 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Soft Labels via Meta Learning
Paper and Code
Sep 20, 2020

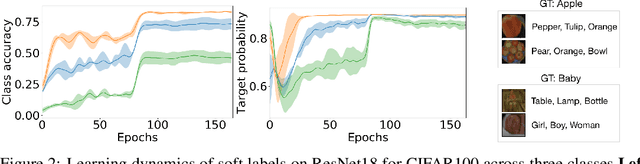

One-hot labels do not represent soft decision boundaries among concepts, and hence, models trained on them are prone to overfitting. Using soft labels as targets provide regularization, but different soft labels might be optimal at different stages of optimization. Also, training with fixed labels in the presence of noisy annotations leads to worse generalization. To address these limitations, we propose a framework, where we treat the labels as learnable parameters, and optimize them along with model parameters. The learned labels continuously adapt themselves to the model's state, thereby providing dynamic regularization. When applied to the task of supervised image-classification, our method leads to consistent gains across different datasets and architectures. For instance, dynamically learned labels improve ResNet18 by 2.1% on CIFAR100. When applied to dataset containing noisy labels, the learned labels correct the annotation mistakes, and improves over state-of-the-art by a significant margin. Finally, we show that learned labels capture semantic relationship between classes, and thereby improve teacher models for the downstream task of distillation.