 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMediSwift: Efficient Sparse Pre-trained Biomedical Language Models
Mar 01, 2024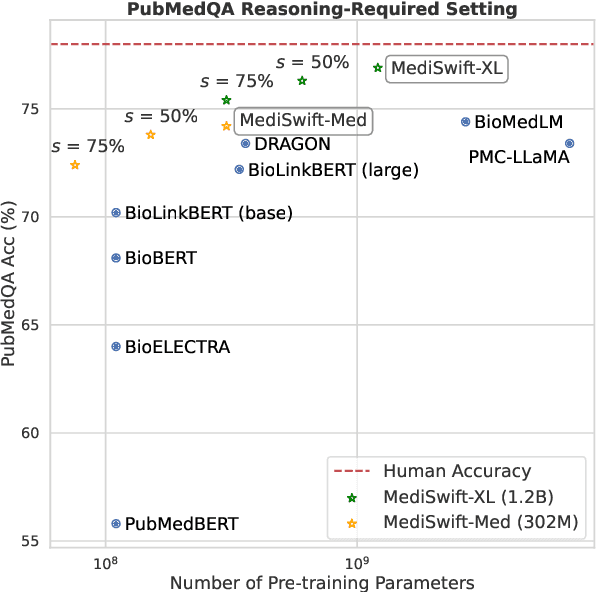
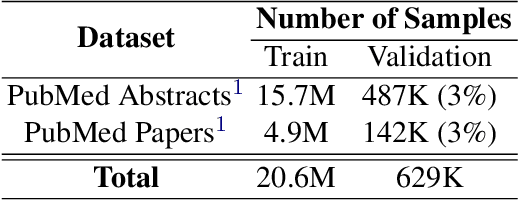
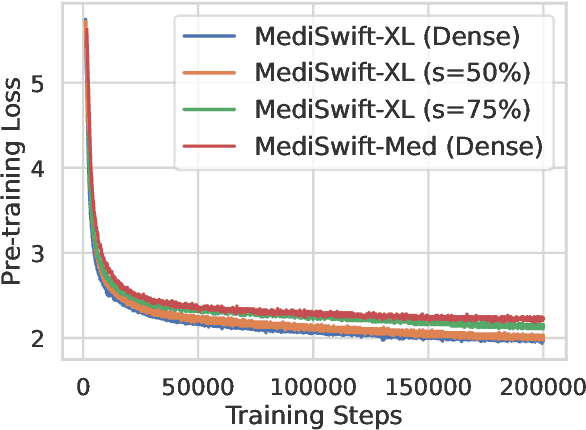
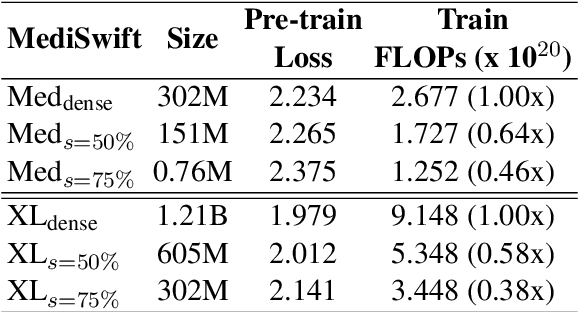
Large language models (LLMs) are typically trained on general source data for various domains, but a recent surge in domain-specific LLMs has shown their potential to outperform general-purpose models in domain-specific tasks (e.g., biomedicine). Although domain-specific pre-training enhances efficiency and leads to smaller models, the computational costs of training these LLMs remain high, posing budgeting challenges. We introduce MediSwift, a suite of biomedical LMs that leverage sparse pre-training on domain-specific biomedical text data. By inducing up to 75% weight sparsity during the pre-training phase, MediSwift achieves a 2-2.5x reduction in training FLOPs. Notably, all sparse pre-training was performed on the Cerebras CS-2 system, which is specifically designed to realize the acceleration benefits from unstructured weight sparsity, thereby significantly enhancing the efficiency of the MediSwift models. Through subsequent dense fine-tuning and strategic soft prompting, MediSwift models outperform existing LLMs up to 7B parameters on biomedical tasks, setting new benchmarks w.r.t efficiency-accuracy on tasks such as PubMedQA. Our results show that sparse pre-training, along with dense fine-tuning and soft prompting, offers an effective method for creating high-performing, computationally efficient models in specialized domains.
