 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSPDF: Sparse Pre-training and Dense Fine-tuning for Large Language Models
Mar 18, 2023

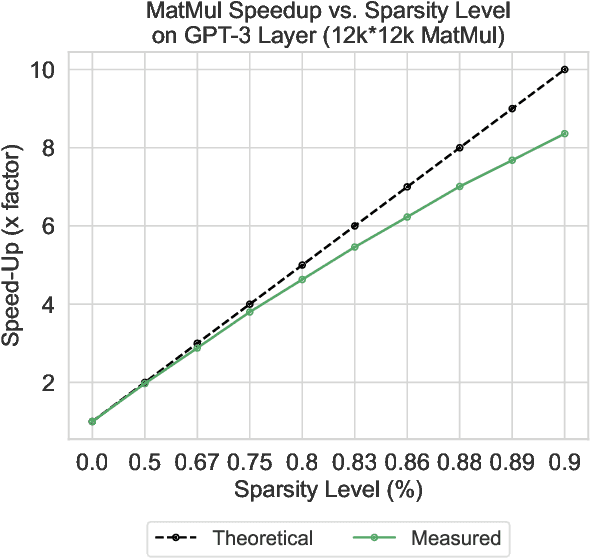
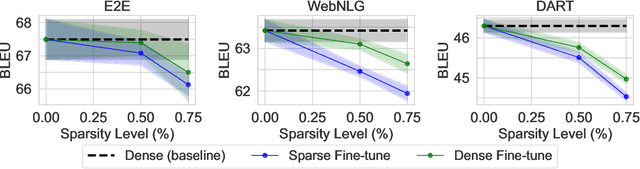
The pre-training and fine-tuning paradigm has contributed to a number of breakthroughs in Natural Language Processing (NLP). Instead of directly training on a downstream task, language models are first pre-trained on large datasets with cross-domain knowledge (e.g., Pile, MassiveText, etc.) and then fine-tuned on task-specific data (e.g., natural language generation, text summarization, etc.). Scaling the model and dataset size has helped improve the performance of LLMs, but unfortunately, this also leads to highly prohibitive computational costs. Pre-training LLMs often require orders of magnitude more FLOPs than fine-tuning and the model capacity often remains the same between the two phases. To achieve training efficiency w.r.t training FLOPs, we propose to decouple the model capacity between the two phases and introduce Sparse Pre-training and Dense Fine-tuning (SPDF). In this work, we show the benefits of using unstructured weight sparsity to train only a subset of weights during pre-training (Sparse Pre-training) and then recover the representational capacity by allowing the zeroed weights to learn (Dense Fine-tuning). We demonstrate that we can induce up to 75% sparsity into a 1.3B parameter GPT-3 XL model resulting in a 2.5x reduction in pre-training FLOPs, without a significant loss in accuracy on the downstream tasks relative to the dense baseline. By rigorously evaluating multiple downstream tasks, we also establish a relationship between sparsity, task complexity, and dataset size. Our work presents a promising direction to train large GPT models at a fraction of the training FLOPs using weight sparsity while retaining the benefits of pre-trained textual representations for downstream tasks.
