 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMixup-CAM: Weakly-supervised Semantic Segmentation via Uncertainty Regularization
Aug 03, 2020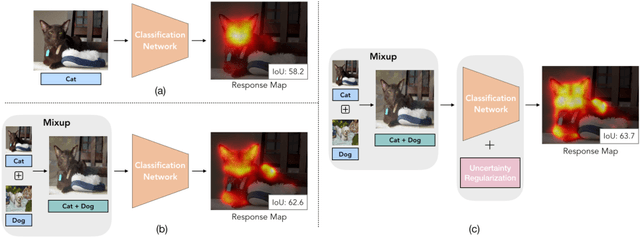
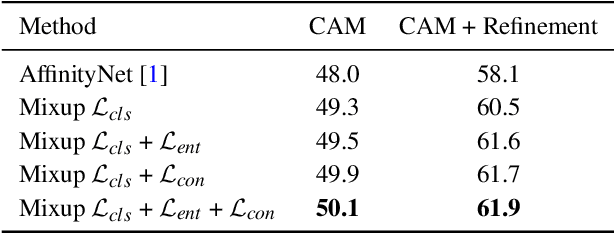
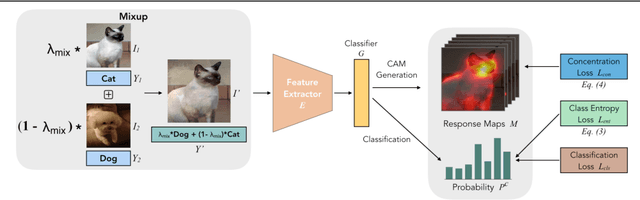
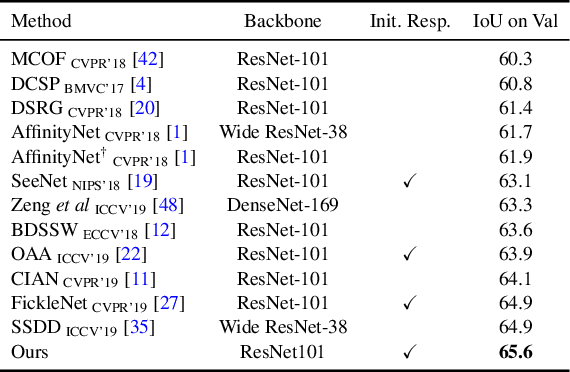
Obtaining object response maps is one important step to achieve weakly-supervised semantic segmentation using image-level labels. However, existing methods rely on the classification task, which could result in a response map only attending on discriminative object regions as the network does not need to see the entire object for optimizing the classification loss. To tackle this issue, we propose a principled and end-to-end train-able framework to allow the network to pay attention to other parts of the object, while producing a more complete and uniform response map. Specifically, we introduce the mixup data augmentation scheme into the classification network and design two uncertainty regularization terms to better interact with the mixup strategy. In experiments, we conduct extensive analysis to demonstrate the proposed method and show favorable performance against state-of-the-art approaches.
Weakly-Supervised Semantic Segmentation via Sub-category Exploration
Aug 03, 2020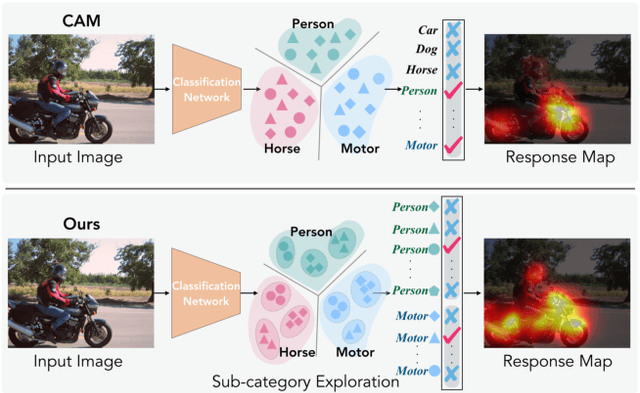
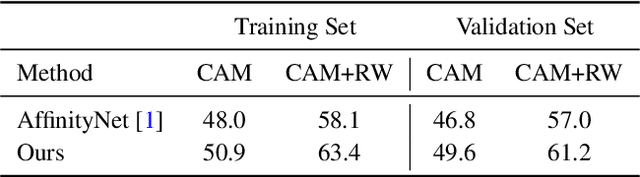
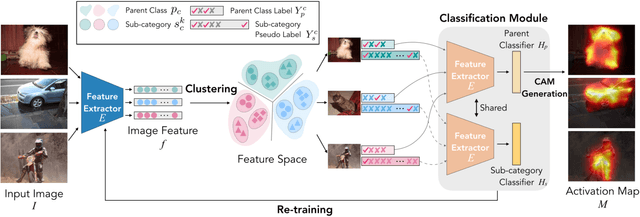
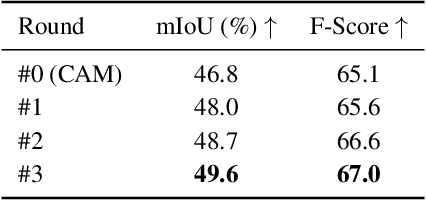
Existing weakly-supervised semantic segmentation methods using image-level annotations typically rely on initial responses to locate object regions. However, such response maps generated by the classification network usually focus on discriminative object parts, due to the fact that the network does not need the entire object for optimizing the objective function. To enforce the network to pay attention to other parts of an object, we propose a simple yet effective approach that introduces a self-supervised task by exploiting the sub-category information. Specifically, we perform clustering on image features to generate pseudo sub-categories labels within each annotated parent class, and construct a sub-category objective to assign the network to a more challenging task. By iteratively clustering image features, the training process does not limit itself to the most discriminative object parts, hence improving the quality of the response maps. We conduct extensive analysis to validate the proposed method and show that our approach performs favorably against the state-of-the-art approaches.