Sparse Iso-FLOP Transformations for Maximizing Training Efficiency
Mar 25, 2023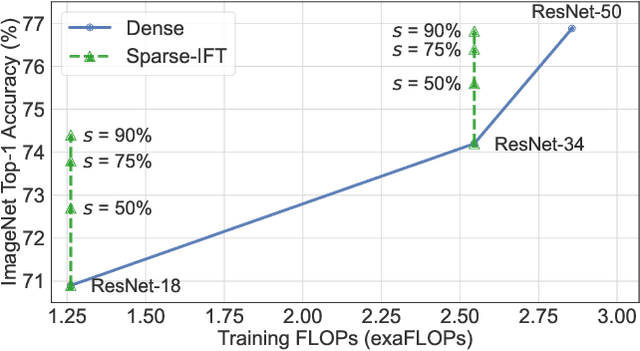
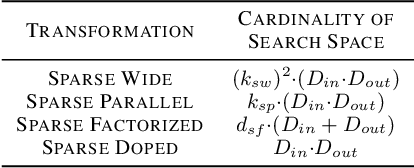
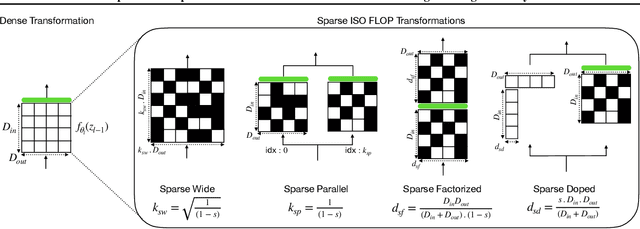
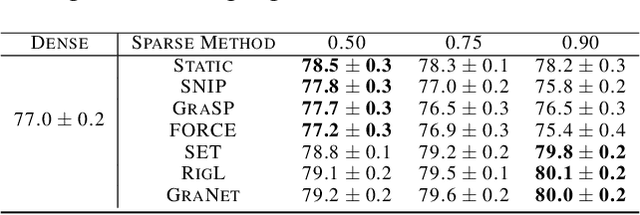
Recent works have explored the use of weight sparsity to improve the training efficiency (test accuracy w.r.t training FLOPs) of deep neural networks (DNNs). These works aim to reduce training FLOPs but training with sparse weights often leads to accuracy loss or requires longer training schedules, making the resulting training efficiency less clear. In contrast, we focus on using sparsity to increase accuracy while using the same FLOPs as the dense model and show training efficiency gains through higher accuracy. In this work, we introduce Sparse-IFT, a family of Sparse Iso-FLOP Transformations which are used as drop-in replacements for dense layers to improve their representational capacity and FLOP efficiency. Each transformation is parameterized by a single hyperparameter (sparsity level) and provides a larger search space to find optimal sparse masks. Without changing any training hyperparameters, replacing dense layers with Sparse-IFT leads to significant improvements across computer vision (CV) and natural language processing (NLP) tasks, including ResNet-18 on ImageNet (+3.5%) and GPT-3 Small on WikiText-103 (-0.4 PPL), both matching larger dense model variants that use 2x or more FLOPs. To our knowledge, this is the first work to demonstrate the use of sparsity for improving the accuracy of dense models via a simple-to-use set of sparse transformations. Code is available at: https://github.com/CerebrasResearch/Sparse-IFT.
