 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGemini: A Family of Highly Capable Multimodal Models
Dec 19, 2023This report introduces a new family of multimodal models, Gemini, that exhibit remarkable capabilities across image, audio, video, and text understanding. The Gemini family consists of Ultra, Pro, and Nano sizes, suitable for applications ranging from complex reasoning tasks to on-device memory-constrained use-cases. Evaluation on a broad range of benchmarks shows that our most-capable Gemini Ultra model advances the state of the art in 30 of 32 of these benchmarks - notably being the first model to achieve human-expert performance on the well-studied exam benchmark MMLU, and improving the state of the art in every one of the 20 multimodal benchmarks we examined. We believe that the new capabilities of Gemini models in cross-modal reasoning and language understanding will enable a wide variety of use cases and we discuss our approach toward deploying them responsibly to users.
Fix your Models by Fixing your Datasets
Dec 15, 2021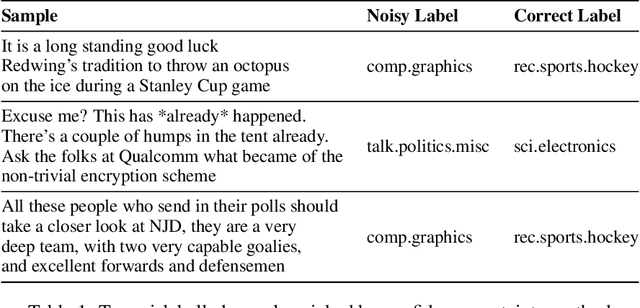

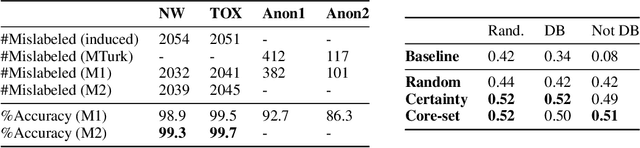
The quality of underlying training data is very crucial for building performant machine learning models with wider generalizabilty. However, current machine learning (ML) tools lack streamlined processes for improving the data quality. So, getting data quality insights and iteratively pruning the errors to obtain a dataset which is most representative of downstream use cases is still an ad-hoc manual process. Our work addresses this data tooling gap, required to build improved ML workflows purely through data-centric techniques. More specifically, we introduce a systematic framework for (1) finding noisy or mislabelled samples in the dataset and, (2) identifying the most informative samples, which when included in training would provide maximal model performance lift. We demonstrate the efficacy of our framework on public as well as private enterprise datasets of two Fortune 500 companies, and are confident this work will form the basis for ML teams to perform more intelligent data discovery and pruning.
Namesakes: Ambiguously Named Entities from Wikipedia and News
Nov 22, 2021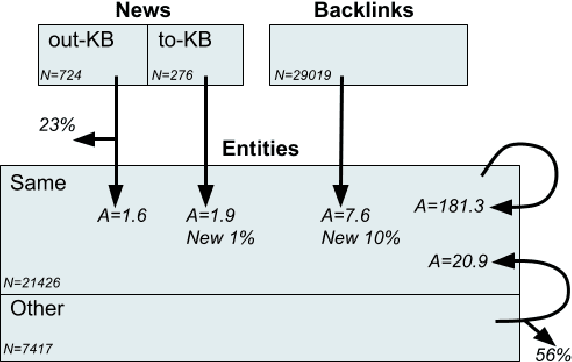



We present Namesakes, a dataset of ambiguously named entities obtained from English-language Wikipedia and news articles. It consists of 58862 mentions of 4148 unique entities and their namesakes: 1000 mentions from news, 28843 from Wikipedia articles about the entity, and 29019 Wikipedia backlink mentions. Namesakes should be helpful in establishing challenging benchmarks for the task of named entity linking (NEL).
Training With Data Dependent Dynamic Learning Rates
May 27, 2021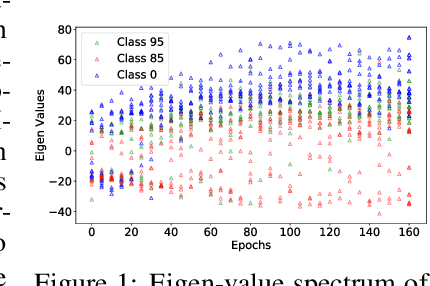
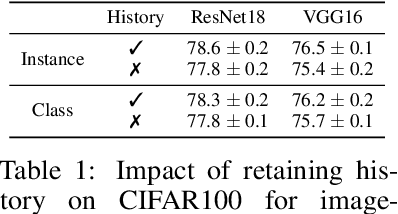
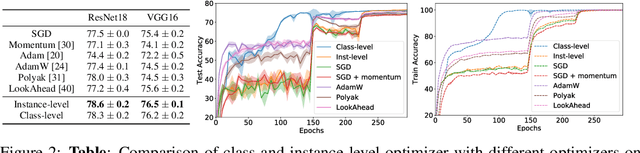

Recently many first and second order variants of SGD have been proposed to facilitate training of Deep Neural Networks (DNNs). A common limitation of these works stem from the fact that they use the same learning rate across all instances present in the dataset. This setting is widely adopted under the assumption that loss functions for each instance are similar in nature, and hence, a common learning rate can be used. In this work, we relax this assumption and propose an optimization framework which accounts for difference in loss function characteristics across instances. More specifically, our optimizer learns a dynamic learning rate for each instance present in the dataset. Learning a dynamic learning rate for each instance allows our optimization framework to focus on different modes of training data during optimization. When applied to an image classification task, across different CNN architectures, learning dynamic learning rates leads to consistent gains over standard optimizers. When applied to a dataset containing corrupt instances, our framework reduces the learning rates on noisy instances, and improves over the state-of-the-art. Finally, we show that our optimization framework can be used for personalization of a machine learning model towards a known targeted data distribution.
Learning Soft Labels via Meta Learning
Sep 20, 2020

