 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDoes Summary Evaluation Survive Translation to Other Languages?
Sep 16, 2021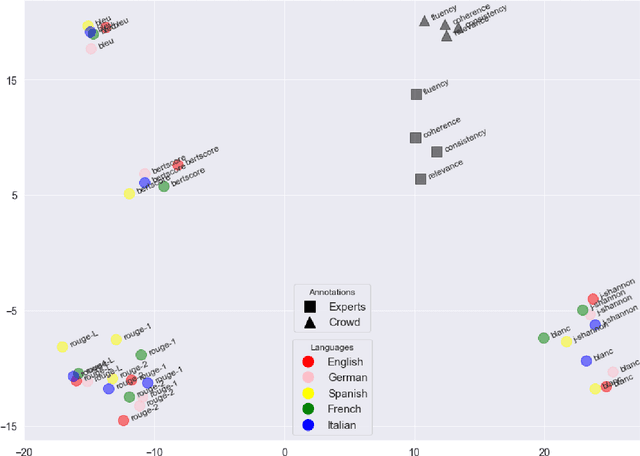
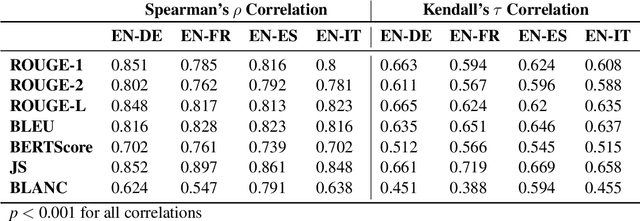
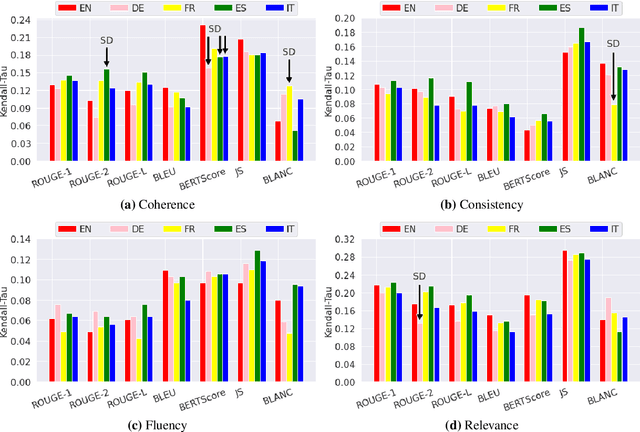
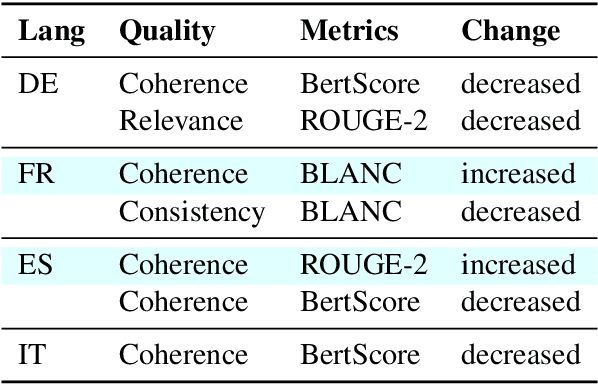
The creation of a large summarization quality dataset is a considerable, expensive, time-consuming effort, requiring careful planning and setup. It includes producing human-written and machine-generated summaries and evaluation of the summaries by humans, preferably by linguistic experts, and by automatic evaluation tools. If such effort is made in one language, it would be beneficial to be able to use it in other languages. To investigate how much we can trust the translation of such dataset without repeating human annotations in another language, we translated an existing English summarization dataset, SummEval dataset, to four different languages and analyzed the scores from the automatic evaluation metrics in translated languages, as well as their correlation with human annotations in the source language. Our results reveal that although translation changes the absolute value of automatic scores, the scores keep the same rank order and approximately the same correlations with human annotations.
Towards Human-Free Automatic Quality Evaluation of German Summarization
May 13, 2021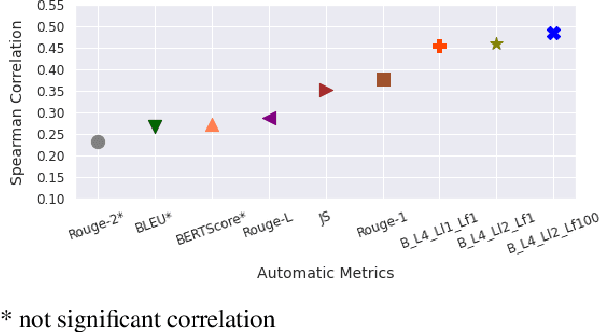

Evaluating large summarization corpora using humans has proven to be expensive from both the organizational and the financial perspective. Therefore, many automatic evaluation metrics have been developed to measure the summarization quality in a fast and reproducible way. However, most of the metrics still rely on humans and need gold standard summaries generated by linguistic experts. Since BLANC does not require golden summaries and supposedly can use any underlying language model, we consider its application to the evaluation of summarization in German. This work demonstrates how to adjust the BLANC metric to a language other than English. We compare BLANC scores with the crowd and expert ratings, as well as with commonly used automatic metrics on a German summarization data set. Our results show that BLANC in German is especially good in evaluating informativeness.