 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient Media Retrieval from Non-Cooperative Queries
Paper and Code
Nov 19, 2014


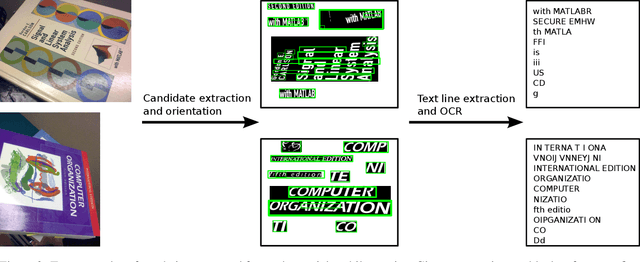
Text is ubiquitous in the artificial world and easily attainable when it comes to book title and author names. Using the images from the book cover set from the Stanford Mobile Visual Search dataset and additional book covers and metadata from openlibrary.org, we construct a large scale book cover retrieval dataset, complete with 100K distractor covers and title and author strings for each. Because our query images are poorly conditioned for clean text extraction, we propose a method for extracting a matching noisy and erroneous OCR readings and matching it against clean author and book title strings in a standard document look-up problem setup. Finally, we demonstrate how to use this text-matching as a feature in conjunction with popular retrieval features such as VLAD using a simple learning setup to achieve significant improvements in retrieval accuracy over that of either VLAD or the text alone.