 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePreserving Multilingual Quality While Tuning Query Encoder on English Only
Jul 01, 2024A dense passage retrieval system can serve as the initial stages of information retrieval, selecting the most relevant text passages for downstream tasks. In this work we conducted experiments with the goal of finding how much the quality of a multilingual retrieval could be degraded if the query part of a dual encoder is tuned on an English-only dataset (assuming scarcity of cross-lingual samples for the targeted domain or task). Specifically, starting with a high quality multilingual embedding model, we observe that an English-only tuning may not only preserve the original quality of the multilingual retrieval, but even improve it.
How to Discern Important Urgent News?
Feb 15, 2024
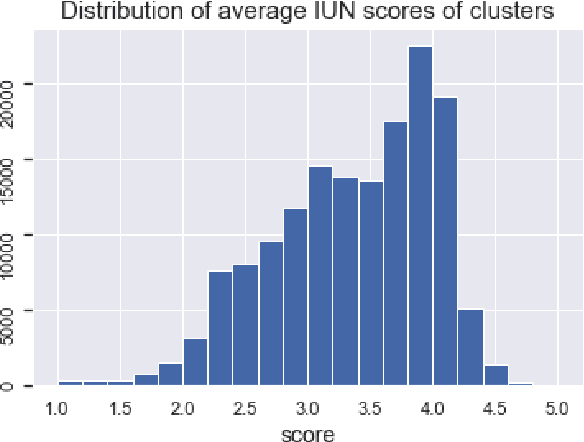
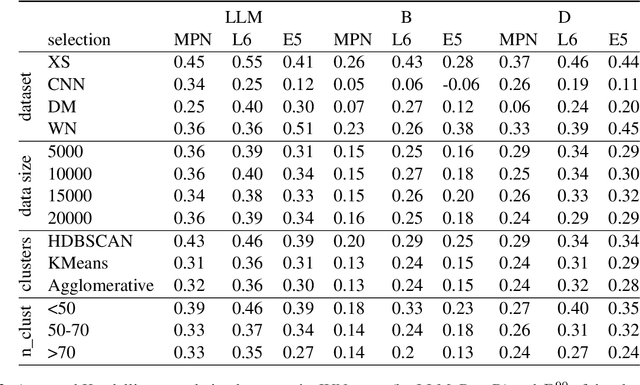

We found that a simple property of clusters in a clustered dataset of news correlate strongly with importance and urgency of news (IUN) as assessed by LLM. We verified our finding across different news datasets, dataset sizes, clustering algorithms and embeddings. The found correlation should allow using clustering (as an alternative to LLM) for identifying the most important urgent news, or for filtering out unimportant articles.
Linear Cross-Lingual Mapping of Sentence Embeddings
May 23, 2023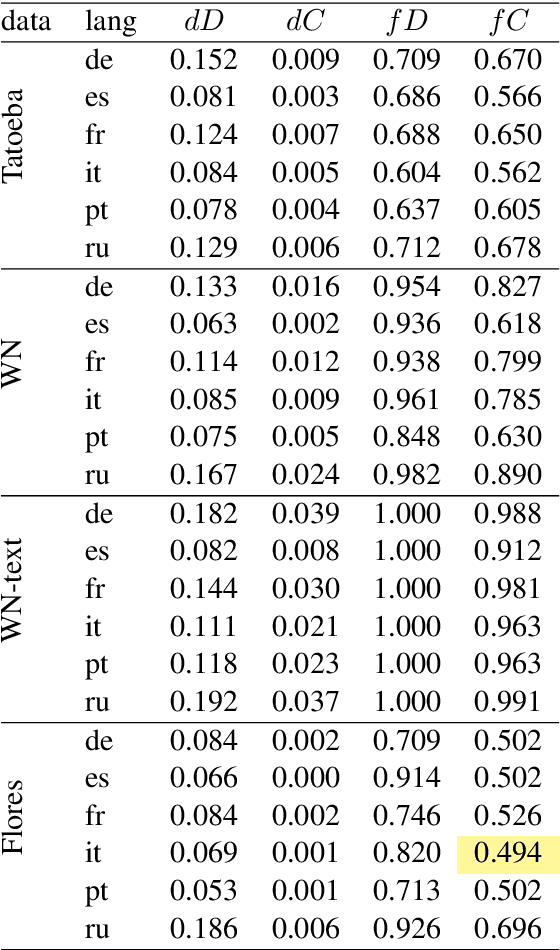