RevBiFPN: The Fully Reversible Bidirectional Feature Pyramid Network
Jun 28, 2022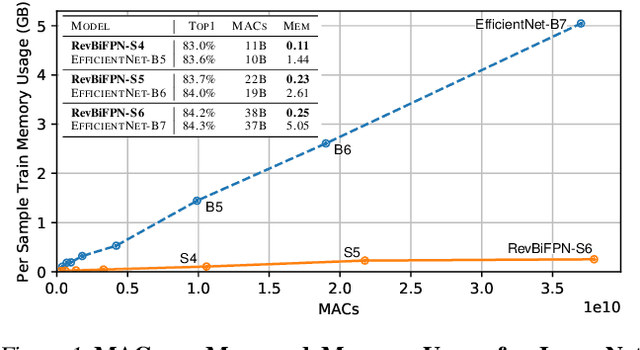
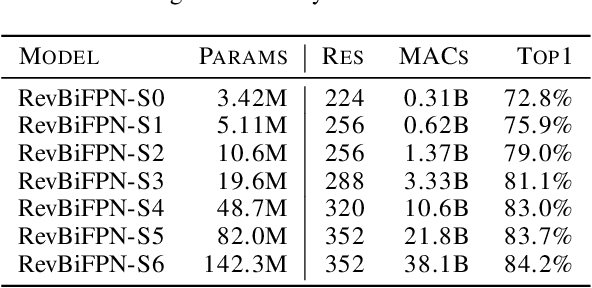
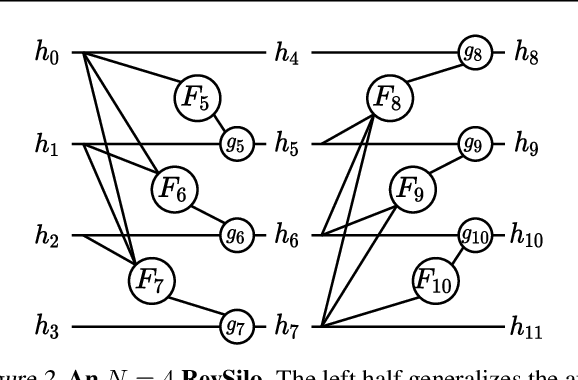
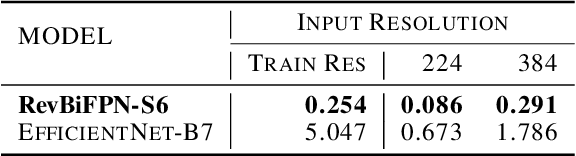
This work introduces the RevSilo, the first reversible module for bidirectional multi-scale feature fusion. Like other reversible methods, RevSilo eliminates the need to store hidden activations by recomputing them. Existing reversible methods, however, do not apply to multi-scale feature fusion and are therefore not applicable to a large class of networks. Bidirectional multi-scale feature fusion promotes local and global coherence and has become a de facto design principle for networks targeting spatially sensitive tasks e.g. HRNet and EfficientDet. When paired with high-resolution inputs, these networks achieve state-of-the-art results across various computer vision tasks, but training them requires substantial accelerator memory for saving large, multi-resolution activations. These memory requirements cap network size and limit progress. Using reversible recomputation, the RevSilo alleviates memory issues while still operating across resolution scales. Stacking RevSilos, we create RevBiFPN, a fully reversible bidirectional feature pyramid network. For classification, RevBiFPN is competitive with networks such as EfficientNet while using up to 19.8x lesser training memory. When fine-tuned on COCO, RevBiFPN provides up to a 2.5% boost in AP over HRNet using fewer MACs and a 2.4x reduction in training-time memory.
Training With Data Dependent Dynamic Learning Rates
May 27, 2021
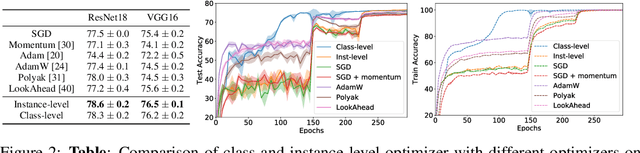

Recently many first and second order variants of SGD have been proposed to facilitate training of Deep Neural Networks (DNNs). A common limitation of these works stem from the fact that they use the same learning rate across all instances present in the dataset. This setting is widely adopted under the assumption that loss functions for each instance are similar in nature, and hence, a common learning rate can be used. In this work, we relax this assumption and propose an optimization framework which accounts for difference in loss function characteristics across instances. More specifically, our optimizer learns a dynamic learning rate for each instance present in the dataset. Learning a dynamic learning rate for each instance allows our optimization framework to focus on different modes of training data during optimization. When applied to an image classification task, across different CNN architectures, learning dynamic learning rates leads to consistent gains over standard optimizers. When applied to a dataset containing corrupt instances, our framework reduces the learning rates on noisy instances, and improves over the state-of-the-art. Finally, we show that our optimization framework can be used for personalization of a machine learning model towards a known targeted data distribution.