SPDF: Sparse Pre-training and Dense Fine-tuning for Large Language Models
Mar 18, 2023

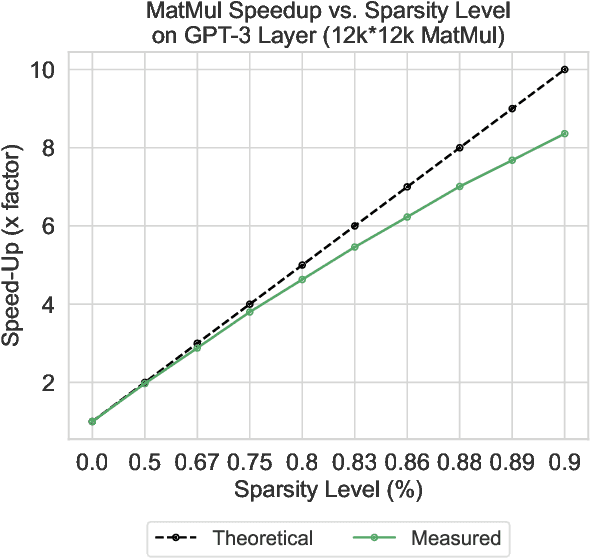
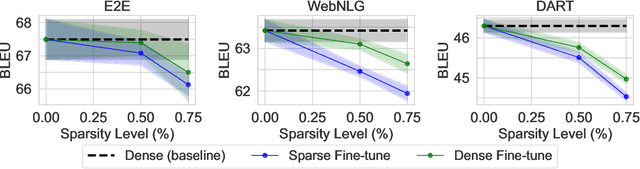
The pre-training and fine-tuning paradigm has contributed to a number of breakthroughs in Natural Language Processing (NLP). Instead of directly training on a downstream task, language models are first pre-trained on large datasets with cross-domain knowledge (e.g., Pile, MassiveText, etc.) and then fine-tuned on task-specific data (e.g., natural language generation, text summarization, etc.). Scaling the model and dataset size has helped improve the performance of LLMs, but unfortunately, this also leads to highly prohibitive computational costs. Pre-training LLMs often require orders of magnitude more FLOPs than fine-tuning and the model capacity often remains the same between the two phases. To achieve training efficiency w.r.t training FLOPs, we propose to decouple the model capacity between the two phases and introduce Sparse Pre-training and Dense Fine-tuning (SPDF). In this work, we show the benefits of using unstructured weight sparsity to train only a subset of weights during pre-training (Sparse Pre-training) and then recover the representational capacity by allowing the zeroed weights to learn (Dense Fine-tuning). We demonstrate that we can induce up to 75% sparsity into a 1.3B parameter GPT-3 XL model resulting in a 2.5x reduction in pre-training FLOPs, without a significant loss in accuracy on the downstream tasks relative to the dense baseline. By rigorously evaluating multiple downstream tasks, we also establish a relationship between sparsity, task complexity, and dataset size. Our work presents a promising direction to train large GPT models at a fraction of the training FLOPs using weight sparsity while retaining the benefits of pre-trained textual representations for downstream tasks.
Instance-Level Task Parameters: A Robust Multi-task Weighting Framework
Jun 11, 2021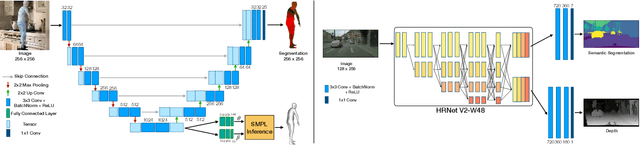

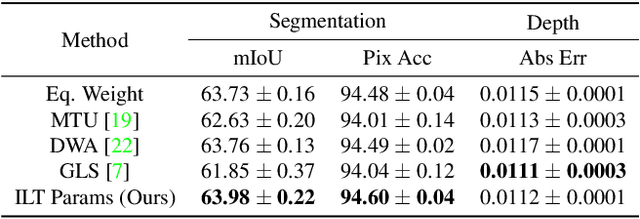

Recent works have shown that deep neural networks benefit from multi-task learning by learning a shared representation across several related tasks. However, performance of such systems depend on relative weighting between various losses involved during training. Prior works on loss weighting schemes assume that instances are equally easy or hard for all tasks. In order to break this assumption, we let the training process dictate the optimal weighting of tasks for every instance in the dataset. More specifically, we equip every instance in the dataset with a set of learnable parameters (instance-level task parameters) where the cardinality is equal to the number of tasks learned by the model. These parameters model the weighting of each task for an instance. They are updated by gradient descent and do not require hand-crafted rules. We conduct extensive experiments on SURREAL and CityScapes datasets, for human shape and pose estimation, depth estimation and semantic segmentation tasks. In these tasks, our approach outperforms recent dynamic loss weighting approaches, e.g. reducing surface estimation errors by 8.97% on SURREAL. When applied to datasets where one or more tasks can have noisy annotations, the proposed method learns to prioritize learning from clean labels for a given task, e.g. reducing surface estimation errors by up to 60%. We also show that we can reliably detect corrupt labels for a given task as a by-product from learned instance-level task parameters.