Adversarial Learning for Fine-grained Image Search
Jul 06, 2018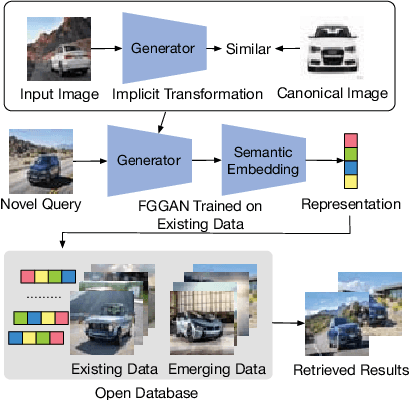



Fine-grained image search is still a challenging problem due to the difficulty in capturing subtle differences regardless of pose variations of objects from fine-grained categories. In practice, a dynamic inventory with new fine-grained categories adds another dimension to this challenge. In this work, we propose an end-to-end network, called FGGAN, that learns discriminative representations by implicitly learning a geometric transformation from multi-view images for fine-grained image search. We integrate a generative adversarial network (GAN) that can automatically handle complex view and pose variations by converting them to a canonical view without any predefined transformations. Moreover, in an open-set scenario, our network is able to better match images from unseen and unknown fine-grained categories. Extensive experiments on two public datasets and a newly collected dataset have demonstrated the outstanding robust performance of the proposed FGGAN in both closed-set and open-set scenarios, providing as much as 10% relative improvement compared to baselines.
Towards the Success Rate of One: Real-time Unconstrained Salient Object Detection
Aug 02, 2017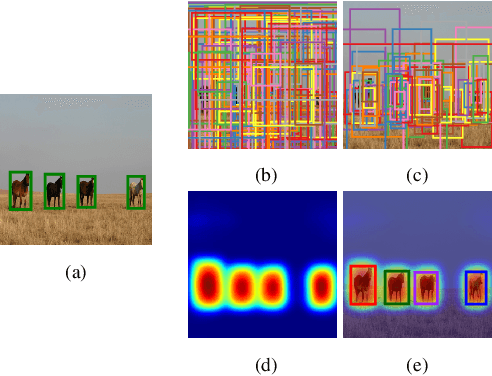
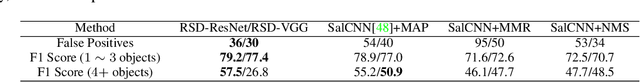


In this work, we propose an efficient and effective approach for unconstrained salient object detection in images using deep convolutional neural networks. Instead of generating thousands of candidate bounding boxes and refining them, our network directly learns to generate the saliency map containing the exact number of salient objects. During training, we convert the ground-truth rectangular boxes to Gaussian distributions that better capture the ROI regarding individual salient objects. During inference, the network predicts Gaussian distributions centered at salient objects with an appropriate covariance, from which bounding boxes are easily inferred. Notably, our network performs saliency map prediction without pixel-level annotations, salient object detection without object proposals, and salient object subitizing simultaneously, all in a single pass within a unified framework. Extensive experiments show that our approach outperforms existing methods on various datasets by a large margin, and achieves more than 100 fps with VGG16 network on a single GPU during inference.