Memory Efficient 3D U-Net with Reversible Mobile Inverted Bottlenecks for Brain Tumor Segmentation
Apr 21, 2021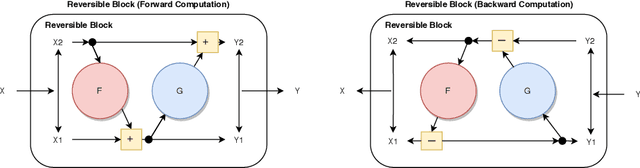

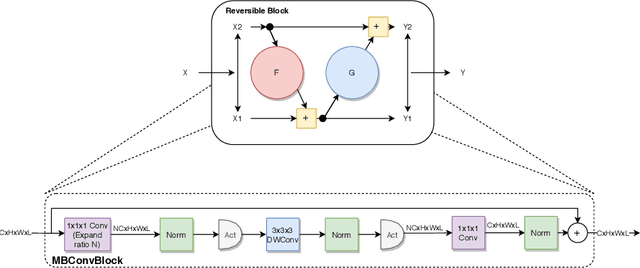
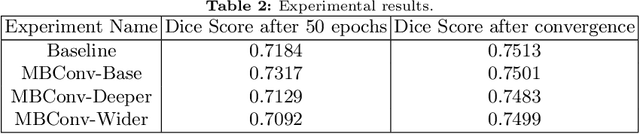
We propose combining memory saving techniques with traditional U-Net architectures to increase the complexity of the models on the Brain Tumor Segmentation (BraTS) challenge. The BraTS challenge consists of a 3D segmentation of a 240x240x155x4 input image into a set of tumor classes. Because of the large volume and need for 3D convolutional layers, this task is very memory intensive. To address this, prior approaches use smaller cropped images while constraining the model's depth and width. Our 3D U-Net uses a reversible version of the mobile inverted bottleneck block defined in MobileNetV2, MnasNet and the more recent EfficientNet architectures to save activation memory during training. Using reversible layers enables the model to recompute input activations given the outputs of that layer, saving memory by eliminating the need to store activations during the forward pass. The inverted residual bottleneck block uses lightweight depthwise separable convolutions to reduce computation by decomposing convolutions into a pointwise convolution and a depthwise convolution. Further, this block inverts traditional bottleneck blocks by placing an intermediate expansion layer between the input and output linear 1x1 convolution, reducing the total number of channels. Given a fixed memory budget, with these memory saving techniques, we are able to train image volumes up to 3x larger, models with 25% more depth, or models with up to 2x the number of channels than a corresponding non-reversible network.
* 11 pages, 5 figures, Published at MICCAI Brainles 2020
Stochastic Weight Averaging in Parallel: Large-Batch Training that Generalizes Well
Jan 07, 2020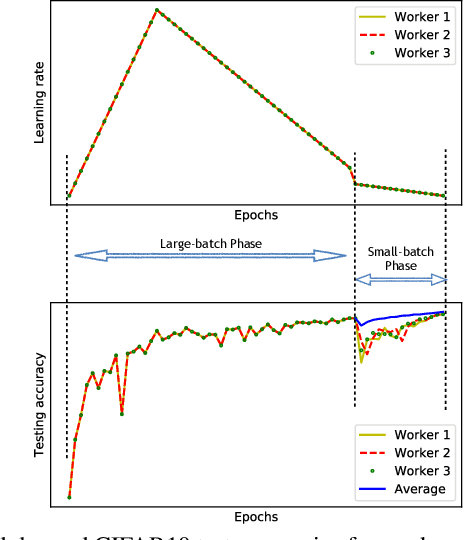

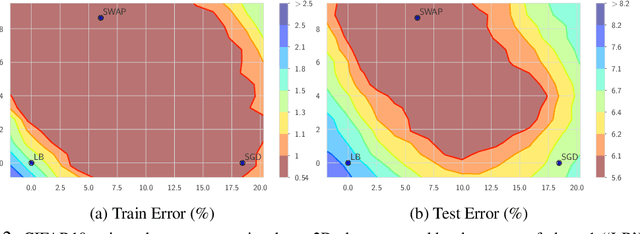

We propose Stochastic Weight Averaging in Parallel (SWAP), an algorithm to accelerate DNN training. Our algorithm uses large mini-batches to compute an approximate solution quickly and then refines it by averaging the weights of multiple models computed independently and in parallel. The resulting models generalize equally well as those trained with small mini-batches but are produced in a substantially shorter time. We demonstrate the reduction in training time and the good generalization performance of the resulting models on the computer vision datasets CIFAR10, CIFAR100, and ImageNet.