Training With Data Dependent Dynamic Learning Rates
May 27, 2021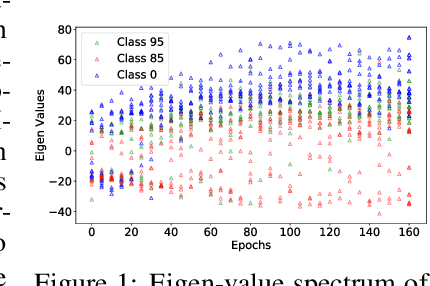
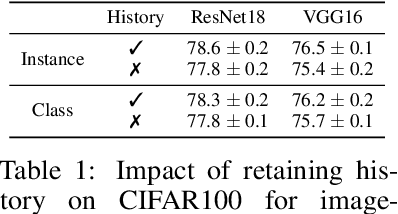
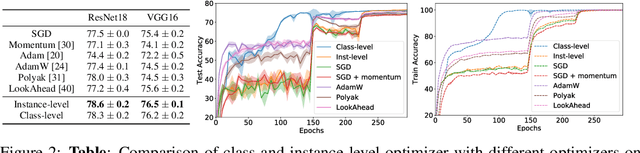

Recently many first and second order variants of SGD have been proposed to facilitate training of Deep Neural Networks (DNNs). A common limitation of these works stem from the fact that they use the same learning rate across all instances present in the dataset. This setting is widely adopted under the assumption that loss functions for each instance are similar in nature, and hence, a common learning rate can be used. In this work, we relax this assumption and propose an optimization framework which accounts for difference in loss function characteristics across instances. More specifically, our optimizer learns a dynamic learning rate for each instance present in the dataset. Learning a dynamic learning rate for each instance allows our optimization framework to focus on different modes of training data during optimization. When applied to an image classification task, across different CNN architectures, learning dynamic learning rates leads to consistent gains over standard optimizers. When applied to a dataset containing corrupt instances, our framework reduces the learning rates on noisy instances, and improves over the state-of-the-art. Finally, we show that our optimization framework can be used for personalization of a machine learning model towards a known targeted data distribution.
Dynamic curriculum learning via data parameters for noise robust keyword spotting
Feb 18, 2021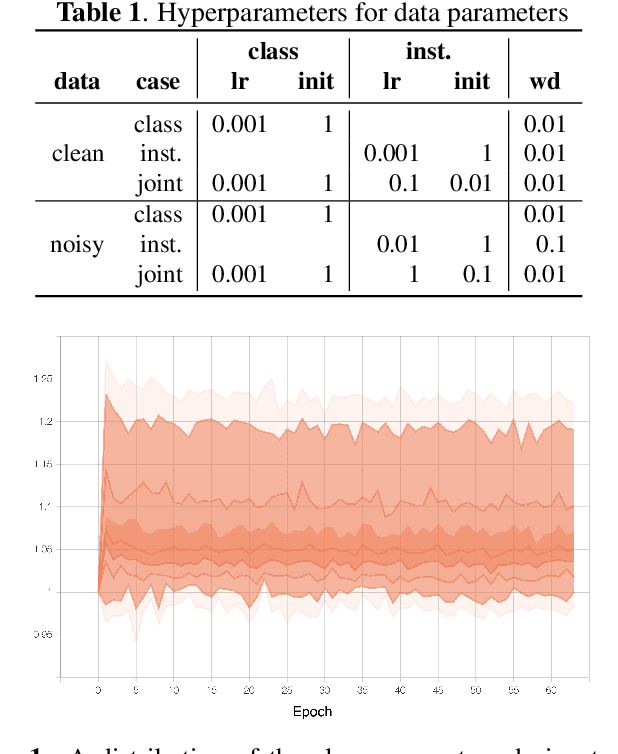
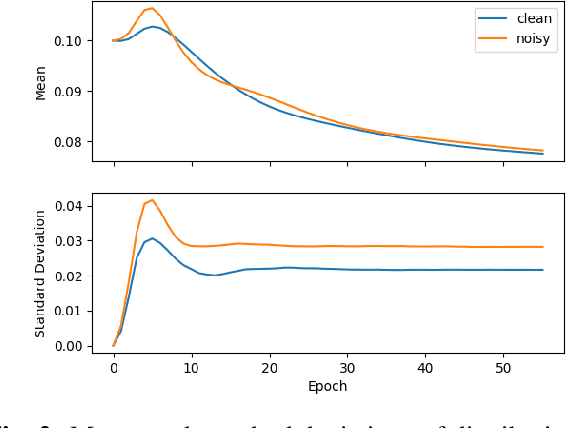
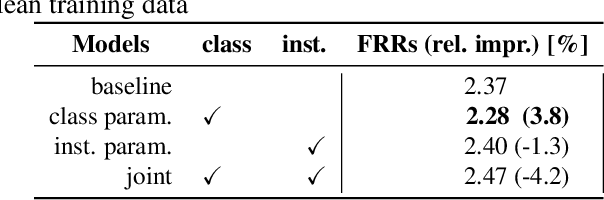

We propose dynamic curriculum learning via data parameters for noise robust keyword spotting. Data parameter learning has recently been introduced for image processing, where weight parameters, so-called data parameters, for target classes and instances are introduced and optimized along with model parameters. The data parameters scale logits and control importance over classes and instances during training, which enables automatic curriculum learning