 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFashion Apparel Detection: The Role of Deep Convolutional Neural Network and Pose-dependent Priors
Jan 24, 2016In this work, we propose and address a new computer vision task, which we call fashion item detection, where the aim is to detect various fashion items a person in the image is wearing or carrying. The types of fashion items we consider in this work include hat, glasses, bag, pants, shoes and so on. The detection of fashion items can be an important first step of various e-commerce applications for fashion industry. Our method is based on state-of-the-art object detection method pipeline which combines object proposal methods with a Deep Convolutional Neural Network. Since the locations of fashion items are in strong correlation with the locations of body joints positions, we incorporate contextual information from body poses in order to improve the detection performance. Through the experiments, we demonstrate the effectiveness of the proposed method.
HD-CNN: Hierarchical Deep Convolutional Neural Network for Large Scale Visual Recognition
May 16, 2015

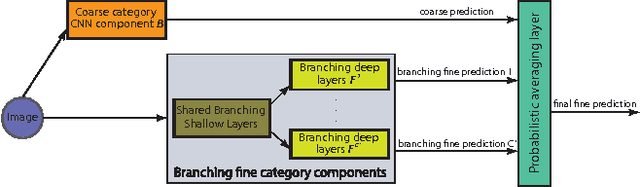
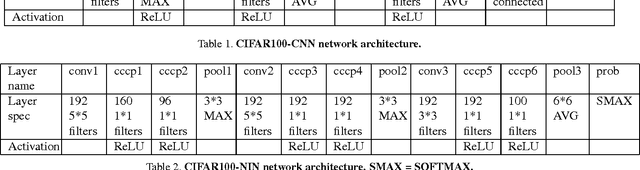
In image classification, visual separability between different object categories is highly uneven, and some categories are more difficult to distinguish than others. Such difficult categories demand more dedicated classifiers. However, existing deep convolutional neural networks (CNN) are trained as flat N-way classifiers, and few efforts have been made to leverage the hierarchical structure of categories. In this paper, we introduce hierarchical deep CNNs (HD-CNNs) by embedding deep CNNs into a category hierarchy. An HD-CNN separates easy classes using a coarse category classifier while distinguishing difficult classes using fine category classifiers. During HD-CNN training, component-wise pretraining is followed by global finetuning with a multinomial logistic loss regularized by a coarse category consistency term. In addition, conditional executions of fine category classifiers and layer parameter compression make HD-CNNs scalable for large-scale visual recognition. We achieve state-of-the-art results on both CIFAR100 and large-scale ImageNet 1000-class benchmark datasets. In our experiments, we build up three different HD-CNNs and they lower the top-1 error of the standard CNNs by 2.65%, 3.1% and 1.1%, respectively.
Im2Fit: Fast 3D Model Fitting and Anthropometrics using Single Consumer Depth Camera and Synthetic Data
Nov 19, 2014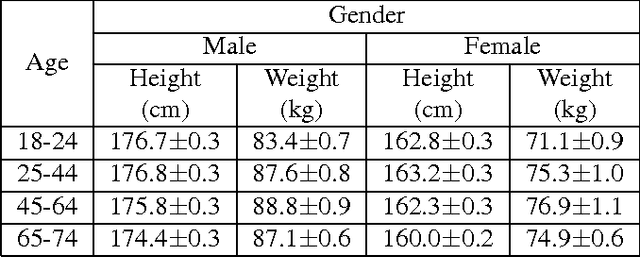
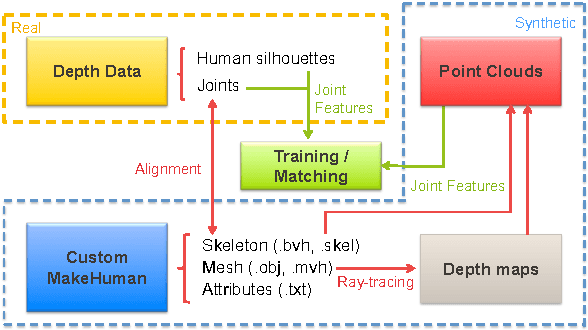
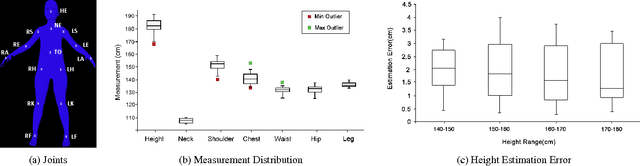
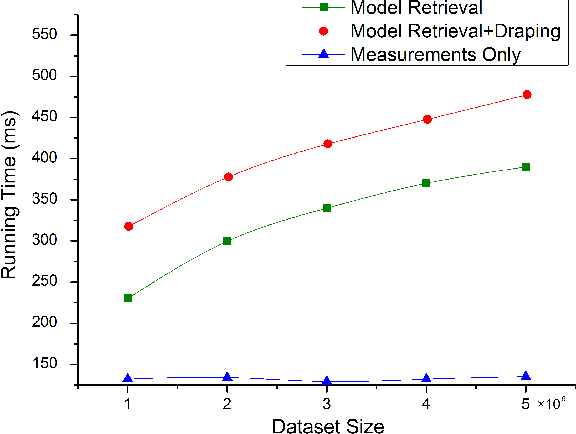
Recent advances in consumer depth sensors have created many opportunities for human body measurement and modeling. Estimation of 3D body shape is particularly useful for fashion e-commerce applications such as virtual try-on or fit personalization. In this paper, we propose a method for capturing accurate human body shape and anthropometrics from a single consumer grade depth sensor. We first generate a large dataset of synthetic 3D human body models using real-world body size distributions. Next, we estimate key body measurements from a single monocular depth image. We combine body measurement estimates with local geometry features around key joint positions to form a robust multi-dimensional feature vector. This allows us to conduct a fast nearest-neighbor search to every sample in the dataset and return the closest one. Compared to existing methods, our approach is able to predict accurate full body parameters from a partial view using measurement parameters learned from the synthetic dataset. Furthermore, our system is capable of generating 3D human mesh models in real-time, which is significantly faster than methods which attempt to model shape and pose deformations. To validate the efficiency and applicability of our system, we collected a dataset that contains frontal and back scans of 83 clothed people with ground truth height and weight. Experiments on real-world dataset show that the proposed method can achieve real-time performance with competing results achieving an average error of 1.9 cm in estimated measurements.
ConceptLearner: Discovering Visual Concepts from Weakly Labeled Image Collections
Nov 19, 2014