HD-CNN: Hierarchical Deep Convolutional Neural Network for Large Scale Visual Recognition
May 16, 2015

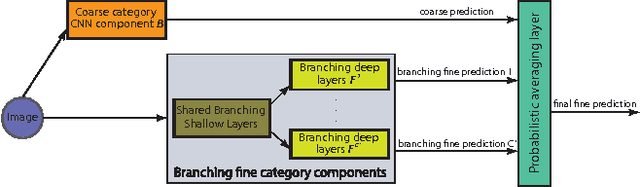
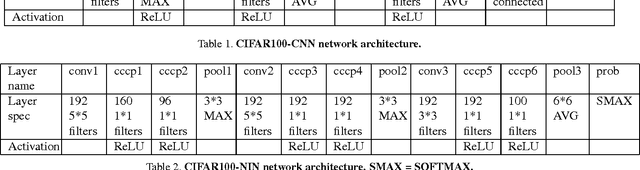
In image classification, visual separability between different object categories is highly uneven, and some categories are more difficult to distinguish than others. Such difficult categories demand more dedicated classifiers. However, existing deep convolutional neural networks (CNN) are trained as flat N-way classifiers, and few efforts have been made to leverage the hierarchical structure of categories. In this paper, we introduce hierarchical deep CNNs (HD-CNNs) by embedding deep CNNs into a category hierarchy. An HD-CNN separates easy classes using a coarse category classifier while distinguishing difficult classes using fine category classifiers. During HD-CNN training, component-wise pretraining is followed by global finetuning with a multinomial logistic loss regularized by a coarse category consistency term. In addition, conditional executions of fine category classifiers and layer