without additional annotations for training data. Similarly, in this paper, we propose using this curriculum learning approach for acoustic modeling, and train an acoustic model on clean and noisy utterances with the data parameters. The proposed approach automatically learns the difficulty of the classes and instances, e.g. due to low speech to noise ratio (SNR), in the gradient descent optimization and performs curriculum learning. This curriculum learning leads to overall improvement of the accuracy of the acoustic model. We evaluate the effectiveness of the proposed approach on a keyword spotting task. Experimental results show 7.7% relative reduction in false reject ratio with the data parameters compared to a baseline model which is simply trained on the multiconditioned dataset.
Learning Soft Labels via Meta Learning
Sep 20, 2020

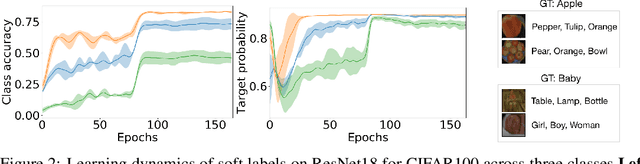

One-hot labels do not represent soft decision boundaries among concepts, and hence, models trained on them are prone to overfitting. Using soft labels as targets provide regularization, but different soft labels might be optimal at different stages of optimization. Also, training with fixed labels in the presence of noisy annotations leads to worse generalization. To address these limitations, we propose a framework, where we treat the labels as learnable parameters, and optimize them along with model parameters. The learned labels continuously adapt themselves to the model's state, thereby providing dynamic regularization. When applied to the task of supervised image-classification, our method leads to consistent gains across different datasets and architectures. For instance, dynamically learned labels improve ResNet18 by 2.1% on CIFAR100. When applied to dataset containing noisy labels, the learned labels correct the annotation mistakes, and improves over state-of-the-art by a significant margin. Finally, we show that learned labels capture semantic relationship between classes, and thereby improve teacher models for the downstream task of distillation.
Learning Unsupervised Visual Grounding Through Semantic Self-Supervision
Sep 05, 2018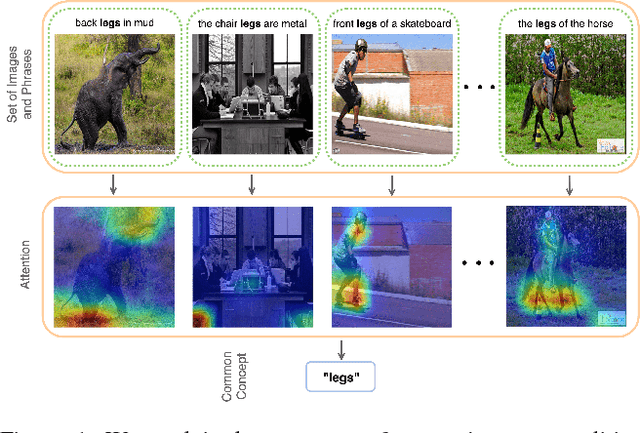
