity and cultural variety, with over 1,300 indigenous languages and a population of 671 million people. However, prevailing AI models suffer from a significant lack of representation of texts, images, and audio datasets from SEA, compromising the quality of AI models for SEA languages. Evaluating models for SEA languages is challenging due to the scarcity of high-quality datasets, compounded by the dominance of English training data, raising concerns about potential cultural misrepresentation. To address these challenges, we introduce SEACrowd, a collaborative initiative that consolidates a comprehensive resource hub that fills the resource gap by providing standardized corpora in nearly 1,000 SEA languages across three modalities. Through our SEACrowd benchmarks, we assess the quality of AI models on 36 indigenous languages across 13 tasks, offering valuable insights into the current AI landscape in SEA. Furthermore, we propose strategies to facilitate greater AI advancements, maximizing potential utility and resource equity for the future of AI in SEA.
ReALM: Reference Resolution As Language Modeling
Mar 29, 2024
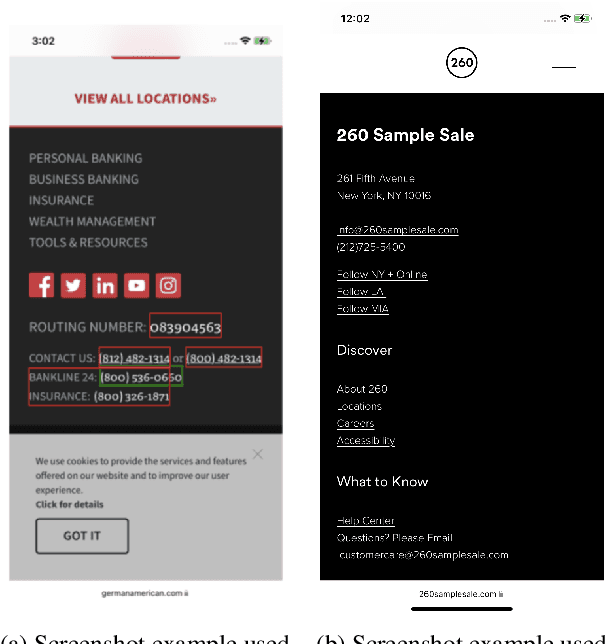
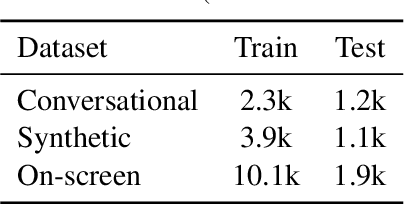
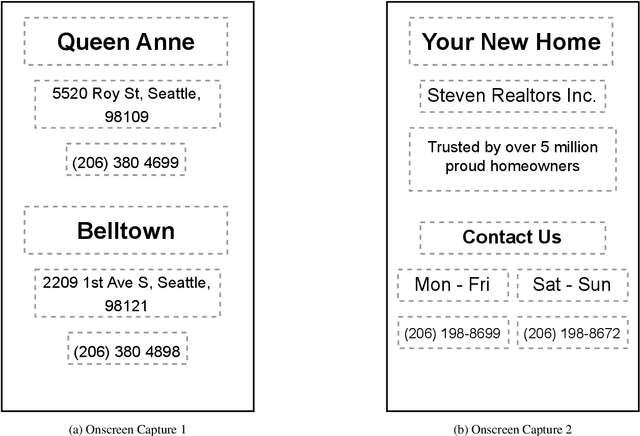
Reference resolution is an important problem, one that is essential to understand and successfully handle context of different kinds. This context includes both previous turns and context that pertains to non-conversational entities, such as entities on the user's screen or those running in the background. While LLMs have been shown to be extremely powerful for a variety of tasks, their use in reference resolution, particularly for non-conversational entities, remains underutilized. This paper demonstrates how LLMs can be used to create an extremely effective system to resolve references of various types, by showing how reference resolution can be converted into a language modeling problem, despite involving forms of entities like those on screen that are not traditionally conducive to being reduced to a text-only modality. We demonstrate large improvements over an existing system with similar functionality across different types of references, with our smallest model obtaining absolute gains of over 5% for on-screen references. We also benchmark against GPT-3.5 and GPT-4, with our smallest model achieving performance comparable to that of GPT-4, and our larger models substantially outperforming it.
SynthDST: Synthetic Data is All You Need for Few-Shot Dialog State Tracking
Feb 03, 2024