parameter compression make HD-CNNs scalable for large-scale visual recognition. We achieve state-of-the-art results on both CIFAR100 and large-scale ImageNet 1000-class benchmark datasets. In our experiments, we build up three different HD-CNNs and they lower the top-1 error of the standard CNNs by 2.65%, 3.1% and 1.1%, respectively.
Hot Swapping for Online Adaptation of Optimization Hyperparameters
Apr 13, 2015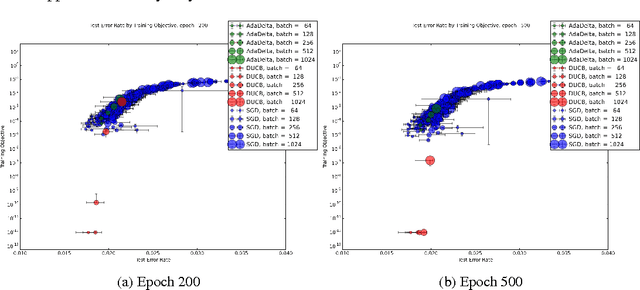
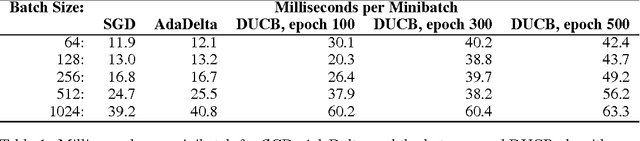
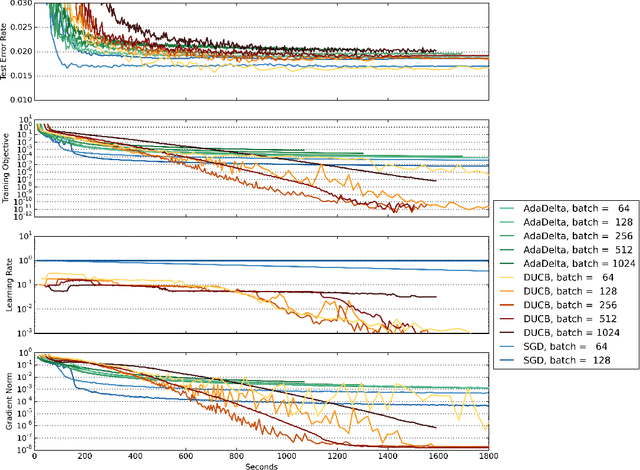

We describe a general framework for online adaptation of optimization hyperparameters by `hot swapping' their values during learning. We investigate this approach in the context of adaptive learning rate selection using an explore-exploit strategy from the multi-armed bandit literature. Experiments on a benchmark neural network show that the hot swapping approach leads to consistently better solutions compared to well-known alternatives such as AdaDelta and stochastic gradient with exhaustive hyperparameter search.