Visual Search at eBay
Jul 07, 2017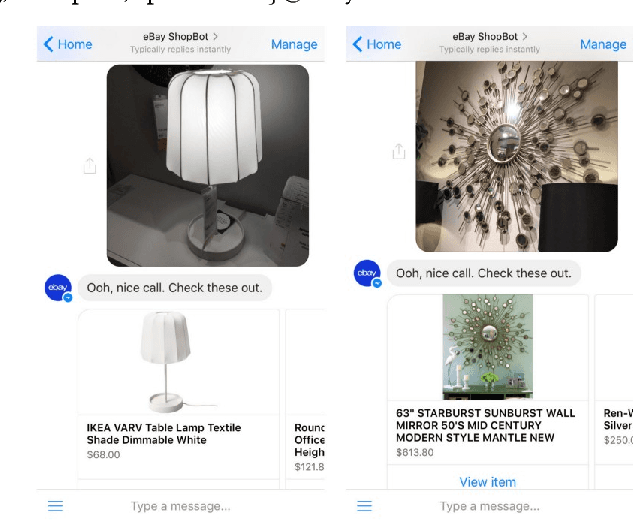



In this paper, we propose a novel end-to-end approach for scalable visual search infrastructure. We discuss the challenges we faced for a massive volatile inventory like at eBay and present our solution to overcome those. We harness the availability of large image collection of eBay listings and state-of-the-art deep learning techniques to perform visual search at scale. Supervised approach for optimized search limited to top predicted categories and also for compact binary signature are key to scale up without compromising accuracy and precision. Both use a common deep neural network requiring only a single forward inference. The system architecture is presented with in-depth discussions of its basic components and optimizations for a trade-off between search relevance and latency. This solution is currently deployed in a distributed cloud infrastructure and fuels visual search in eBay ShopBot and Close5. We show benchmark on ImageNet dataset on which our approach is faster and more accurate than several unsupervised baselines. We share our learnings with the hope that visual search becomes a first class citizen for all large scale search engines rather than an afterthought.
Automatic Layer Separation using Light Field Imaging
Jun 15, 2015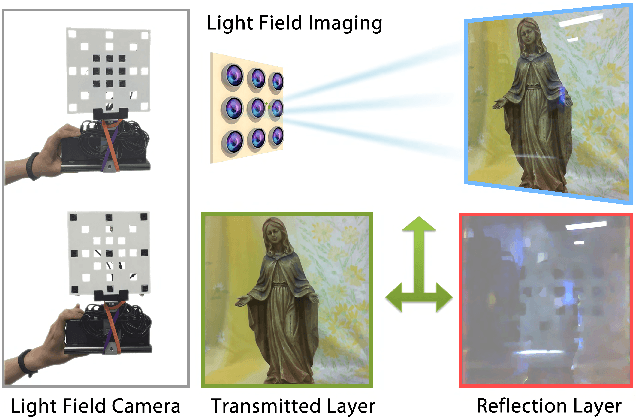
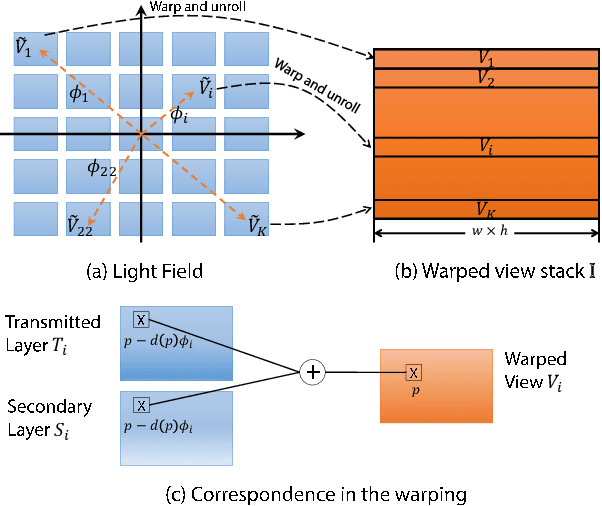
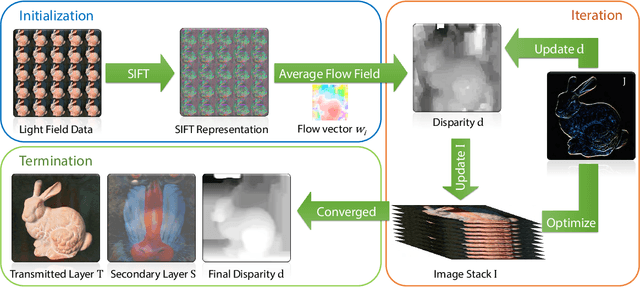

We propose a novel approach that jointly removes reflection or translucent layer from a scene and estimates scene depth. The input data are captured via light field imaging. The problem is couched as minimizing the rank of the transmitted scene layer via Robust Principle Component Analysis (RPCA). We also impose regularization based on piecewise smoothness, gradient sparsity, and layer independence to simultaneously recover 3D geometry of the transmitted layer. Experimental results on synthetic and real data show that our technique is robust and reliable, and can handle a broad range of layer separation problems.