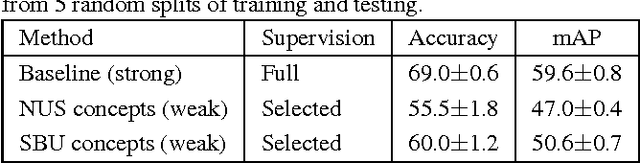

Discovering visual knowledge from weakly labeled data is crucial to scale up computer vision recognition system, since it is expensive to obtain fully labeled data for a large number of concept categories. In this paper, we propose ConceptLearner, which is a scalable approach to discover visual concepts from weakly labeled image collections. Thousands of visual concept detectors are learned automatically, without human in the loop for additional annotation. We show that these learned detectors could be applied to recognize concepts at image-level and to detect concepts at image region-level accurately. Under domain-specific supervision, we further evaluate the learned concepts for scene recognition on SUN database and for object detection on Pascal VOC 2007. ConceptLearner shows promising performance compared to fully supervised and weakly supervised methods.
Efficient Media Retrieval from Non-Cooperative Queries
Nov 19, 2014


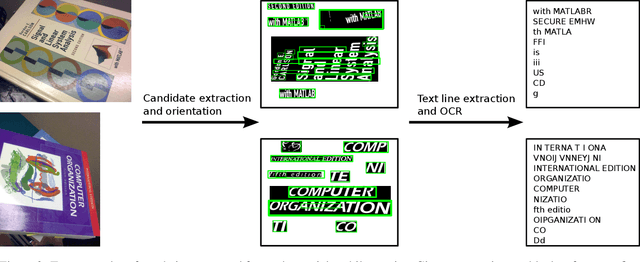
Text is ubiquitous in the artificial world and easily attainable when it comes to book title and author names. Using the images from the book cover set from the Stanford Mobile Visual Search dataset and additional book covers and metadata from openlibrary.org, we construct a large scale book cover retrieval dataset, complete with 100K distractor covers and title and author strings for each. Because our query images are poorly conditioned for clean text extraction, we propose a method for extracting a matching noisy and erroneous OCR readings and matching it against clean author and book title strings in a standard document look-up problem setup. Finally, we demonstrate how to use this text-matching as a feature in conjunction with popular retrieval features such as VLAD using a simple learning setup to achieve significant improvements in retrieval accuracy over that of either VLAD or the text alone.
Geometric VLAD for Large Scale Image Search
Mar 15, 2014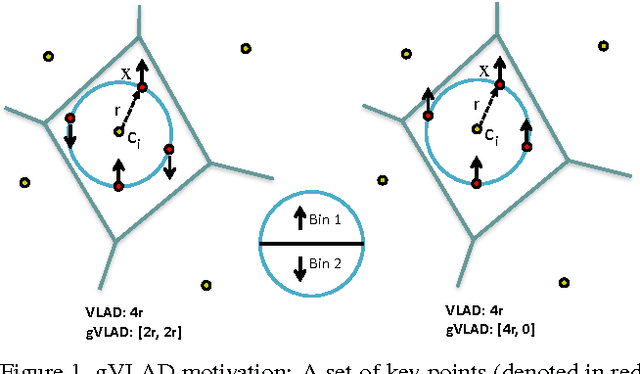