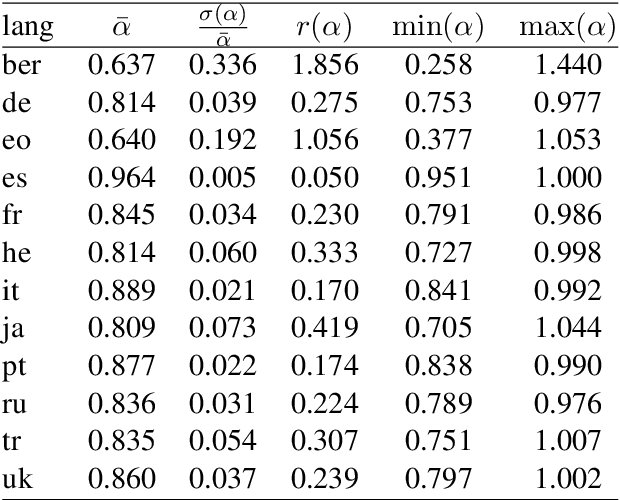
Semantics of a sentence is defined with much less ambiguity than semantics of a single word, and it should be better preserved by translation to another language. If multilingual sentence embeddings intend to represent sentence semantics, then the similarity between embeddings of any two sentences must be invariant with respect to translation. Based on this suggestion, we consider a simple linear cross-lingual mapping as a possible improvement of the multilingual embeddings. We also consider deviation from orthogonality conditions as a measure of deficiency of the embeddings.
Neural Embeddings for Text
Aug 17, 2022
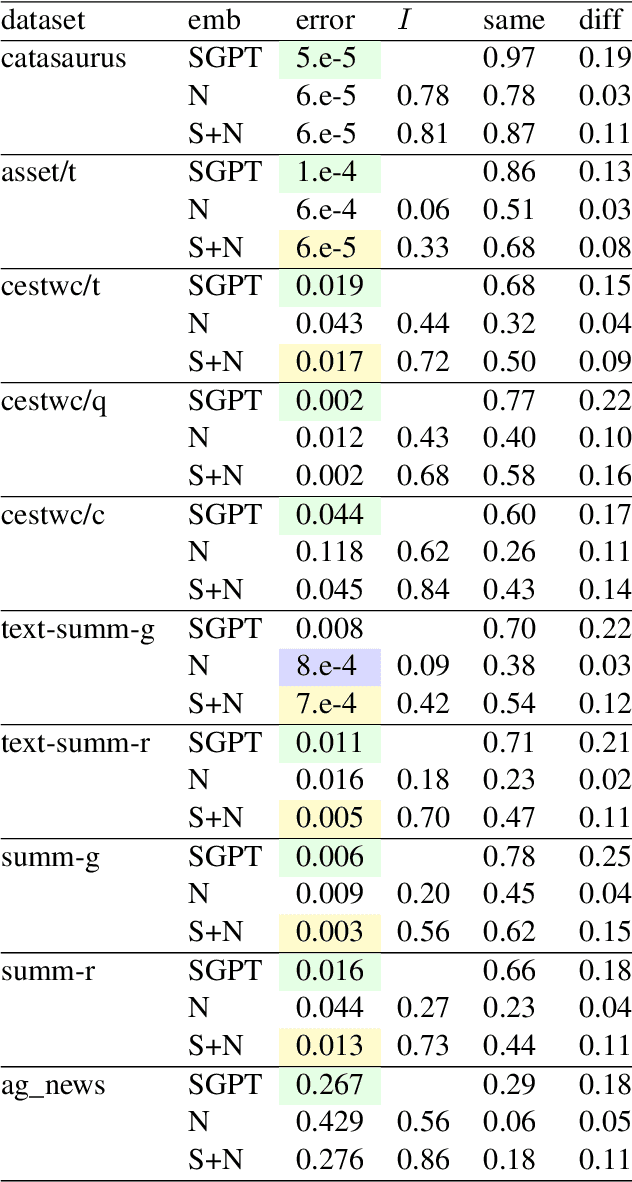


We propose a new kind of embedding for natural language text that deeply represents semantic meaning. Standard text embeddings use the vector output of a pretrained language model. In our method, we let a language model learn from the text and then literally pick its brain, taking the actual weights of the model's neurons to generate a vector. We call this representation of the text a neural embedding. The technique may generalize beyond text and language models, but we first explore its properties for natural language processing. We compare neural embeddings with GPT sentence (SGPT) embeddings on several datasets. We observe that neural embeddings achieve comparable performance with a far smaller model, and the errors are different.