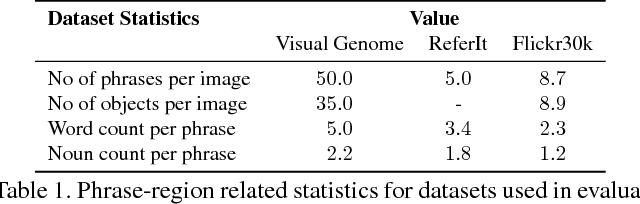
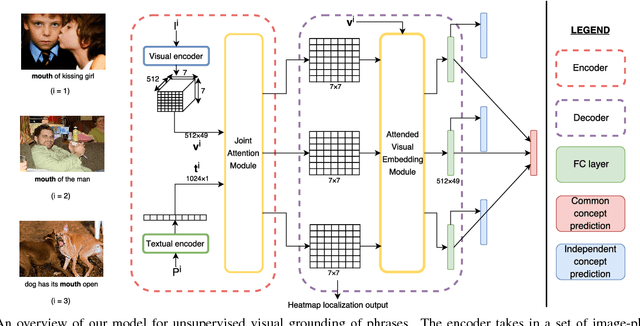
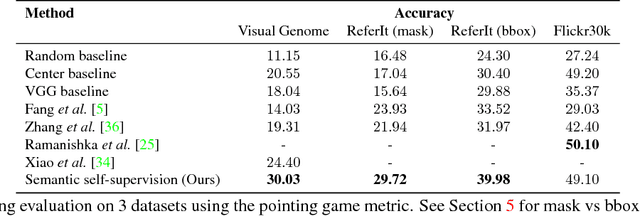
Localizing natural language phrases in images is a challenging problem that requires joint understanding of both the textual and visual modalities. In the unsupervised setting, lack of supervisory signals exacerbate this difficulty. In this paper, we propose a novel framework for unsupervised visual grounding which uses concept learning as a proxy task to obtain self-supervision. The simple intuition behind this idea is to encourage the model to localize to regions which can explain some semantic property in the data, in our case, the property being the presence of a concept in a set of images. We present thorough quantitative and qualitative experiments to demonstrate the efficacy of our approach and show a 5.6% improvement over the current state of the art on Visual Genome dataset, a 5.8% improvement on the ReferItGame dataset and comparable to state-of-art performance on the Flickr30k dataset.
Convolutional Neural Fabrics
Jan 30, 2017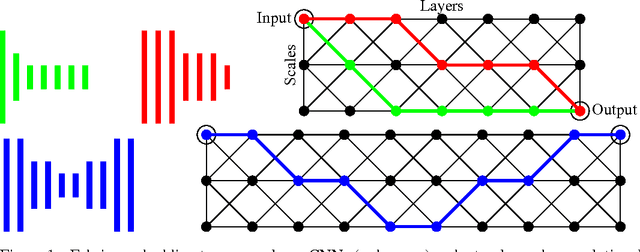

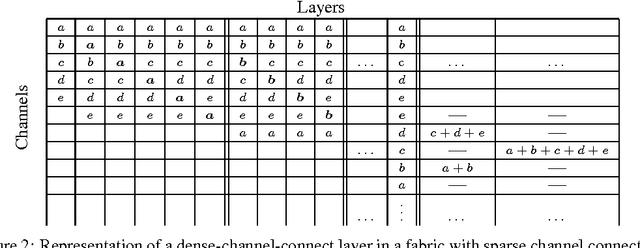
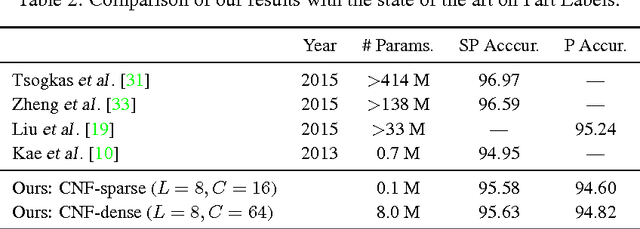
Despite the success of CNNs, selecting the optimal architecture for a given task remains an open problem. Instead of aiming to select a single optimal architecture, we propose a "fabric" that embeds an exponentially large number of architectures. The fabric consists of a 3D trellis that connects response maps at different layers, scales, and channels with a sparse homogeneous local connectivity pattern. The only hyper-parameters of a fabric are the number of channels and layers. While individual architectures can be recovered as paths, the fabric can in addition ensemble all embedded architectures together, sharing their weights where their paths overlap. Parameters can be learned using standard methods based on back-propagation, at a cost that scales linearly in the fabric size. We present benchmark results competitive with the state of the art for image classification on MNIST and CIFAR10, and for semantic segmentation on the Part Labels dataset.