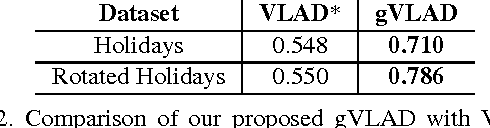
We present a novel compact image descriptor for large scale image search. Our proposed descriptor - Geometric VLAD (gVLAD) is an extension of VLAD (Vector of Locally Aggregated Descriptors) that incorporates weak geometry information into the VLAD framework. The proposed geometry cues are derived as a membership function over keypoint angles which contain evident and informative information but yet often discarded. A principled technique for learning the membership function by clustering angles is also presented. Further, to address the overhead of iterative codebook training over real-time datasets, a novel codebook adaptation strategy is outlined. Finally, we demonstrate the efficacy of proposed gVLAD based retrieval framework where we achieve more than 15% improvement in mAP over existing benchmarks.
Large Scale Visual Recommendations From Street Fashion Images
Jan 08, 2014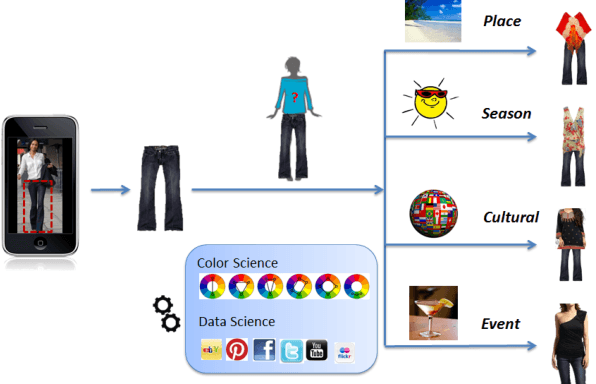
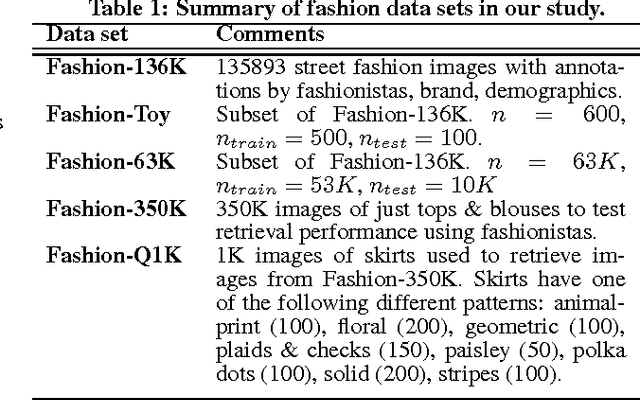

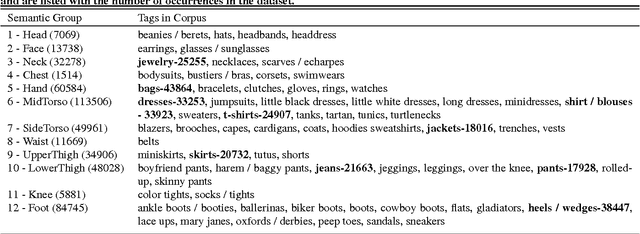
We describe a completely automated large scale visual recommendation system for fashion. Our focus is to efficiently harness the availability of large quantities of online fashion images and their rich meta-data. Specifically, we propose four data driven models in the form of Complementary Nearest Neighbor Consensus, Gaussian Mixture Models, Texture Agnostic Retrieval and Markov Chain LDA for solving this problem. We analyze relative merits and pitfalls of these algorithms through extensive experimentation on a large-scale data set and baseline them against existing ideas from color science. We also illustrate key fashion insights learned through these experiments and show how they can be employed to design better recommendation systems. Finally, we also outline a large-scale annotated data set of fashion images (Fashion-136K) that can be exploited for future vision research.