BabyBear: Cheap inference triage for expensive language models
May 24, 2022
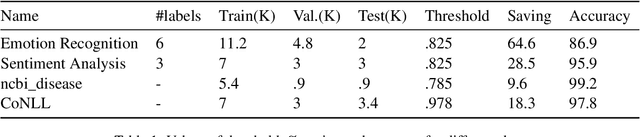
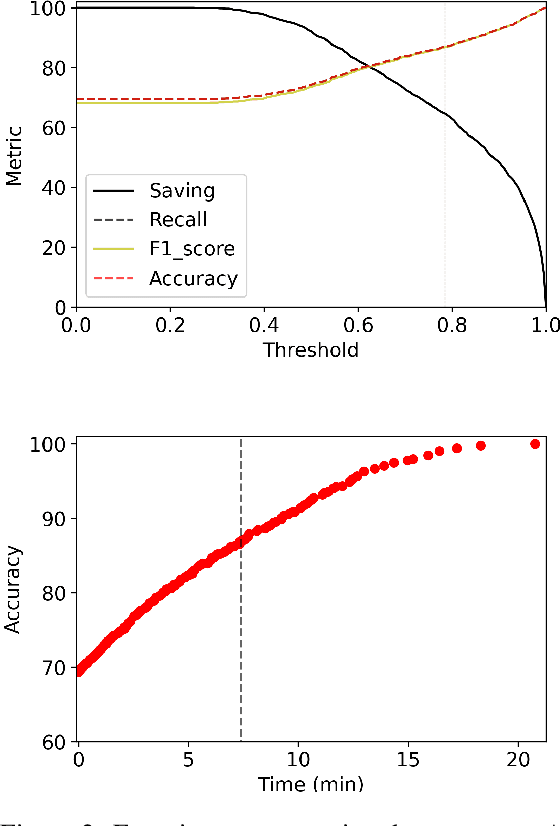
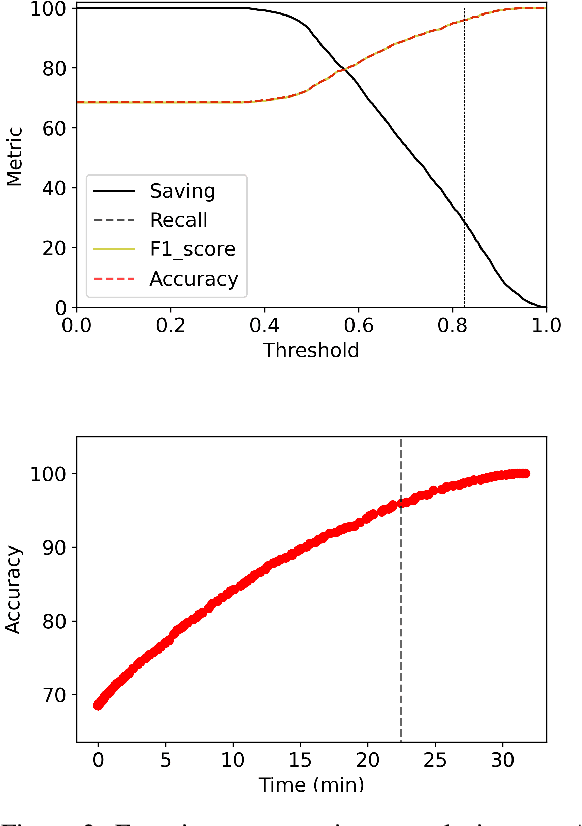
Transformer language models provide superior accuracy over previous models but they are computationally and environmentally expensive. Borrowing the concept of model cascading from computer vision, we introduce BabyBear, a framework for cascading models for natural language processing (NLP) tasks to minimize cost. The core strategy is inference triage, exiting early when the least expensive model in the cascade achieves a sufficiently high-confidence prediction. We test BabyBear on several open source data sets related to document classification and entity recognition. We find that for common NLP tasks a high proportion of the inference load can be accomplished with cheap, fast models that have learned by observing a deep learning model. This allows us to reduce the compute cost of large-scale classification jobs by more than 50% while retaining overall accuracy. For named entity recognition, we save 33% of the deep learning compute while maintaining an F1 score higher than 95% on the CoNLL benchmark.