Fast Approximate Matching of Cell-Phone Videos for Robust Background Subtraction
Apr 22, 2014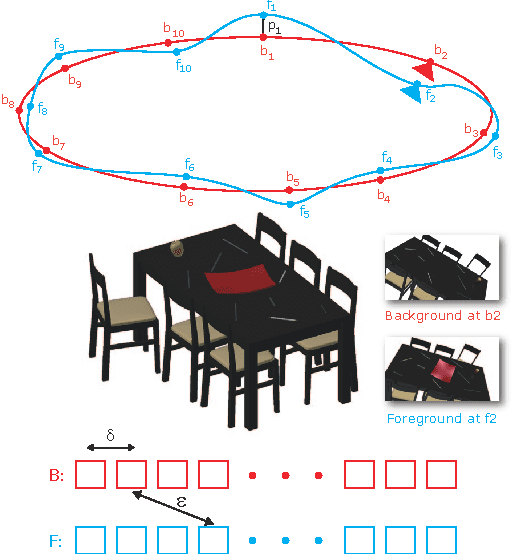
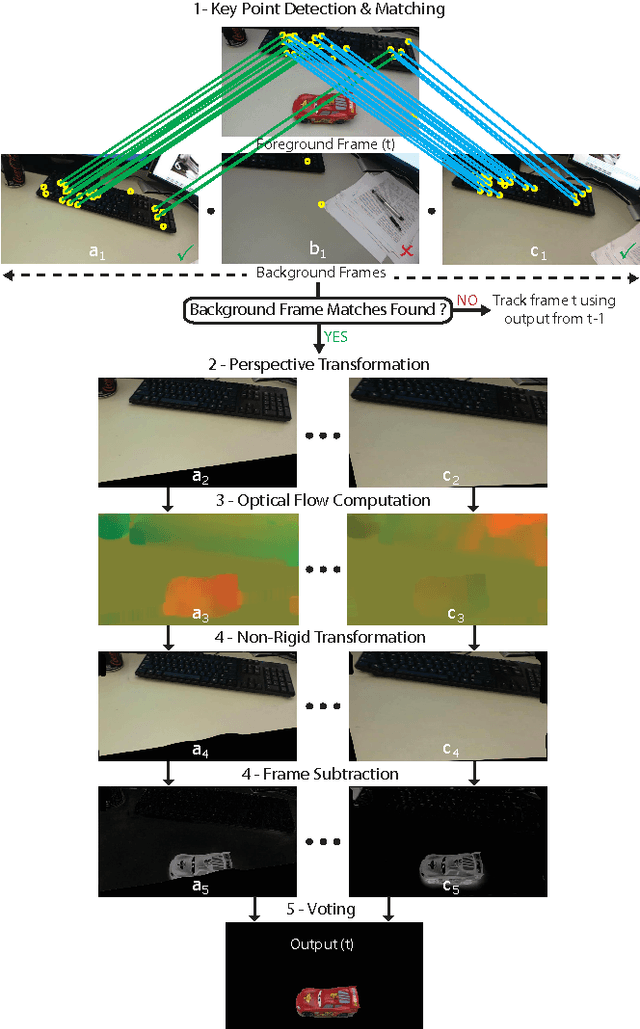
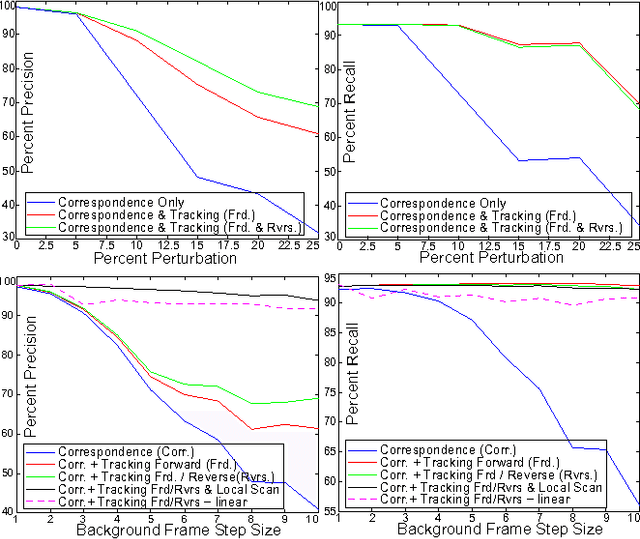
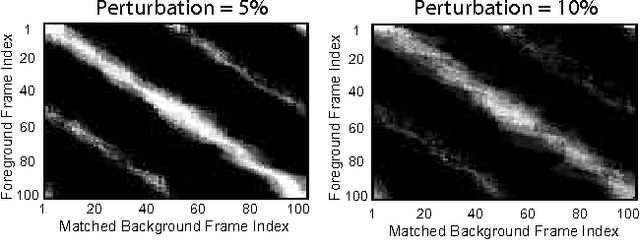
We identify a novel instance of the background subtraction problem that focuses on extracting near-field foreground objects captured using handheld cameras. Given two user-generated videos of a scene, one with and the other without the foreground object(s), our goal is to efficiently generate an output video with only the foreground object(s) present in it. We cast this challenge as a spatio-temporal frame matching problem, and propose an efficient solution for it that exploits the temporal smoothness of the video sequences. We present theoretical analyses for the error bounds of our approach, and validate our findings using a detailed set of simulation experiments. Finally, we present the results of our approach tested on multiple real videos captured using handheld cameras, and compare them to several alternate foreground extraction approaches.