Im2Fit: Fast 3D Model Fitting and Anthropometrics using Single Consumer Depth Camera and Synthetic Data
Nov 19, 2014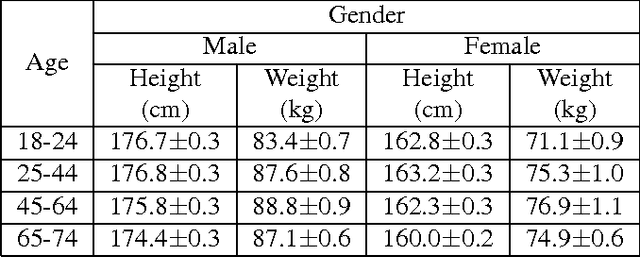
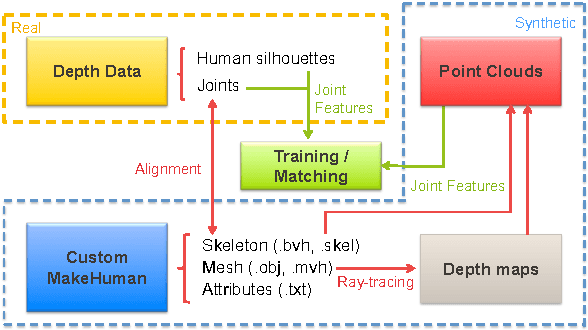
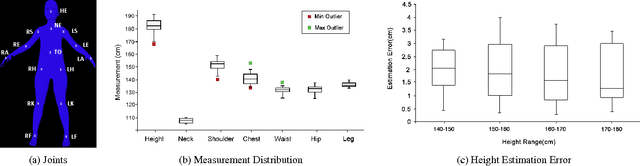
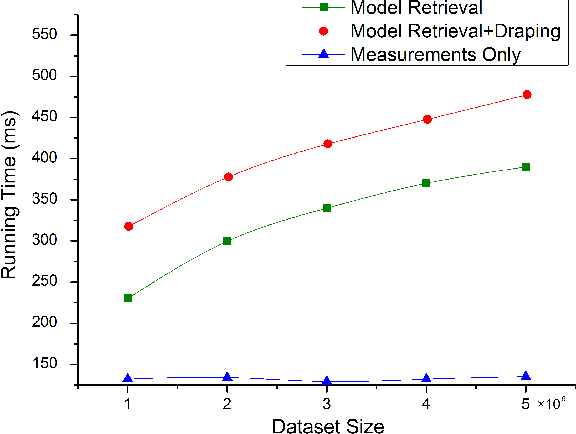
Recent advances in consumer depth sensors have created many opportunities for human body measurement and modeling. Estimation of 3D body shape is particularly useful for fashion e-commerce applications such as virtual try-on or fit personalization. In this paper, we propose a method for capturing accurate human body shape and anthropometrics from a single consumer grade depth sensor. We first generate a large dataset of synthetic 3D human body models using real-world body size distributions. Next, we estimate key body measurements from a single monocular depth image. We combine body measurement estimates with local geometry features around key joint positions to form a robust multi-dimensional feature vector. This allows us to conduct a fast nearest-neighbor search to every sample in the dataset and return the closest one. Compared to existing methods, our approach is able to predict accurate full body parameters from a partial view using measurement parameters learned from the synthetic dataset. Furthermore, our system is capable of generating 3D human mesh models in real-time, which is significantly faster than methods which attempt to model shape and pose deformations. To validate the efficiency and applicability of our system, we collected a dataset that contains frontal and back scans of 83 clothed people with ground truth height and weight. Experiments on real-world dataset show that the proposed method can achieve real-time performance with competing results achieving an average error of 1.9 cm in estimated measurements.