Named Entity Linking on Namesakes
May 21, 2022
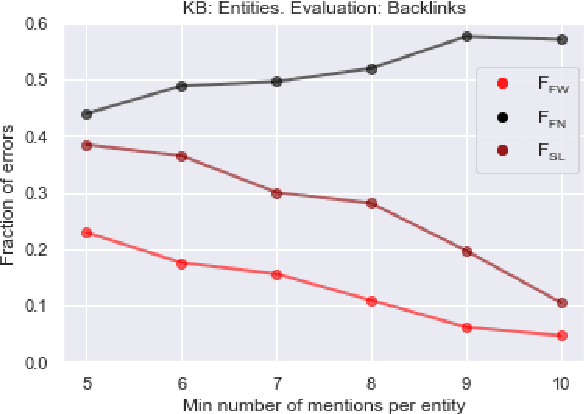

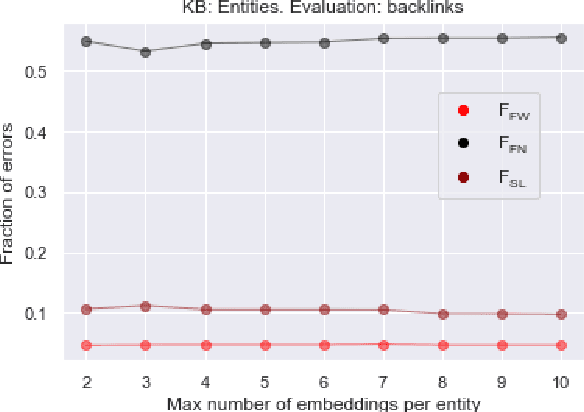
We propose a simple and practical method of named entity linking (NEL), and explore its features and performance on a dataset of ambiguous named entities - Namesakes. We represent knowledge base (KB) entity by a set of embeddings. Our observations suggest that it is reasonable to keep a limited number of such embeddings, and that the number of mentions required to create a KB entity is important. We show that representations of entities in the knowledge base (KB) can be adjusted using only KB data, and the adjustment improves NEL performance.