Compact Random Feature Maps
Dec 17, 2013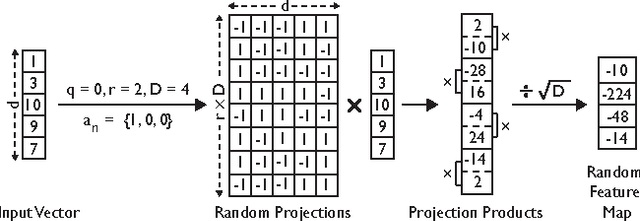
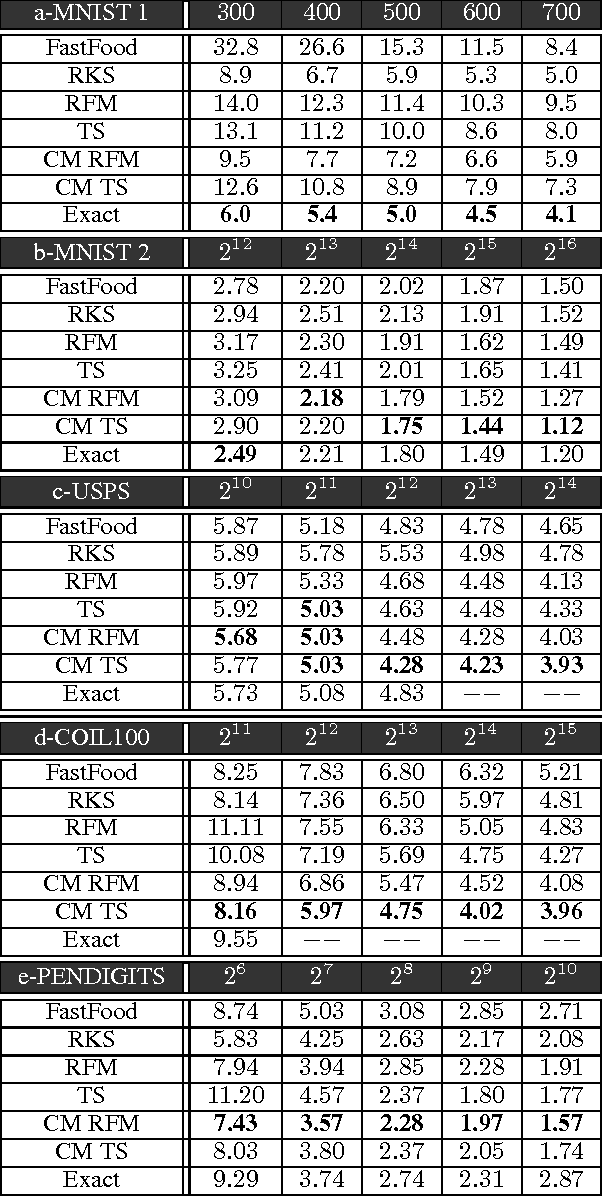
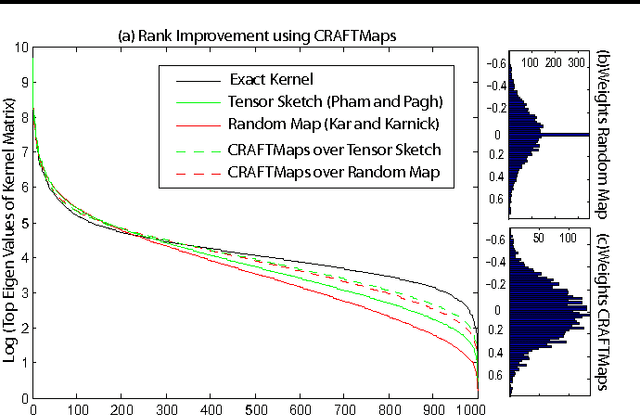
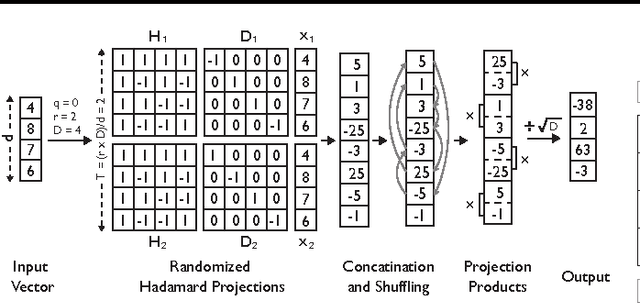
Kernel approximation using randomized feature maps has recently gained a lot of interest. In this work, we identify that previous approaches for polynomial kernel approximation create maps that are rank deficient, and therefore do not utilize the capacity of the projected feature space effectively. To address this challenge, we propose compact random feature maps (CRAFTMaps) to approximate polynomial kernels more concisely and accurately. We prove the error bounds of CRAFTMaps demonstrating their superior kernel reconstruction performance compared to the previous approximation schemes. We show how structured random matrices can be used to efficiently generate CRAFTMaps, and present a single-pass algorithm using CRAFTMaps to learn non-linear multi-class classifiers. We present experiments on multiple standard data-sets with performance competitive with state-of-the-art results.