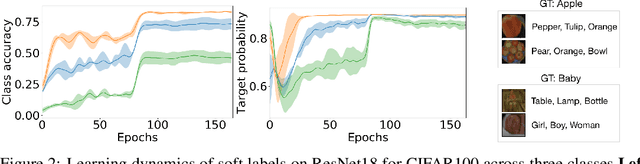

One-hot labels do not represent soft decision boundaries among concepts, and hence, models trained on them are prone to overfitting. Using soft labels as targets provide regularization, but different soft labels might be optimal at different stages of optimization. Also, training with fixed labels in the presence of noisy annotations leads to worse generalization. To address these limitations, we propose a framework, where we treat the labels as learnable parameters, and optimize them along with model parameters. The learned labels continuously adapt themselves to the model's state, thereby providing dynamic regularization. When applied to the task of supervised image-classification, our method leads to consistent gains across different datasets and architectures. For instance, dynamically learned labels improve ResNet18 by 2.1% on CIFAR100. When applied to dataset containing noisy labels, the learned labels correct the annotation mistakes, and improves over state-of-the-art by a significant margin. Finally, we show that learned labels capture semantic relationship between classes, and thereby improve teacher models for the downstream task of distillation.
Measuring Bias in Contextualized Word Representations
Jun 18, 2019

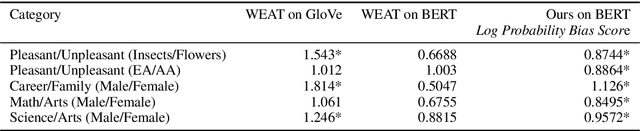
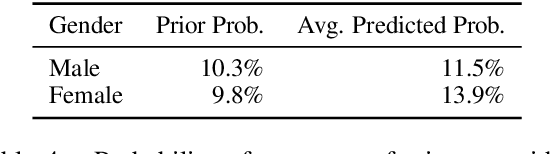
Contextual word embeddings such as BERT have achieved state of the art performance in numerous NLP tasks. Since they are optimized to capture the statistical properties of training data, they tend to pick up on and amplify social stereotypes present in the data as well. In this study, we (1)~propose a template-based method to quantify bias in BERT; (2)~show that this method obtains more consistent results in capturing social biases than the traditional cosine based method; and (3)~conduct a case study, evaluating gender bias in a downstream task of Gender Pronoun Resolution. Although our case study focuses on gender bias, the proposed technique is generalizable to unveiling other biases, including in multiclass settings, such as racial and religious biases.
The ARIEL-CMU Systems for LoReHLT18
Feb 24, 2019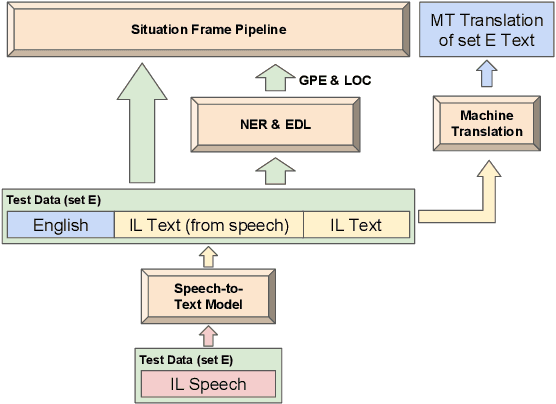
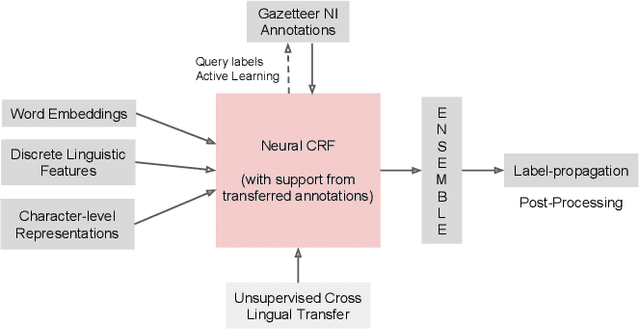
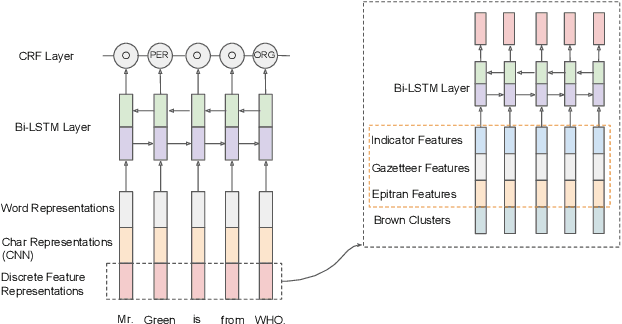
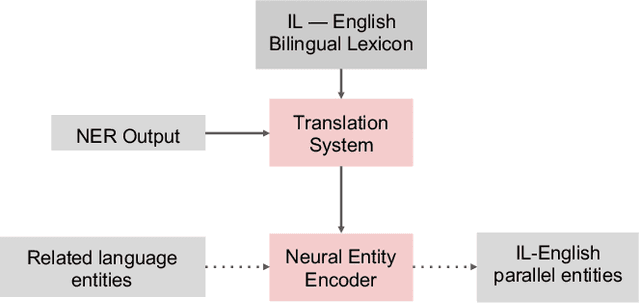
This paper describes the ARIEL-CMU submissions to the Low Resource Human Language Technologies (LoReHLT) 2018 evaluations for the tasks Machine Translation (MT), Entity Discovery and Linking (EDL), and detection of Situation Frames in Text and Speech (SF Text and Speech).