Consistency and Coherence from Points of Contextual Similarity
Jan 07, 2022

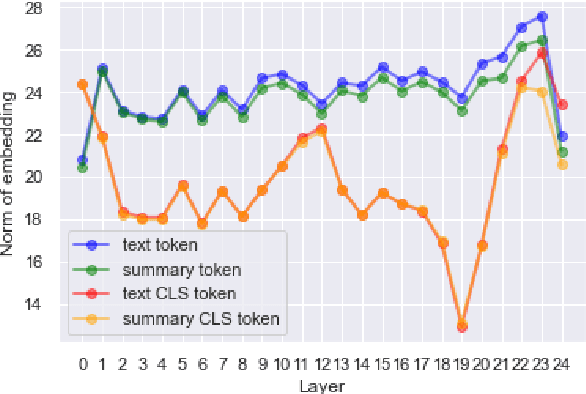
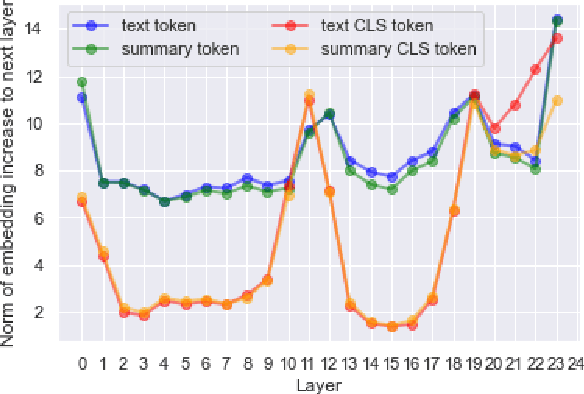
Factual consistency is one of important summary evaluation dimensions, especially as summary generation becomes more fluent and coherent. The ESTIME measure, recently proposed specifically for factual consistency, achieves high correlations with human expert scores both for consistency and fluency, while in principle being restricted to evaluating such text-summary pairs that have high dictionary overlap. This is not a problem for current styles of summarization, but it may become an obstacle for future summarization systems, or for evaluating arbitrary claims against the text. In this work we generalize the method, and make a variant of the measure applicable to any text-summary pairs. As ESTIME uses points of contextual similarity, it provides insights into usefulness of information taken from different BERT layers. We observe that useful information exists in almost all of the layers except the several lowest ones. For consistency and fluency - qualities focused on local text details - the most useful layers are close to the top (but not at the top); for coherence and relevance we found a more complicated and interesting picture.
Namesakes: Ambiguously Named Entities from Wikipedia and News
Nov 22, 2021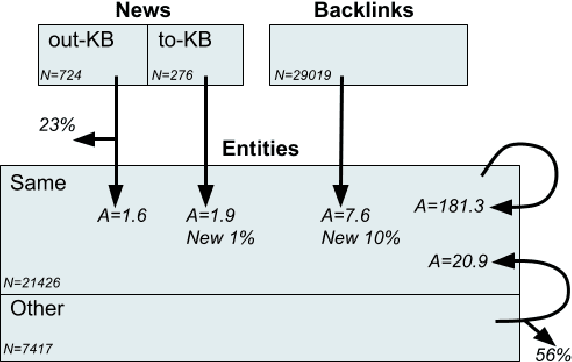



We present Namesakes, a dataset of ambiguously named entities obtained from English-language Wikipedia and news articles. It consists of 58862 mentions of 4148 unique entities and their namesakes: 1000 mentions from news, 28843 from Wikipedia articles about the entity, and 29019 Wikipedia backlink mentions. Namesakes should be helpful in establishing challenging benchmarks for the task of named entity linking (NEL).
Does Summary Evaluation Survive Translation to Other Languages?
Sep 16, 2021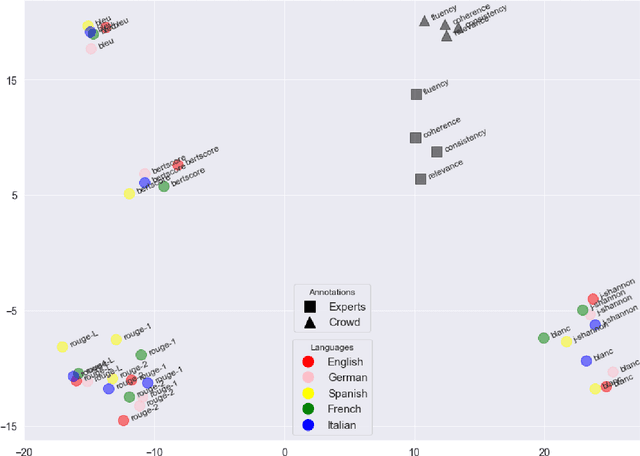
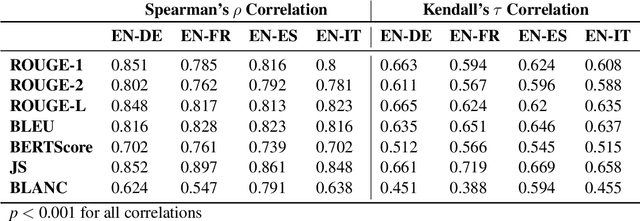
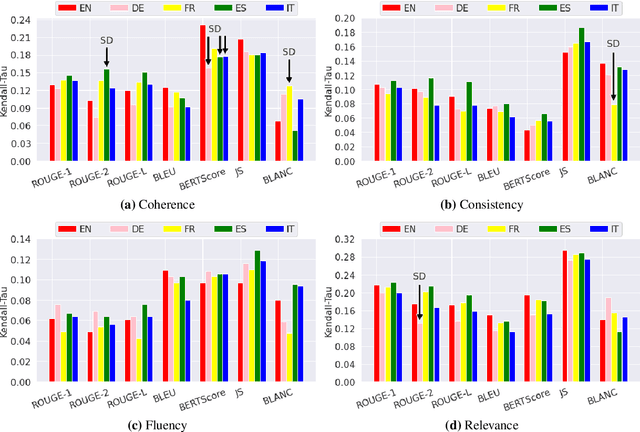