In-context learning with Large Language Models (LLMs) has emerged as a promising avenue of research in Dialog State Tracking (DST). However, the best-performing in-context learning methods involve retrieving and adding similar examples to the prompt, requiring access to labeled training data. Procuring such training data for a wide range of domains and applications is time-consuming, expensive, and, at times, infeasible. While zero-shot learning requires no training data, it significantly lags behind the few-shot setup. Thus, `\textit{Can we efficiently generate synthetic data for any dialogue schema to enable few-shot prompting?}' Addressing this question, we propose \method, a data generation framework tailored for DST, utilizing LLMs. Our approach only requires the dialogue schema and a few hand-crafted dialogue templates to synthesize natural, coherent, and free-flowing dialogues with DST annotations. Few-shot learning using data from {\method} results in $4-5%$ improvement in Joint Goal Accuracy over the zero-shot baseline on MultiWOZ 2.1 and 2.4. Remarkably, our few-shot learning approach recovers nearly $98%$ of the performance compared to the few-shot setup using human-annotated training data. Our synthetic data and code can be accessed at https://github.com/apple/ml-synthdst
Can Large Language Models Understand Context?
Feb 01, 2024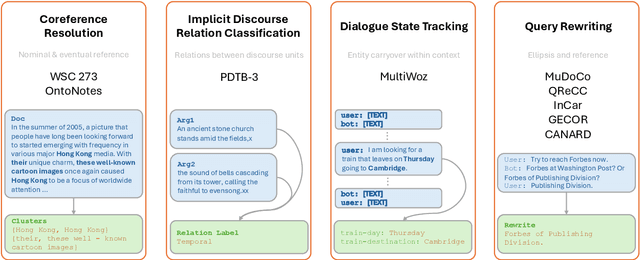


Understanding context is key to understanding human language, an ability which Large Language Models (LLMs) have been increasingly seen to demonstrate to an impressive extent. However, though the evaluation of LLMs encompasses various domains within the realm of Natural Language Processing, limited attention has been paid to probing their linguistic capability of understanding contextual features. This paper introduces a context understanding benchmark by adapting existing datasets to suit the evaluation of generative models. This benchmark comprises of four distinct tasks and nine datasets, all featuring prompts designed to assess the models' ability to understand context. First, we evaluate the performance of LLMs under the in-context learning pretraining scenario. Experimental results indicate that pre-trained dense models struggle with understanding more nuanced contextual features when compared to state-of-the-art fine-tuned models. Second, as LLM compression holds growing significance in both research and real-world applications, we assess the context understanding of quantized models under in-context-learning settings. We find that 3-bit post-training quantization leads to varying degrees of performance reduction on our benchmark. We conduct an extensive analysis of these scenarios to substantiate our experimental results.
MARRS: Multimodal Reference Resolution System
Nov 03, 2023



Successfully handling context is essential for any dialog understanding task. This context maybe be conversational (relying on previous user queries or system responses), visual (relying on what the user sees, for example, on their screen), or background (based on signals such as a ringing alarm or playing music). In this work, we present an overview of MARRS, or Multimodal Reference Resolution System, an on-device framework within a Natural Language Understanding system, responsible for handling conversational, visual and background context. In particular, we present different machine learning models to enable handing contextual queries; specifically, one to enable reference resolution, and one to handle context via query rewriting. We also describe how these models complement each other to form a unified, coherent, lightweight system that can understand context while preserving user privacy.
STEER: Semantic Turn Extension-Expansion Recognition for Voice Assistants
Oct 25, 2023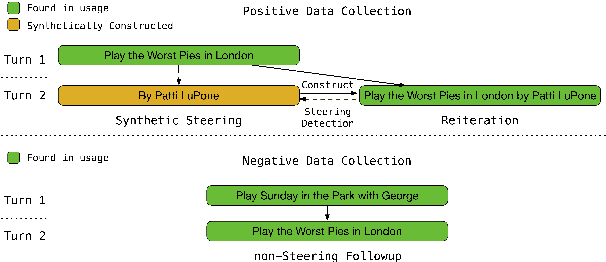

