 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSTEER: Semantic Turn Extension-Expansion Recognition for Voice Assistants
Oct 25, 2023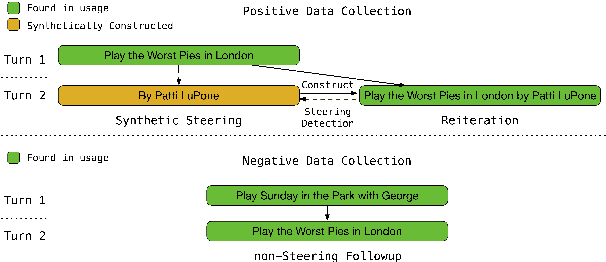
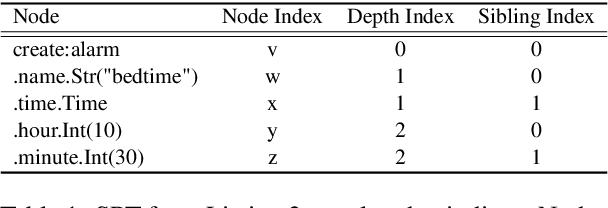
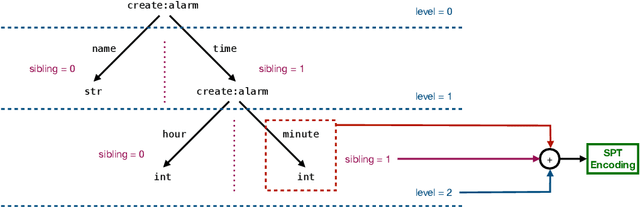

In the context of a voice assistant system, steering refers to the phenomenon in which a user issues a follow-up command attempting to direct or clarify a previous turn. We propose STEER, a steering detection model that predicts whether a follow-up turn is a user's attempt to steer the previous command. Constructing a training dataset for steering use cases poses challenges due to the cold-start problem. To overcome this, we developed heuristic rules to sample opt-in usage data, approximating positive and negative samples without any annotation. Our experimental results show promising performance in identifying steering intent, with over 95% accuracy on our sampled data. Moreover, STEER, in conjunction with our sampling strategy, aligns effectively with real-world steering scenarios, as evidenced by its strong zero-shot performance on a human-graded evaluation set. In addition to relying solely on user transcripts as input, we introduce STEER+, an enhanced version of the model. STEER+ utilizes a semantic parse tree to provide more context on out-of-vocabulary words, such as named entities that often occur at the sentence boundary. This further improves model performance, reducing error rate in domains where entities frequently appear, such as messaging. Lastly, we present a data analysis that highlights the improvement in user experience when voice assistants support steering use cases.
Dynamic curriculum learning via data parameters for noise robust keyword spotting
Feb 18, 2021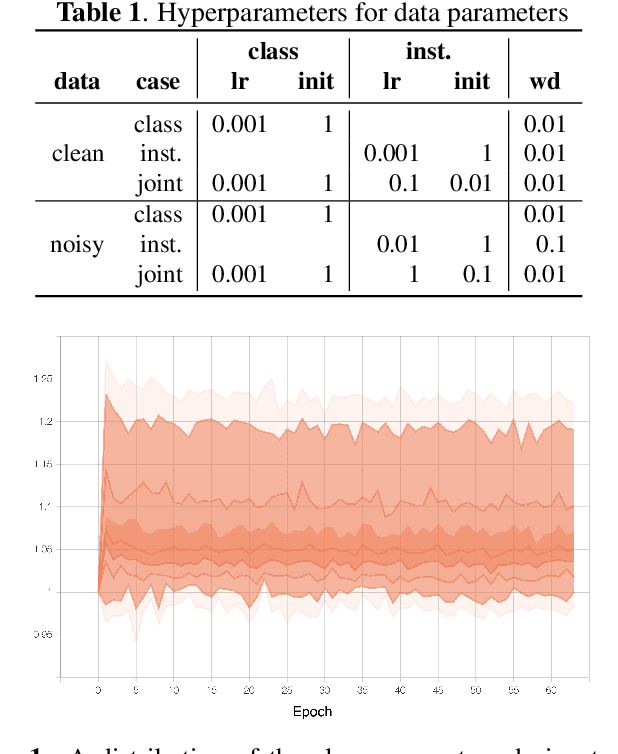
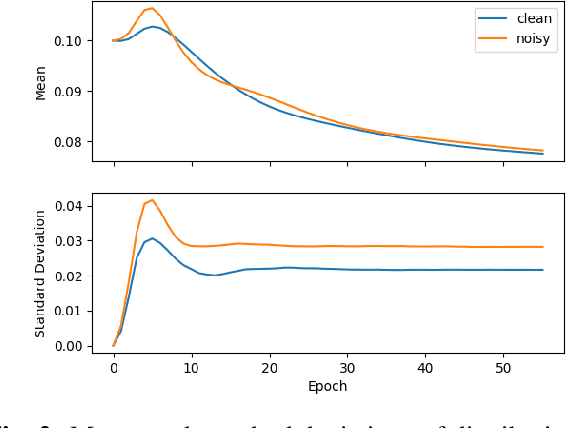
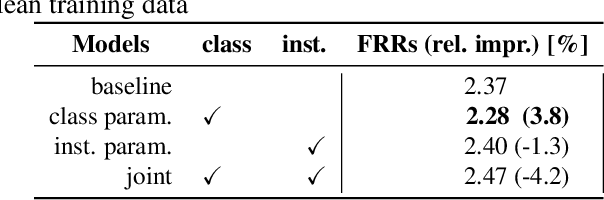

We propose dynamic curriculum learning via data parameters for noise robust keyword spotting. Data parameter learning has recently been introduced for image processing, where weight parameters, so-called data parameters, for target classes and instances are introduced and optimized along with model parameters. The data parameters scale logits and control importance over classes and instances during training, which enables automatic curriculum learning without additional annotations for training data. Similarly, in this paper, we propose using this curriculum learning approach for acoustic modeling, and train an acoustic model on clean and noisy utterances with the data parameters. The proposed approach automatically learns the difficulty of the classes and instances, e.g. due to low speech to noise ratio (SNR), in the gradient descent optimization and performs curriculum learning. This curriculum learning leads to overall improvement of the accuracy of the acoustic model. We evaluate the effectiveness of the proposed approach on a keyword spotting task. Experimental results show 7.7% relative reduction in false reject ratio with the data parameters compared to a baseline model which is simply trained on the multiconditioned dataset.