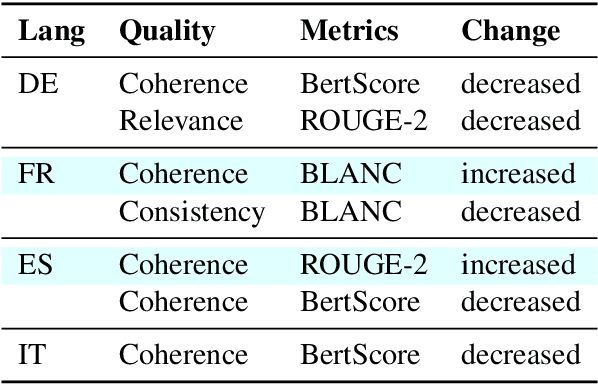
The creation of a large summarization quality dataset is a considerable, expensive, time-consuming effort, requiring careful planning and setup. It includes producing human-written and machine-generated summaries and evaluation of the summaries by humans, preferably by linguistic experts, and by automatic evaluation tools. If such effort is made in one language, it would be beneficial to be able to use it in other languages. To investigate how much we can trust the translation of such dataset without repeating human annotations in another language, we translated an existing English summarization dataset, SummEval dataset, to four different languages and analyzed the scores from the automatic evaluation metrics in translated languages, as well as their correlation with human annotations in the source language. Our results reveal that although translation changes the absolute value of automatic scores, the scores keep the same rank order and approximately the same correlations with human annotations.
Towards Human-Free Automatic Quality Evaluation of German Summarization
May 13, 2021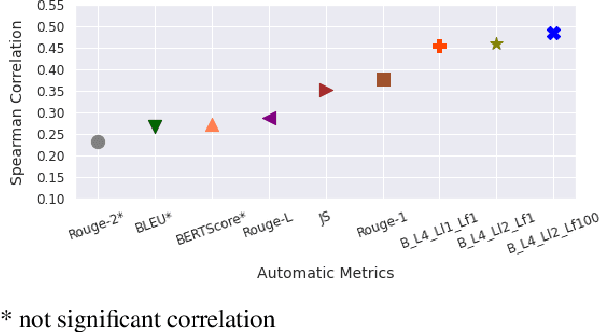

Evaluating large summarization corpora using humans has proven to be expensive from both the organizational and the financial perspective. Therefore, many automatic evaluation metrics have been developed to measure the summarization quality in a fast and reproducible way. However, most of the metrics still rely on humans and need gold standard summaries generated by linguistic experts. Since BLANC does not require golden summaries and supposedly can use any underlying language model, we consider its application to the evaluation of summarization in German. This work demonstrates how to adjust the BLANC metric to a language other than English. We compare BLANC scores with the crowd and expert ratings, as well as with commonly used automatic metrics on a German summarization data set. Our results show that BLANC in German is especially good in evaluating informativeness.