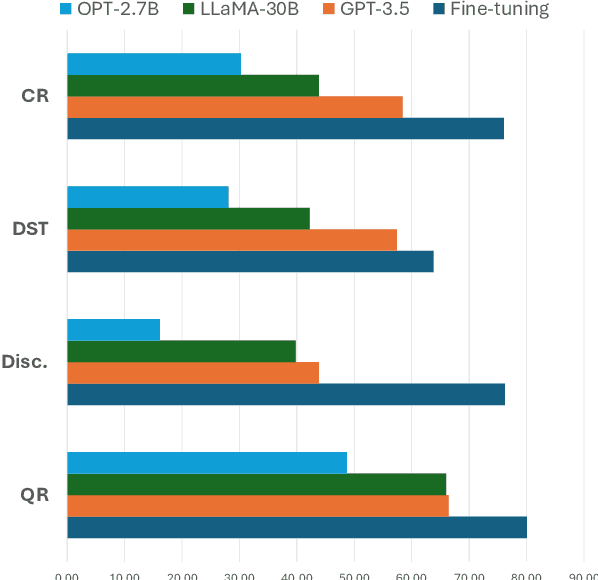
In the context of a voice assistant system, steering refers to the phenomenon in which a user issues a follow-up command attempting to direct or clarify a previous turn. We propose STEER, a steering detection model that predicts whether a follow-up turn is a user's attempt to steer the previous command. Constructing a training dataset for steering use cases poses challenges due to the cold-start problem. To overcome this, we developed heuristic rules to sample opt-in usage data, approximating positive and negative samples without any annotation. Our experimental results show promising performance in identifying steering intent, with over 95% accuracy on our sampled data. Moreover, STEER, in conjunction with our sampling strategy, aligns effectively with real-world steering scenarios, as evidenced by its strong zero-shot performance on a human-graded evaluation set. In addition to relying solely on user transcripts as input, we introduce STEER+, an enhanced version of the model. STEER+ utilizes a semantic parse tree to provide more context on out-of-vocabulary words, such as named entities that often occur at the sentence boundary. This further improves model performance, reducing error rate in domains where entities frequently appear, such as messaging. Lastly, we present a data analysis that highlights the improvement in user experience when voice assistants support steering use cases.
Intelligent Assistant Language Understanding On Device
Aug 07, 2023
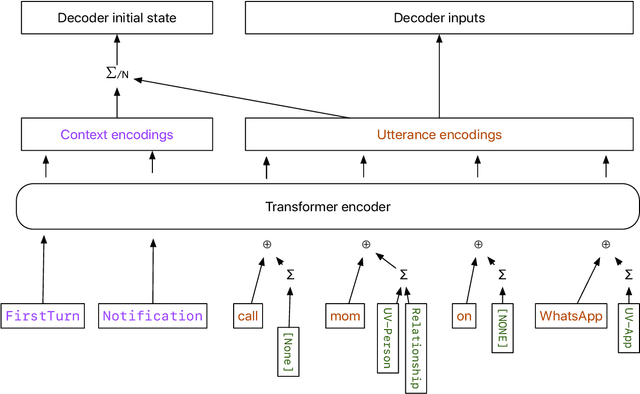
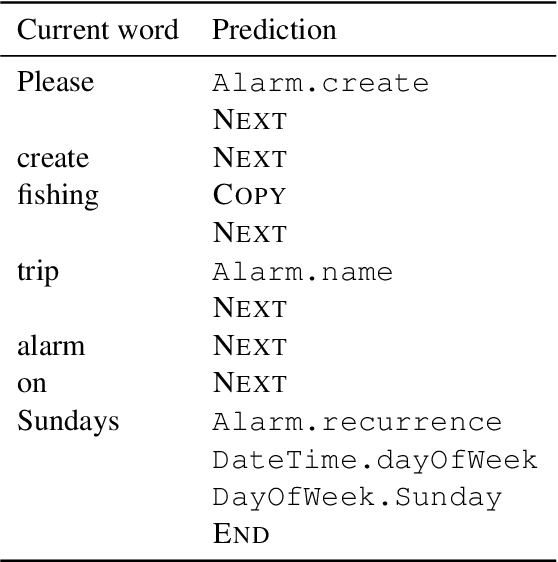

It has recently become feasible to run personal digital assistants on phones and other personal devices. In this paper we describe a design for a natural language understanding system that runs on device. In comparison to a server-based assistant, this system is more private, more reliable, faster, more expressive, and more accurate. We describe what led to key choices about architecture and technologies. For example, some approaches in the dialog systems literature are difficult to maintain over time in a deployment setting. We hope that sharing learnings from our practical experiences may help inform future work in the research community.
5IDER: Unified Query Rewriting for Steering, Intent Carryover, Disfluencies, Entity Carryover and Repair
Jun 02, 2023
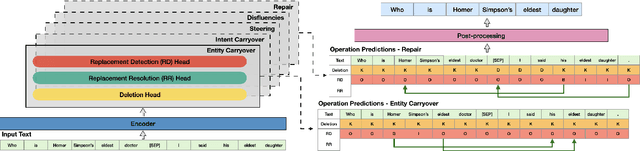
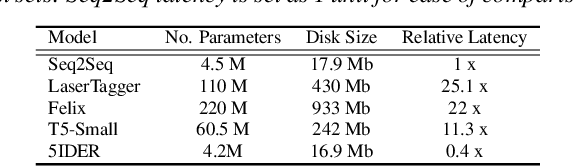
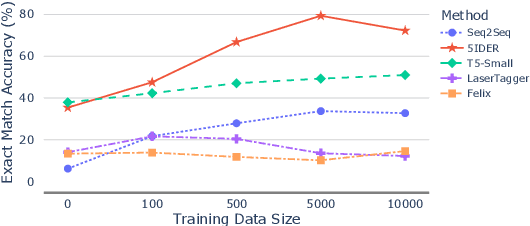
Providing voice assistants the ability to navigate multi-turn conversations is a challenging problem. Handling multi-turn interactions requires the system to understand various conversational use-cases, such as steering, intent carryover, disfluencies, entity carryover, and repair. The complexity of this problem is compounded by the fact that these use-cases mix with each other, often appearing simultaneously in natural language. This work proposes a non-autoregressive query rewriting architecture that can handle not only the five aforementioned tasks, but also complex compositions of these use-cases. We show that our proposed model has competitive single task performance compared to the baseline approach, and even outperforms a fine-tuned T5 model in use-case compositions, despite being 15 times smaller in parameters and 25 times faster in latency.